Functions
- Hex Racer
- Shift
- RAM
- Delay
- The Product of Nibbles
- Divide
- Stack
- The Lab
- Push and Pop
- Functions
- Расширение opcode инструкций
- Схема LEG
- Создание программы Ассемблер
- Готовый Ассемблер
- Следующий логический шаг
Hex Racer
tip
Разблокирует компонент Hexadecimal FF
Задача:
Преобразование шестнадцатеричной системы счисления в двоичную в условиях ограниченного времени.
Переключите биты на панели уровней так, чтобы их сумма равнялась шестнадцатеричному числу, указанному в вопросе.
1 hex-цифра = 4 бита (4 бита могут закодировать 16 разных значений)
[1-я цифра HEX][2-я цифра HEX] = 8 bit
[128, 64,32,16][8, 4, 2, 1] = 8 bit
HEX: 3F
BIN: 0011 1111
Decimal: 48+15=63
HEX: 1E
BIN: 0001 1110
Decimal: 16+14=30
| HEX | Десятичное | Бинарное |
|---|---|---|
| 0 | 0 | 0000 |
| 1 | 1 | 0001 |
| 2 | 2 | 0010 |
| 3 | 3 | 0011 |
| 4 | 4 | 0100 |
| 5 | 5 | 0101 |
| 6 | 6 | 0110 |
| 7 | 7 | 0111 |
| 8 | 8 | 1000 |
| 9 | 9 | 1001 |
| A | 10 | 1010 |
| B | 11 | 1011 |
| C | 12 | 1100 |
| D | 13 | 1101 |
| E | 14 | 1110 |
| F | 15 | 1111 |
При работе с большим количеством битов, двоичная система может стать сложной для чтения.
Пример 16 битного числа:
Binary: 1111111111111111
Decimal: 65535
Hexadecimal: FFFF
Shift
Задача:
Задача на этом уровне — сдвинуть первый входной сигнал влево на значение, заданное во втором входном сигнале. Значение во втором входном сигнале никогда не превысит 7.
Сдвиг значения на 1 влево означает перемещение всех битов байта влево на 1 позицию,а справа биты обнуляются.
Сдвиг влево на 1 позицию эквивалентен умножению числа на 2.
0011 0101 (53)
<< 1
────────
0110 1010 (53*2=106)
Сдвиг влево на 2 позиции эквивалентен умножению на 4, а сдвиг на 3 позиции эквивалентен умножению на 8
0000 0110 (6)
<< 3
────────
0011 0000 (6*8=48)
Переполнение типа (overflow)
1100 0000 (192)
<< 1
────────
1000 0000 (128)
384 mod 256 = 128
fn main() { let x: u8 = 0b1100_0000; // 192 let y = x << 1; println!("x = {:08b} ({})", x, x); println!("x<<1 = {:08b} ({})", y, y); }
Сдвиг на несколько разрядов можно реализовать с помощью сдвигающих регистров как результат нескольких одноразрядных сдвигов, но это занимает много времени. Быстрые сдвигатели перемещают слово сразу на несколько разрядов в соответствии с указанным значением сдвига.
Схемотехника быстрых сдвигателей насчитывает ряд вариантов, из которых основными являются сдвигатели, управляемые кодом "1 из N" (Barrel Shifters), и сдвигатели, управляемые двоичным кодом (Logarithmic Shifters).
Circuit Simulation: Barrel Shifters "1 из N"
Сдвигатель типа Barrel Shifter отличается высоким быстродействием, т. к. сигнал сдвига замыкает для каждой передачи входного бита на выходной буфер цепь только из одного ключа. Однако это справедливо, если управление ведется кодом "1 из N" и имеет малую разрядность.
Самый главный недостаток. Количество точек коммутации (переключателей) растёт как(число_бит) * (диапазон_сдвига)- экспоненциальный рост сложности (O(N²))
- Для 8 бит и сдвига 0-7: 8 * 8 = 64 точки коммутации
- Для 32 бит: 32 * 32 = 1024 точек коммутации
При больших величинах сдвигов, преимущество по технико-экономическим показателям обычно оказывается на стороне сдвигателя, непосредственно управляемого двоичными кодами и называемого логарифмическим.
Circuit Simulation: Logarithmic Shifter/Каскадный сдвигатель
Каждая ступень каскада делает фиксированный сдвиг на степень двойки (1, 2, 4...).
000данные выход как есть, без сдвигаxx11-й каскад сдвиг на 1 позицию влево, эквиваленно умножению на 2x1x2-й каскад сдвиг на 2 позиции влево, эквиваленно умножению на 41xx3-й каскад сдвиг на 4 позиции влево, эквиваленно умножению на 16
Пример: Чтобы сдвинуть на 5 позиций (101 в двоичном), включаются ступени «сдвиг на 4» (S2=1) и «сдвиг на 1» (S0=1). Композиция 4+1 даёт итоговый сдвиг на 5.
Помимо компонента, позволяющего сдвигать схему влево, мы также поручили стажёру создать компонент, позволяющий сдвигать схему вправо. Всё, что ему нужно было сделать, это создать зеркальную версию этой схемы.
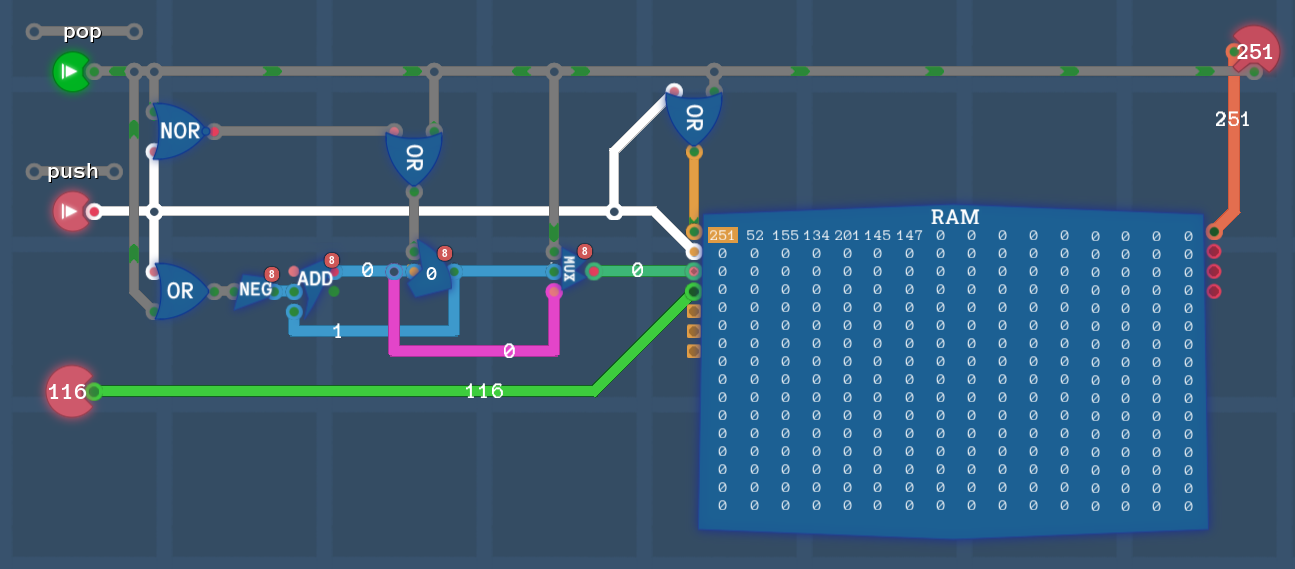
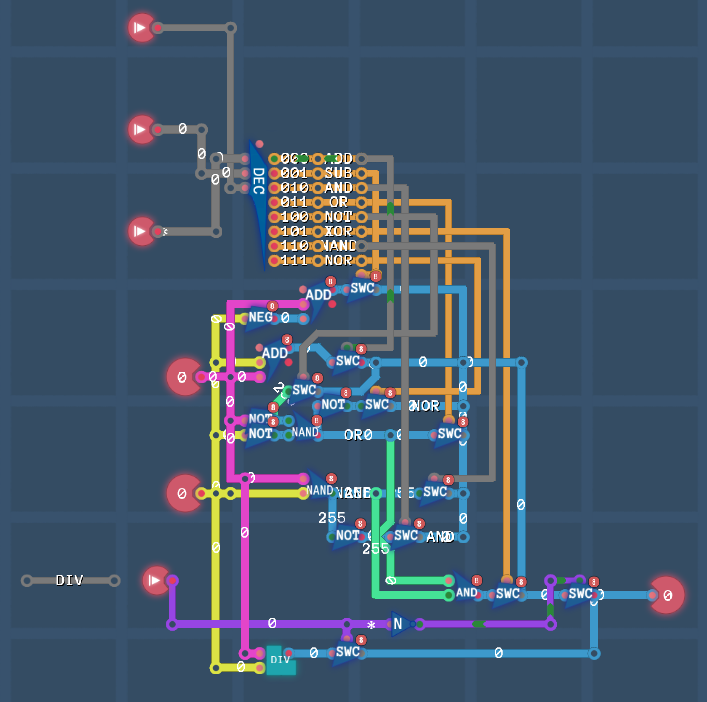
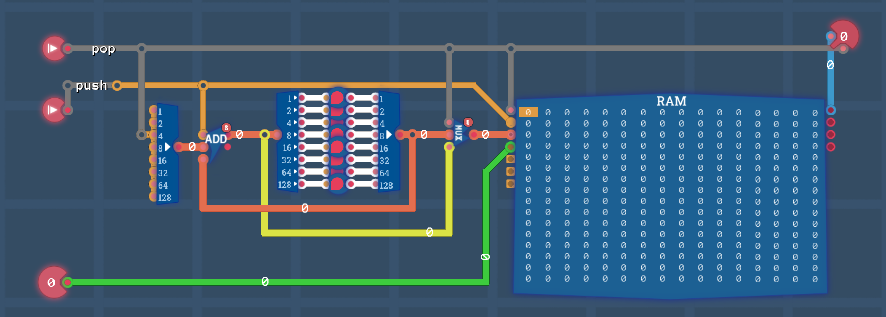
RAM
Задача:
Добавить блок ОЗУ, таким образом компьютер может оперировать дополнительными 256 байтами памяти.
Вам нужно найти как выбирать какие из 256 байтов будут использоваться. Выберите регистр и соедините его таким образом, чтобы его значение всегда было адресом ОЗУ. В будущем когда вы захотите вывести или сохранить что-либо в ОЗУ, вам нужно будет сначала скопировать адрес в этот регистр.
На этом уровне, во-первых скопируйте 32 раза значения со входа и сохраните их. После этого, выведите эти значения в таком же порядке в каком и сохранили. Вывод до сохранения всех входных значений приведёт к провалу уровня.
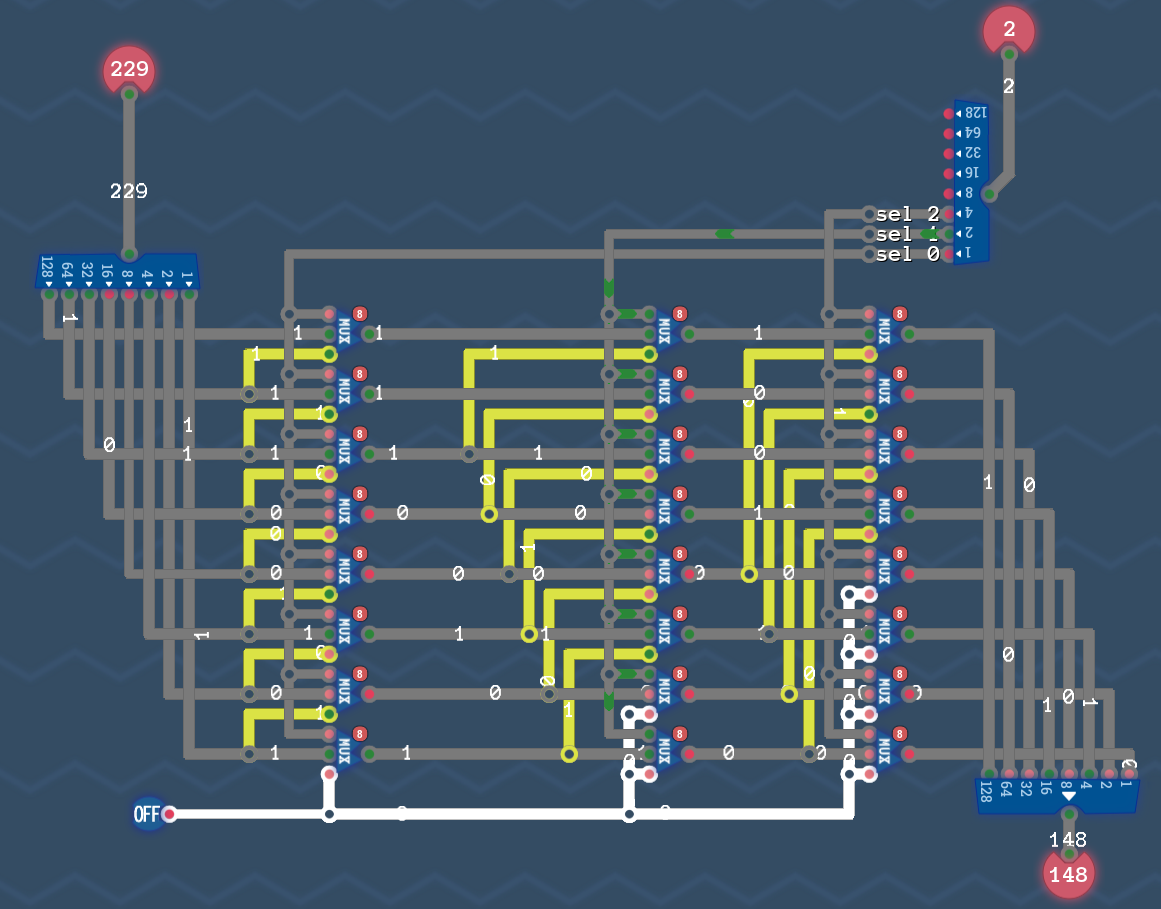
Обновим компонет MUX8Buf
- добавим возможность выбора 9-го источника данных (RAM)
- SP (Stack Pointer) выберем
REG 0для роли адреса RAM. Нам нужен регистр с постоянным режимом Load - Для выбора RAM в роли source (
Argument 1иArgument 2) или destination (Result address) выберем 4-й битxxxx1xxx(8)
Assembly Editor:
const jump_save_to_ram 4
const jump_output_ram 20
const jump_continue_output 24
const iterations 32
# reg_0 SP (Stack Pointer)
# set index RAM[reg_0], reg_0=0
0b11000000 #1 opcode ADD 0+0
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0b00000000 #4 destination reg_0
# jump_save_to_ram ROM[4] -------------------
# копировать с input в RAM
# (через ALU ADD с нулем)
0b01000000 #1 opcode ADD INPUT 0
0b00000111 #2 arg1 source INPUT
0b00000000 #3 arg2 source ImVal
0b00001000 #4 destination RAM
# increment index RAM[reg_0], reg_0+=1
0b10000000 #1 opcode ADD reg_0+1
0b00000001 #2 arg1 source ImVal
0b00000000 #3 arg2 source reg_0
0b00000000 #4 destination reg_0
# если reg_0 >= 32 то начать выводить
0b01100101 #1 cond reg_0 >= arg2
0b00000000 #2 arg1 source reg_0
iterations #3 arg2 source ImVal
jump_output_ram #4
# всегда прыгать
0b11100000 #1 cond arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_save_to_ram #4
# jump_output_ram ROM[20] -------------------
# сброс index RAM, reg_0=0
0b11000000 #1 opcode ADD 0+0
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0b00000000 #4 destination reg_0
# jump_continue_output ROM[24]
0b01000000 #1 opcode ADD RAM + 0
0b00001000 #2 arg1 source RAM
0b00000000 #3 arg2 source ImVal
0b00000111 #4 destination Output
# increment index RAM[reg_0], reg_0+=1
0b10000000 #1 opcode ADD reg_0+1
0b00000001 #2 arg1 source ImVal
0b00000000 #3 arg2 source reg_0
0b00000000 #4 destination reg_0
# всегда прыгать
0b11100000 #1 cond arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_continue_output
Delay
tip
Разблокирует компонент настраиваемой задержки Configurable delay
Задача:
У каждого компонента есть задержка.
Суммарная задержка схемы определяется самым медленным путём. Это значит что обычно лучше делать вещи параллельно.
На этом уровне вы должны показать что понимаете это понятие.
Задержка любого компонента выводится из задержки базовых элементов, задержка которых 2. Создайте цепь с задержкой 6 и стоимостью 5 базовых компонентов.
Для задержки в 6 тактов нужно все 3 компонента, а что бы количество элементов стало 5 мы просто парралельно добавим их в схему.
The Product of Nibbles
tip
Разблокирует компоненты Multipliers MUL 8/16/32/64 bit
Задача:
Умножение двух 4-х битных чисел дает 8-и битное число. Создайте схему, которая это делает.
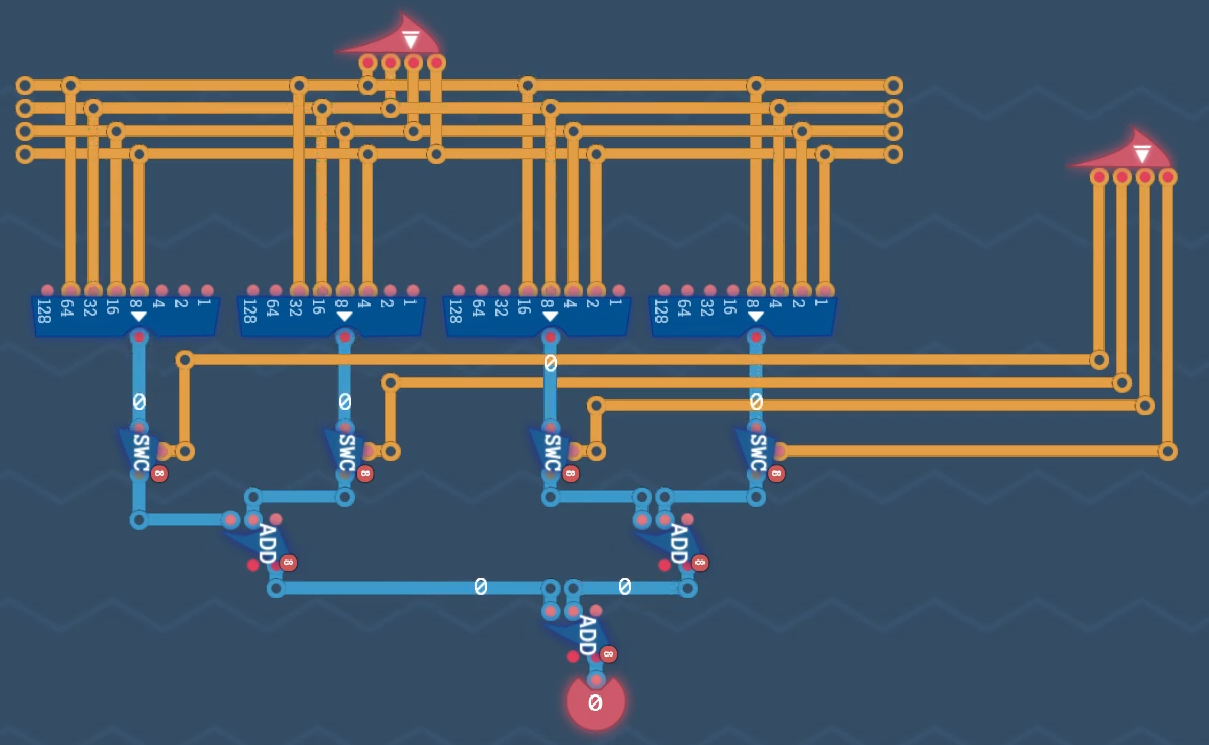
Два варианта параллельных умножителей за один такт:
- Горизонтальный умножитель состоит из 16 AND + 12 сумматоров. Все частичные произведения складываются одновременно по параллельной схеме. Схема физически представляет собой таблицу умножения.
- Вертикальный умножитель состоит из 16 AND + 4-х Logarithmic Shifter и 3-х 8-битных сумматоров. Есть возможность умножать 8-битные числа.
Circuit Simulation: Multiplier
Горизонтальный умножитель:
Вертикальный умножитель:
A - Множимое, Bi - Множитель
| Shift | A dec 7 | Bi dec 2 | Bi dec 3 | Bi dec 4 | Bi dec 7 | |
|---|---|---|---|---|---|---|
| xxxx0111 | xxxx0010 | xxxx0011 | xxxx0100 | xxxx0111 | ||
| << 0 | 00000111 | # 1x7=7 | xxxxxxx1 | xxxxxxx1 | ||
| << 1 | 00001110 | # 2x7=14 | xxxxxx1x | xxxxxx1x | xxxxxx1x | |
| << 2 | 00011100 | # 4x7=28 | xxxxx1xx | xxxxx1xx | ||
| << 3 | 00111000 | # 8x7=56 | ||||
| ADD 0+14+0+0=14 | ADD 7+14+0+0=21 | ADD 0+0+28+0=28 | ADD 7+14+28+0=49 |
The Product of Nibbles (youtube)
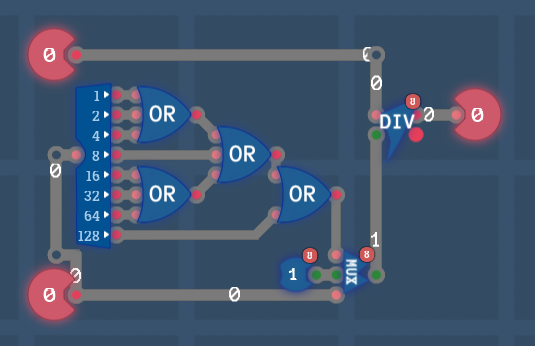
Divide
tip
Разблокирует компоненты Divide DIV 8/16/32/64 bit
Задача:
Целочисленно разделите два числа чтобы найти частное и остаток.
Рассмотрим дробь . Три умещается в семь аж два раза, при этом, один остается в остатке. В этом случае два принято называть ЧАСТНОЕ, а один ОСТАТКОМ ОТ ДЕЛЕНИЯ.
В этом задании вы получаете
Dividendчислитель (например семь) иDivisorзнаменатель (например три), и мы ожидаем на выходеQuotientЧАСТНОЕ (два) иRemainderОСТАТОК (один).
Деление - это цикл вычитания знаменателя с числителя пока числитель больше знаменателя, в остатке числителя остается остаток, а количество итераций цикла это частное.
Dividend = 7
Divisor = 3
Quotient = 0
while Dividend >= Divisor:
Dividend = Dividend - Divisor
Quotient = Quotient + 1
Remainder = Dividend
fn divide(mut a: u8, b: u8) -> (u8, u8) { let mut quotient: u8 = 0; // пока a >= b while a >= b { a = a - b; // SUB quotient += 1; // INC } let remainder = a; (quotient, remainder) } fn main() { let a = 1; let b = 2; let (q, r) = divide(a, b); println!("{} / {} = {}", a, b, q); println!("remainder = {}", r); }
Assembly Editor:
const jump_while 12
const jump_output 28
# 1. Dividend input to reg_1
0b01000000 #1 opcode ADD INPUT 0
0b00000111 #2 arg1 source INPUT
0b00000000 #3 arg2 source ImVal
0b00000001 #4 destination reg_1
# 2. Divisor input to reg_2
0b01000000 #1 opcode ADD INPUT 0
0b00000111 #2 arg1 source INPUT
0b00000000 #3 arg2 source ImVal
0b00000010 #4 destination reg_2
# 3. Quotient set 0 to reg_3
0b11000000 #1 opcode ADD 0 0
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0b00000011 #4 destination reg_3
# jump_while ROM[12]
# 4. IF_LESS
0b00100010 #1 opcode Cond IF_LESS
0b00000001 #2 arg1 source reg_1
0b00000010 #3 arg2 source reg_2
jump_output #4 destination
# 5. SUB reg_1 - reg_2 = reg_1
0b00000001 #1 opcode SUB
0b00000001 #2 arg1 source reg_1
0b00000010 #3 arg2 source reg_2
0b00000001 #4 destination reg_1
# 6. Quotient ADD 1
0b10000000 #1 opcode ADD 1 reg_3
0b00000001 #2 arg1 source ImVal
0b00000011 #3 arg2 source reg_3
0b00000011 #4 destination reg_3
# always jump
0b11100000 #1 cond arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_while #4 destination
# jump_output ROM[28]
# 7. Output Quotient
0b10000000 #1 opcode ADD 0 Quotient
0b00000000 #2 arg1 source ImVal
0b00000011 #3 arg2 source reg_3
0b00000111 #4 destination Output
# 8. Output Remainder
0b10000000 #1 opcode ADD 0 reg_1
0b00000000 #2 arg1 source ImVal
0b00000001 #3 arg2 source reg_1
0b00000111 #4 destination Output
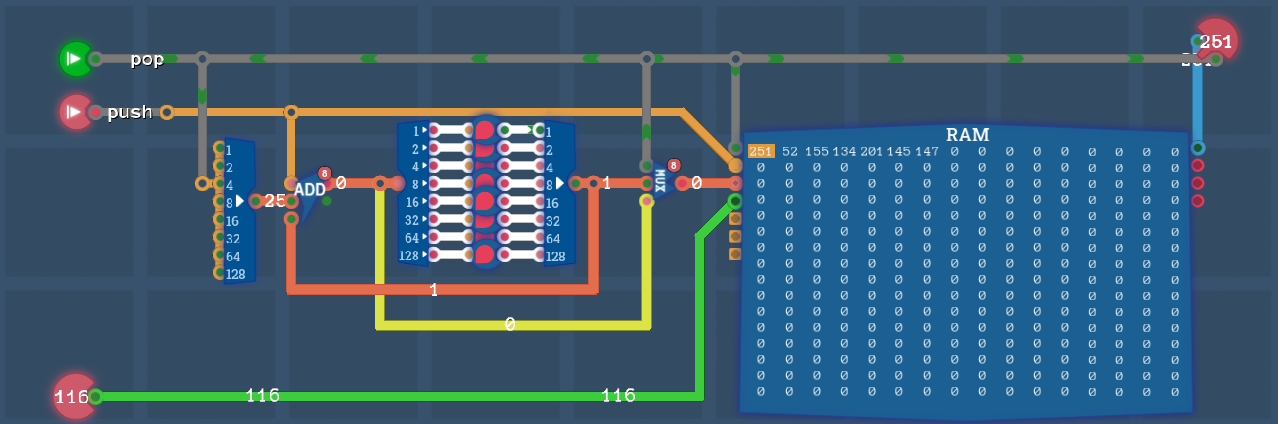
Stack
Задача:
В целях сокращения расходов было решено изменить систему очередей в государственных учреждениях, чтобы уменьшить поток посетителей. Вместо принципа «кто первый пришел, тот и обслуживается» мы вводим принцип «кто последний пришел, тот и обслуживается».
Представьте это как стопку (stack) пронумерованных бланков, где граждане либо кладут бланк сверху (это называется PUSH), либо чиновники берут бланк сверху стопки (это называется POP). Мы хотим, чтобы вы внедрили эту новую систему.
- Когда на входе POP сигнал HIGH вам следует извлечь данные из stack и вывести в output
- Когда на входе PUSH сигнал HIGH вам следует поместить в stack данные из input
Варианты менее избыточных реализаций Stack Registers (youtube) и Stack (youtube)
The Lab
Лаборатория — как и фабрика компонентов (но попасть в него можно с карты уровней) для экспериментов, а инструмент отладки. Лаборатория позволяет игроку сохранять программы для автоматической проверки их работоспособности.
Ключевое слово expect позволяет проверять внутреннее значение компонентов. Оно указывает адрес памяти для следующей инструкции. Принимает два аргумента:
- первый — индекс связанного компонента (индекс связи это по порядковый номер подключения, который вы устанавливаете в ручную при редактировании компонента PROGRAM (Link components))
- второй — его корректное значение Значение проверяется после каждой инструкции, поэтому, если значение снова изменится, необходимо указать новую строку в expect.
expect 2 4 # ожидаем что второй подключенный компонент будет иметь значение 4 на следующем такте
Ключевое слово set_input позволяет задавать пользовательские входные значения, что дает возможность тестировать инструкции, связанные с вводом данных.
set_input 123
Все подключенные компоненты проверяются на соответствие ожиданиям каждый такт. Ожидается что все подключенные компоненты будут иметь значение 0 на момент начала программы, ожидания для компонентов памяти меняются только если вы обновляете ожидания. Единственное исключение это счётчики, от которых ожидается что они будут увеличивать своё значение каждый такт.
failure
Инструкция set_input работает только в начале кода.
Assembly Editor:
set_input 45
expect 7 45 # expect Output 45
0b10000000 #1 opcode ADD 0 INPUT
0b00000000 #2 arg1 source ImVal
0b00000111 #3 arg2 source INPUT
0b00000111 #4 destination Output
expect 7 12 # expect Output 12
0b11000000 #1 opcode ADD 0 ImVal
0b00000110 #2 arg1 source ImVal
0b00000110 #3 arg2 source ImVal
0b00000111 #4 destination Output
expect 0 8 # expect reg_0 8
0b11000000 #1 opcode ADD 0 ImVal
0b00000100 #2 arg1 source ImVal
0b00000100 #3 arg2 source ImVal
0b00000000 #4 destination reg_0
Push and Pop
Задача:
На этом уровне вы должны добавить Stack в свою архитектуру компьютера и написать программу.
- Когда ввод равен 0, вы должны (
pop) извлечь значение из стека и вывести его.- Когда вход не равен 0, вы должны (
push) поместить это значение в стек.
Три варианта:
- Аппаратный стек, стек как внешний компонент, который физически отделен от основной шины данных.
- Это архитектура, похожая на Гарвардскую архитектуру (где память команд и память данных разделены)
- Достоинство: надежность - вы не сможете "залезть" случайно на адреса данных RAM и затереть их данными для стека
- Недостаток:
- Фиксированный лимит памяти для данных стека, иначе
Stack Overflow - Невозможность "произвольного доступа", видно только вершину стека, нельзя применять арифметику смещения по адресам
- Отсутствует возможность адресации через указатель, так как ячейки стека не имеют индексов в общем адресном пространстве памяти. Доступно только верхнее значение (вершина стека)
- Фиксированный лимит памяти для данных стека, иначе
- Разместить стек в RAM
- Чтобы RAM превратилась в стек, процессору нужен специальный регистр —
Stack Pointer(SP) (Указатель стека). - Начало адресов стека это последний индекс (255) в RAM и расти он будет к середине адресов RAM, т.е. уменьшаться
Descending Stack(убывающий стек)- Heap в начале адресов RAM, в Stack в конце
- Чтобы RAM превратилась в стек, процессору нужен специальный регистр —
- Гибрид, аппаратный стек для стека возвратов (Return Stack), и стек в RAM для стека данных (Data Stack)
- Достоинство: надежность - программа всё равно сможет корректно выполнить
RETи вернуться в основное меню, потому что адрес возврата лежит отдельно от данных
- Достоинство: надежность - программа всё равно сможет корректно выполнить
- и другие гибриды:
- Стек-кэш (Register Stack)
- "Теневой" стек (Shadow Stack)
Разместить стек в RAM. Descending Stack (убывающий стек)
Assembly Editor:
Схема не изменилась с уровня RAM.
# Когда ввод равен 0,
# pop значение из стека и вывести его
# Когда вход не равен 0,
# push это значение в стек
const start_while 4
const start_pop 28
# reg_4 - Stack Pointer (SP)
# reg_1 - INPUT
# reg_0 - RAM Pointer
# ------------------------------
# Stack Pointer (SP) reg_4
0b11000000 #1 ALU ADD 0 255
0b00000000 #2 arg1 source ImVal
0b11111111 #3 arg2 source 255
0b00000100 #4 destination reg_4
#-------------------------------
# start_while
# take INPUT
0b10000000 #1 ALU ADD 0 INPUT
0b00000000 #2 arg1 source ImVal
0b00000111 #3 arg2 source INPUT
0b00000001 #4 destination reg_1
# cond IF_EQUAL 0 == reg_1
0b10100000 #1 cond IF_EQUAL
0b00000000 #2 arg1 source ImVal
0b00000001 #3 arg2 source reg_1
start_pop #4 destination jump
# start push--------------------
# reg_0=reg_4
0b10000000 #1 ALU ADD 0+reg_4
0b00000000 #2 arg1 source ImVal
0b00000100 #3 arg2 source reg_4
0b00000000 #4 destination reg_0
# SP-1 push
0b01000001 #1 ALU SUB reg_4-1
0b00000100 #2 arg1 source reg_4
0b00000001 #3 arg2 source ImVal
0b00000100 #4 destination reg_4
# push INPUT значение в стек
0b10000000 #1 ADD 0 reg_1
0b00000000 #2 arg1 source ImVal
0b00000001 #3 arg2 source reg_1
0b00001000 #4 destination RAM
# always jump
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
start_while #4 destination
# start_pop------------------
# pop значение из стека и вывести его
# SP+1 pop
0b10000000 #1 ADD 1+reg_4
0b00000001 #2 arg1 source ImVal
0b00000100 #3 arg2 source reg_4
0b00000100 #4 destination reg_4
# reg_0=reg_4
0b10000000 #1 ADD 0+reg_4
0b00000000 #2 arg1 source ImVal
0b00000100 #3 arg2 source reg_4
0b00000000 #4 destination reg_0
# stack output
0b10000000 #1 ADD 0+reg_4
0b00000000 #2 arg1 source ImVal
0b00001000 #3 arg2 source RAM
0b00000111 #4 destination OUTPUT
# ------------------------
# always jump
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
start_while #4 destination
Использование opcod PUSH/POP с автоматическим SP в отдельном регистре.
Assembly Editor:
# Когда ввод равен 0,
# pop значение из стека и вывести его
# Когда вход не равен 0,
# push это значение в стек
# reg_1 - INPUT
#-----------------------------
label jump_while
# MOV INPUT to REG_1
0b00001100 #1 MOV
0b00000111 #2 INPUT
0 #3 unused
0b00000001 #4 REG_1
# cond IF_EQUAL 0 == reg_1
0b10100000 #1 cond IF_EQUAL
0 #2 arg1 source ImVal
0b00000001 #3 arg2 source reg_1
jump_pop #4 destination jump
# push INPUT значение в стек
0b00010111 #1 PUSH
0b00000001 #2 arg1 source reg_1
0 #3 arg2 unused
0b00001000 #4 destination RAM
# always jump
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_while #4 destination
label jump_pop
# pop значение из стека и вывести его
0b00010101 #1 POP
0 #2 arg1 Unused
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
# always jump
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0 #2 arg1 source ImVal
0 #3 arg2 source ImVal
jump_while #4 destination
Functions
Иногда полезно повторно использовать фрагмент кода.
Обычных команд JUMP (прыжков) достаточно для любой сложной логики (циклы while, ветвления if/else). Но это работает только с кодом который не предполагает повторное использование фрагментов кода, так как мы не знаем куда вернуться (вернее мы можем это сделать, но придется запоминать все адреса возврата в регистрах и потом проверять какой из них выбрать)
Мы называем эти фрагменты "функциями". Для реализации механизма повторного использования кода, можно прыгнуть из места вызова к началу нужной функции и прыгнуть обратно в место вызова в конце функции. Мы называем прыжок в начало функции - "calling" (CALL), а прыжок обратно из функции - "returning" (RET).
Но для того, чтобы этот фрагмент кода действительно можно было использовать повторно, оператор return должен позволять возвращаться в разные места в зависимости от того, откуда мы вызвали функцию.
Мы могли бы запомнить адрес, сохранив значение счётчика в регистре прежде чем прыгнуть в функцию и использовать это значение при возврате. Однако, если сделать это таким образом, функция не сможет вызывать другую функцию, поскольку это перезапишет обратный адрес.
Допустим функция А вызывает функцию В, которая вызывает функцию С. Когда мы хотим вернуться из С, нам нужен только адрес для В, а в В нам нужен только адрес для А. В целом, независимо от того, на какую функцию мы посмотрим и как они вложены, последний обратный адрес, который мы добавили всегда понадобится нам первым. Это в точности поведение стека.
Так же рекурсия физически невозможна без стека, так как адрес возврата будет постоянно перезаписываться в регистре.
Например функция возведения в квадрат fn square(a){return mul(a, a)} использует вложенный вызов функцию умножения fn mul(a, b){return a*b}:
address: asm code: # comment:
0b00000000 reg_1=7 # arg_1=7
0b00000001 reg_4=0b00000011 # return address
0b00000010 call 0b00000100 # square(7)
0b00000011 ... #
0b00000100 reg_5=reg_4 # fn square(a){return mul(a, a)}
# сохраним теущий адрес возврата в reg_5 так как мы знаем, что по нему будет jump в ф-ции mul
# и мы не хотим что бы с mul сразу переход на 0b00000011
# Но проблема в том, что регистров ограниченное количество, что бы сохранять каждый вложенные вызов в
# новый регистр.
# Невозможность рекурсии: Если функция должна вызвать саму себя, никакой reg_5 не поможет, так как
# при втором вызове он перезапишется тем же значением, что и в первый раз.
0b00000101 reg_4=0b00001000 # return address
0b00000110 reg_2=reg_1 # arg_2=arg_1
0b00000111 call 0b00001010 # mul(7, 7)
0b00001000 jump reg_5 # return address, вернемся в 0b00000011
0b00001001 ... #
0b00001010 reg_3=reg_1*reg_2# fn mul(a, b){return a*b}
0b00001011 jump reg_4 # return address
important
Команда CALL увеличивает стек адресом возврата, поэтому следует помнить о переполнении стека (Stack Overflow) если не вызывать после команду RET, которая уменьшает стек. Для простых переходов (прыжков) JUMP следует использовать прямое указание адреса, что неувеличивает стек адресов возврата.
Задача:
На этом уровне вам поручено реализовать вызовы функций и возвраты с помощью инструкций call и ret.
Обратите внимание, что при возврате из функции следует переходить к адресу, который был указан ПОСЛЕ инструкции call, иначе возникнет бесконечный цикл. (нужно что бы после счетчика PC стоял инкремент и это уже значение сохранять в стек возвратов)
Инструкция по вызову должна содержать следующее:
- Добавьте ширину инструкции к значению счетчика и поместите его в стек.
- Перейти (jump) к адресу функции
Инструкция ret должна выполнять следующие действия:
- Извлеките (pop) адрес возврата из стека и перейдите (jump) к нему.
Вы можете передавать информацию в функцию и из функции, сохраняя данные в регистры обычным способом. Также имейте в виду, какие регистры функция будет перезаписывать, прежде чем вызывать её.
info
Раз мы уже реализовали стек в RAM, мы могли бы хранить адреса возврата там. Но тогда команды PUSH (для чисел) и CALL (для адресов) будут "драться" за одну и ту же память.
Гибрид (аппаратный стек для адресов) нужен просто для того, чтобы вы не думали об адресах возврата вообще. Они на уровне железа сохраняются в отдельной памяти, и вам не нужно тратить такты на вычисление адреса в RAM при каждой команде CALL или RET. Весь ваш стек в RAM остается только для ваших непосредственных данных - аргументов функций, локальных переменных, массивов и расчетов...
Поставим компонент Stack специально для инструкций CALL / RET. А для вычислений и деления использовать SP (Stack Pointer) и RAM.
Нам нужно добавить в схему компонент Stack, но подключить его не к общей шине данных, а к шине адреса и управляющим сигналам CALL / RET
- Вход данных аппаратного стека: Подключим к выходу Program Counter (PC) (обычно через инкрементатор разрядности инструкции, чтобы сохранить адрес следующей инструкции, а не текущей).
- Выход данных аппаратного стека: Подключим ко входу Jump Address нашего PC
- Команда CALL (сигнал): Должна одновременно активировать Push на аппаратном стеке и Jump на PC.
- Схватить текущий номер строки из
Program Counter(например, 8). - Прибавить к нему 4 (адрес следующей команды, т.е. 12).
- Сохранить это число внутри себя (нажать
Push). - После этого процессор прыгает на код деления.
- Схватить текущий номер строки из
- Команда RET (сигнал): Должна активировать Pop на аппаратном стеке и подать это значение на вход PC для прыжка.
- Выдать последнее сохраненное число (нажать
Pop). - Отправить это число прямо в
Program Counter. - Процессор мгновенно оказывается на строке 12.
- Выдать последнее сохраненное число (нажать
Нам доступен xxxx1xxx (8) и xxx1xxxx бит (16) в opcode (1-й байт инструкции)
- команда CALL
xxxx1xxx(8)CALL <address> — Процессор сам делает Stack.push(PC + 4) и PC = <address>
- команда RET
xxx1xxxx(16)RET — Процессор делает PC = Stack.pop()
С 4-байтовыми инструкциями адрес возврата меняется. Если наша инструкция занимает 4 ячейки памяти, то следующая команда начинается через 4 адреса.
Инкрементатор перед стеком должен делать не +1, а +4. Поскольку каждая наша инструкция занимает 4 байта, адрес "возврата" всегда равен текущий адрес + 4. Нужно: PC -> Сумматор (+4) -> Stack Input
Текущая архитектура ISA процессора LEG:
[первый байт][второй байт ][трейтий байт ][четвертый байт ]
[что делать ][источник 1 ][источник 2 ][куда девать результат]
[Opcode 8bit][Argument 1 8bit][Argument 2 8bit][Result address 8bit ]
Opcode 8bit:
биты xxxxx111 режима ALU, результат его работы в общую шину:
(По умолчанию все команды для ALU. Source данные всегда идут через ALU)
0: ALU xxxxxxx1 #1
1: ALU xxxxxx1x #2
2: ALU xxxxx1xx #4
бит режима CALL, данные из Result address (четвертый байт ISA инс.) в общую шину для PC:
3: CALL 00001000 #8 идентификатор режима
бит режима RET, данные из Result address (четвертый байт ISA инс.) в общую шину для PC:
4: RET 00010000 #16 идентификатор режима
биты xx1xx111 режима COND, данные из Result address (четвертый байт ISA инс.) в общую шину для PC.
0: COND xxxxxxx1 #1
1: COND xxxxxx1x #2
2: COND xxxxx1xx #4
5: COND xx1xxxxx #32 идентификатор режима, если бит установлен
биты 11xxxxxx режима Immediate values:
6: x1xxxxxx #64 выбор в роли Immediate values Argument 2 (трейтий байт ISA инс.) идентификатор режима, если бит установлен
7: 1xxxxxxx #128 выбор в роли Immediate values Argument 1 (второй байт ISA инс.) идентификатор режима, если бит установлен
Argument 1/Argument 2/Result address 8bit:
биты xxxx1111 кодируют адрес исчтоника/пунтка назначения:
0: #1 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
1: #2 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
2: #4 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
4: #8 xxxx1xxx только для RAM
Результат декодирования трех младших бит xxxxx111:
0: Register 0
1: Register 1
2: Register 2
3: Register 3
4: Register 4
5: Register 5
6: Counter (PC)
7: Input (для Argument 1 и Argument 2) или Output (для Result address)
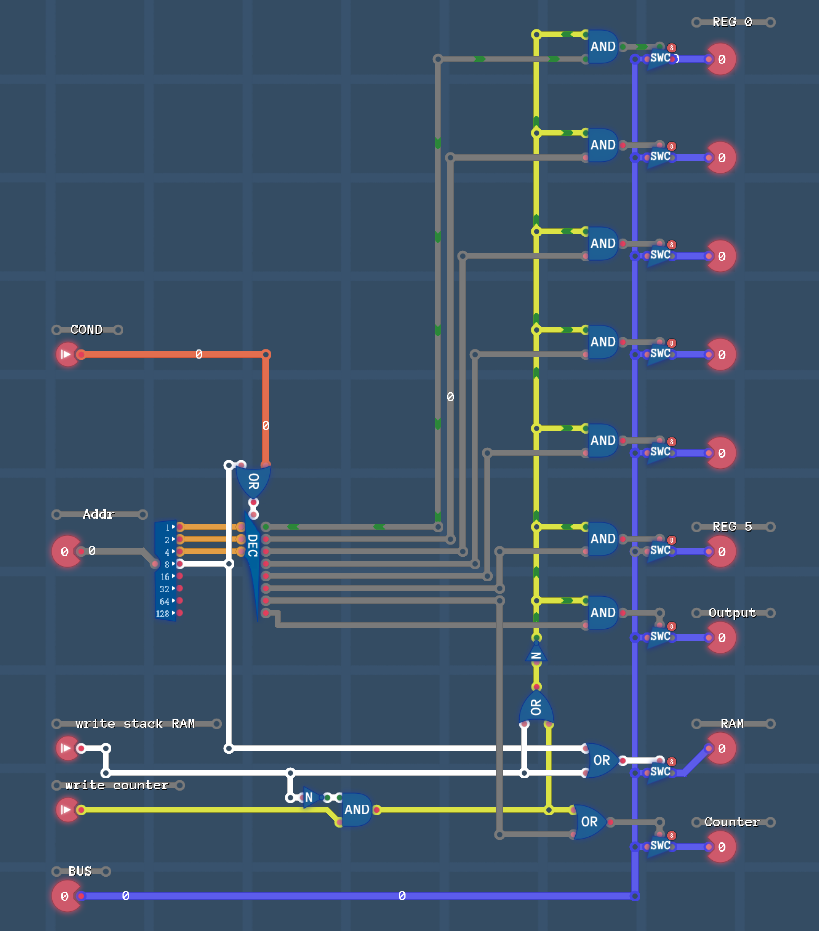
И мы выбрали REG_0 для роли Stack Pointer (SP) (Указатель стека) для RAM (ОЗУ).
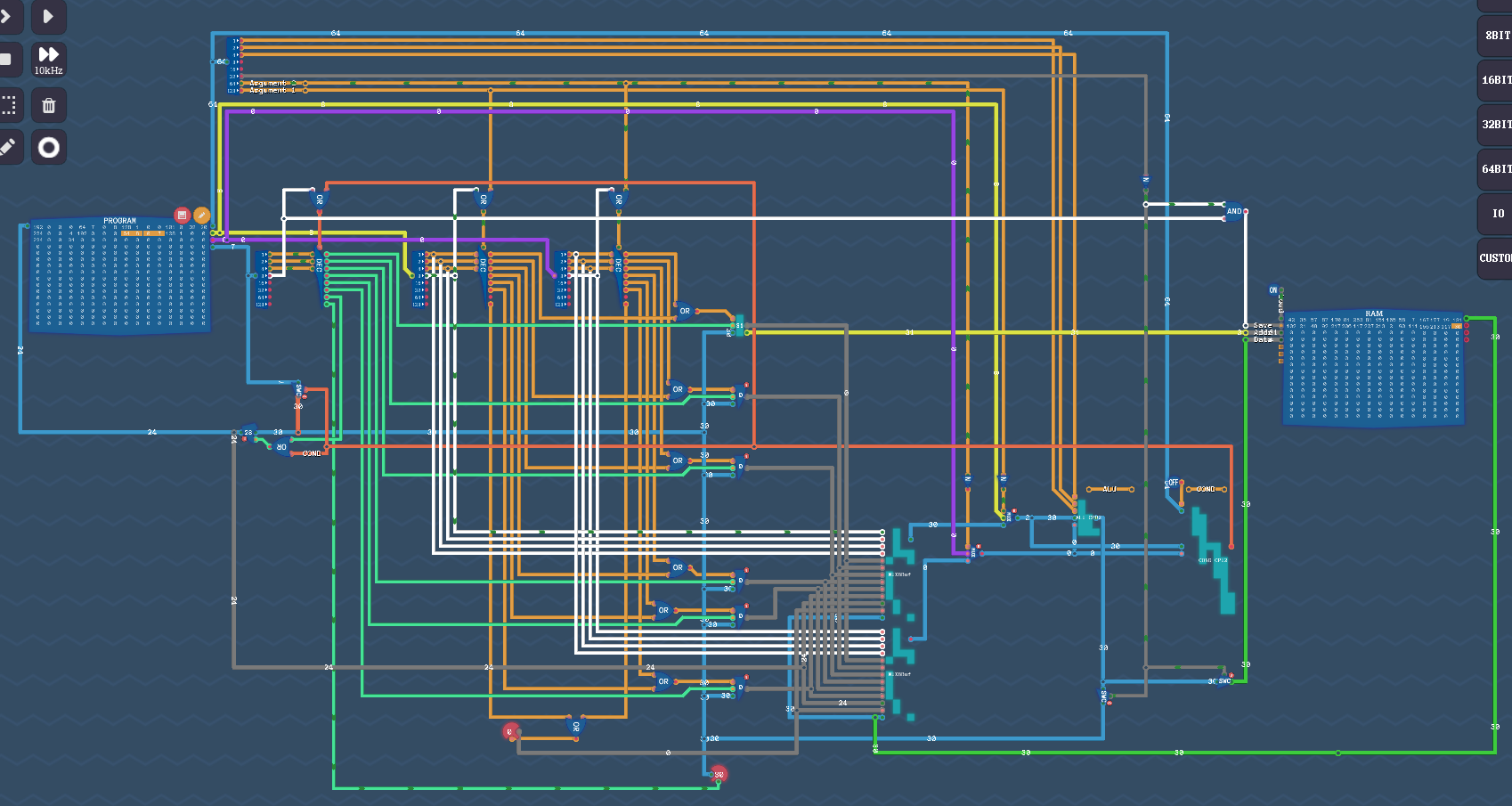
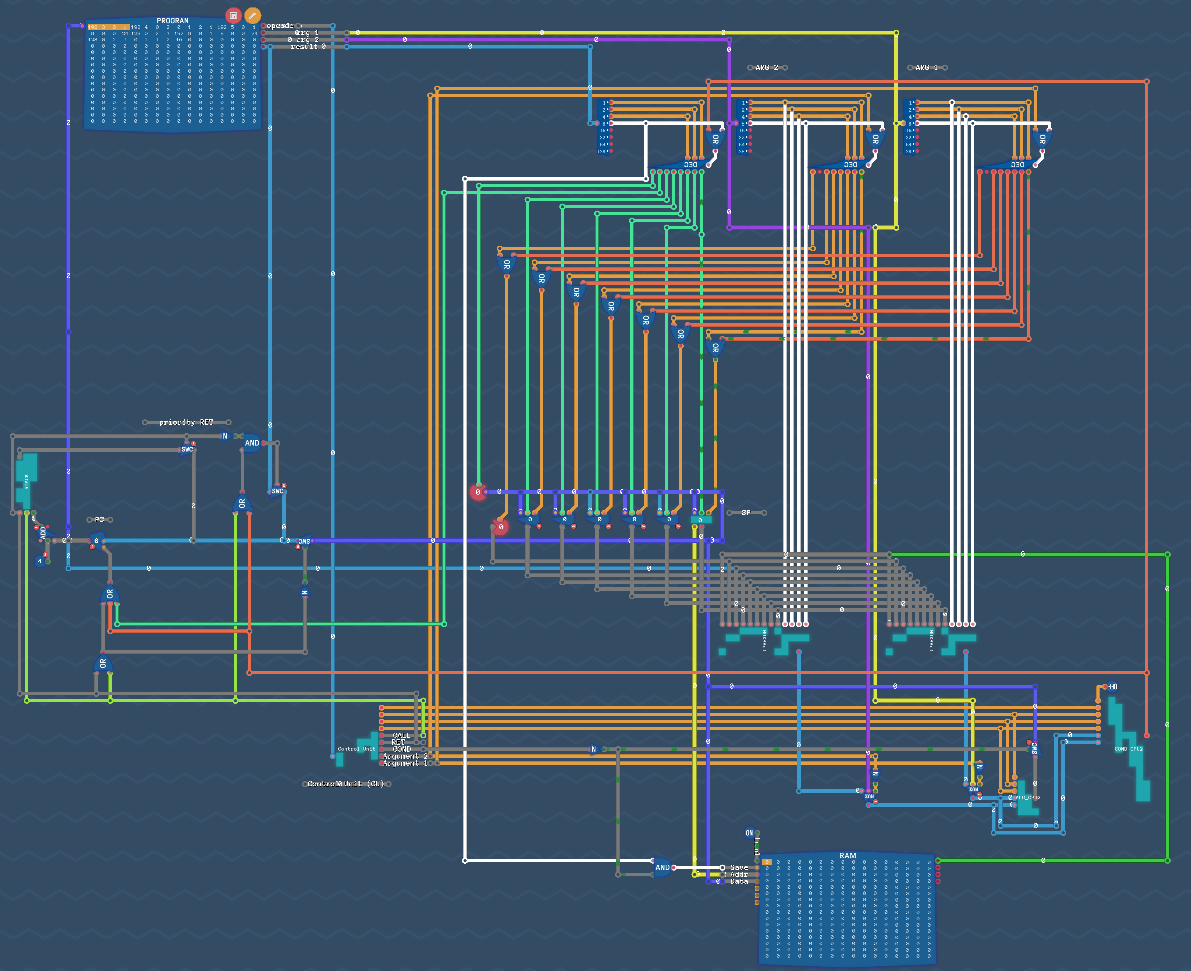
Схема уровня Functions:
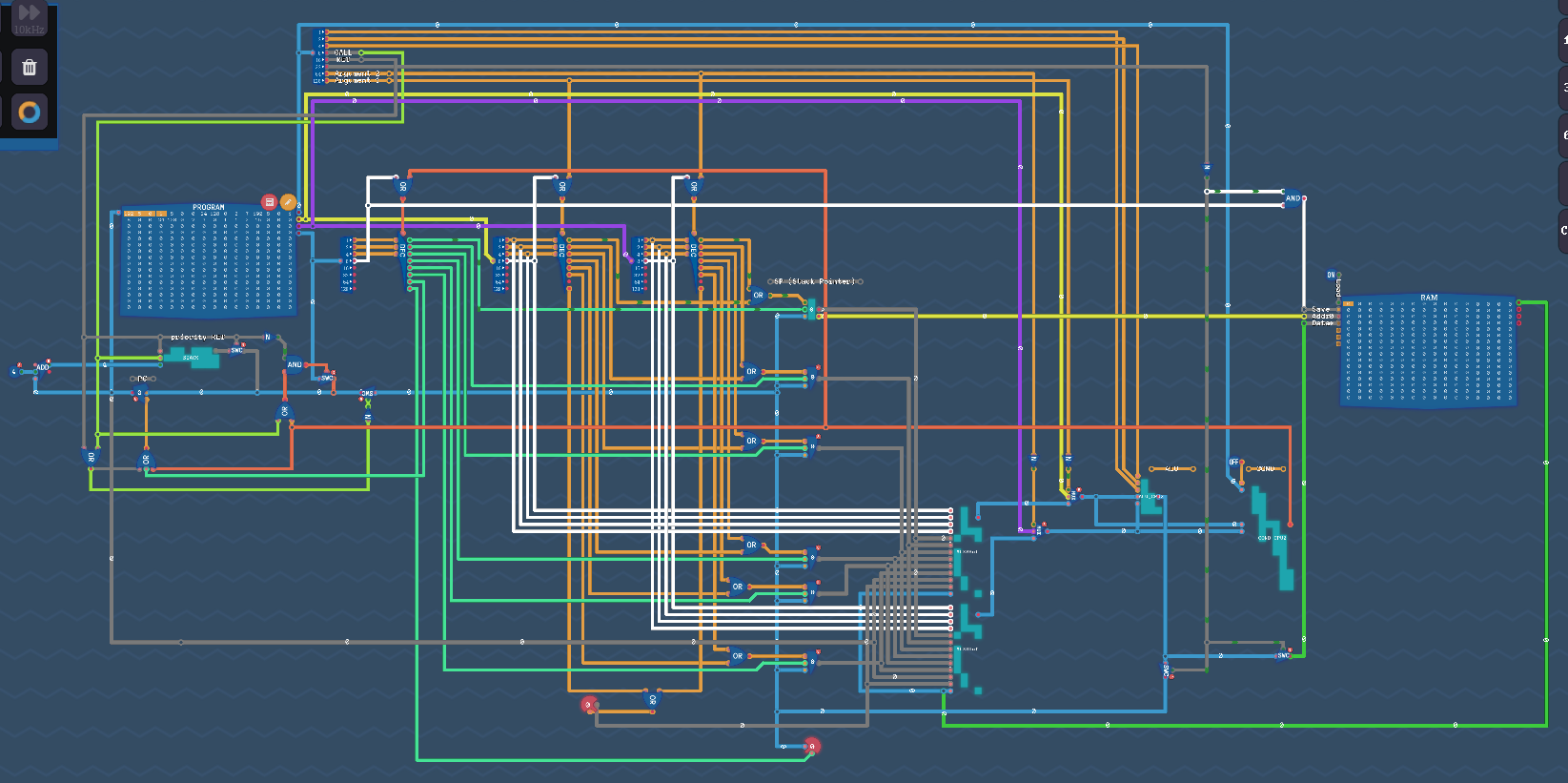
(p.s. есть ошибка в схеме, в режиме условий COND мы должны перекрыть общую шину на пути к счетчику и открыть шину только для данных Result address)
Assembly Editor:
Проверка механизма CALL и RET. Реализуем функцию удвоения числа и вызовем ее два раза.
# reg_4 - Stack Pointer (SP)
# reg_0 - RAM Pointer
# reg_1 - arg_1
# reg_2 - result
# CALL opcode `xxxx1xxx` (8)
# RET opcode `xxx1xxxx` (16)
const jump_fn_double 24
const CALL 0b00001000
const RET 0b00010000
# first call fn ----------------------
# set arg_1=5
0b11000000 #1 opcode ADD 5+0
0b00000101 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0b00000001 #4 destination reg_1
# CALL fn double
CALL #1 opcode CALL
0b00000000 #2 arg1 source unused
0b00000000 #3 arg2 source unused
jump_fn_double #4 destination PC
# output result
0b10000000 #1 opcode ADD 0+reg_2
0b00000000 #2 arg1 source ImVal
0b00000010 #3 arg2 source reg_2
0b00000111 #4 destination OUTPUT
# ------------------------------------
# second call fn----------------------
# set arg_1=8
0b11000000 #1 opcode ADD 8+0
0b00001000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0b00000001 #4 destination reg_1
# CALL fn double
CALL #1 opcode CALL
0b00000000 #2 arg1 source unused
0b00000000 #3 arg2 source unused
jump_fn_double #4 destination PC
# output result
0b10000000 #1 opcode ADD 0+reg_2
0b00000000 #2 arg1 source ImVal
0b00000010 #3 arg2 source reg_2
0b00000111 #4 destination OUTPUT
# -------------------------------------
# HALT (!unimplemented opcode)
# jump_fn_double ---------------------
# function implementation
# fn double(arg_1){reg_2=arg_1+arg_1; return reg_2}
0b00000000 #1 opcode ADD arg_1+arg_1
0b00000001 #2 arg1 source reg_1
0b00000001 #3 arg2 source reg_1
0b00000010 #4 destination reg_2
# RET
RET #1 opcode RET
0b00000000 #2 arg1 source unused
0b00000000 #3 arg2 source unused
0b00000000 #4 destination unused
# ------------------------------------
Логика разбора Opcode напрашивается в отдельную коробочку Control Unit (CU) — Блок управления
- (чтобы код не сломал процессор) Убедиться, что RET и CALL не конфликтуют с COND. Например, что будет, если написать инструкцию, где включены RET и/или CALL в opcode для COND?
Control Unit (CU) — Блок управления:
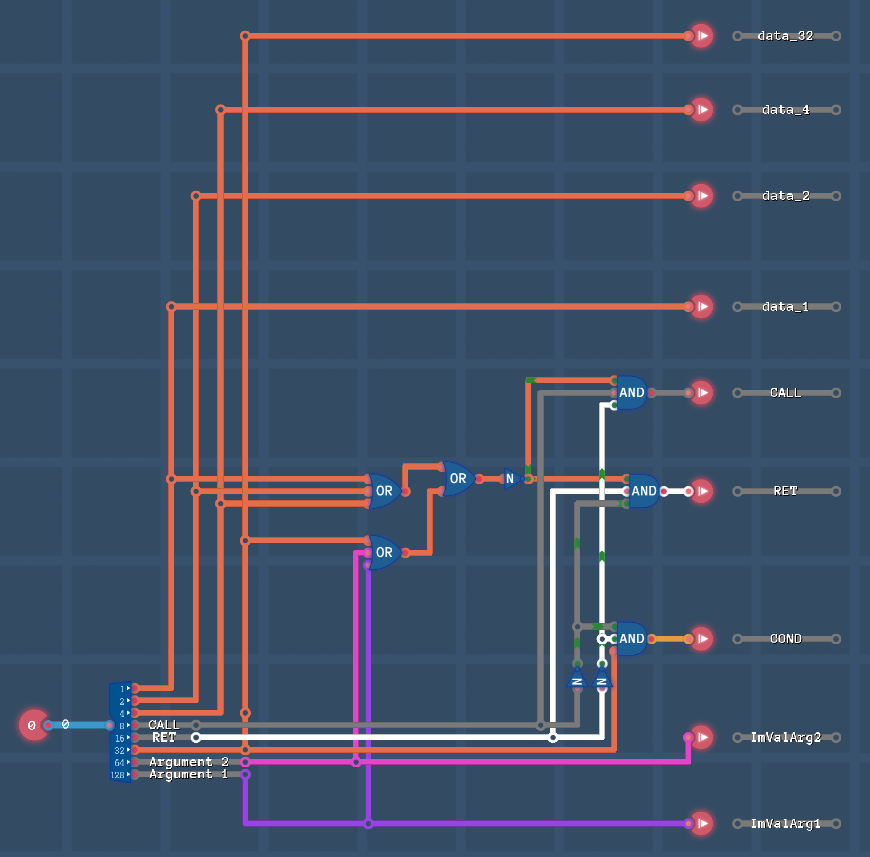
Что есть:
- режим COND
- данные берет от исчточников (Argument 1 и Argument 2)
- Result address пишет в общую шину только для PC
- запрещает писать в RAM
- режим CALL
- не использует источники (Argument 1 и Argument 2)
- Result address пишет в общую шину только для PC
- режим RET
- не использует источники (Argument 1 и Argument 2) и Result address
- режим Immediate values
- режим ALU
- всегда работа через него, что бы скопировать один источник в другой, нужно выполнять обработку + ADD, что тратит тики задержки
Обновленная версия (более понятная)
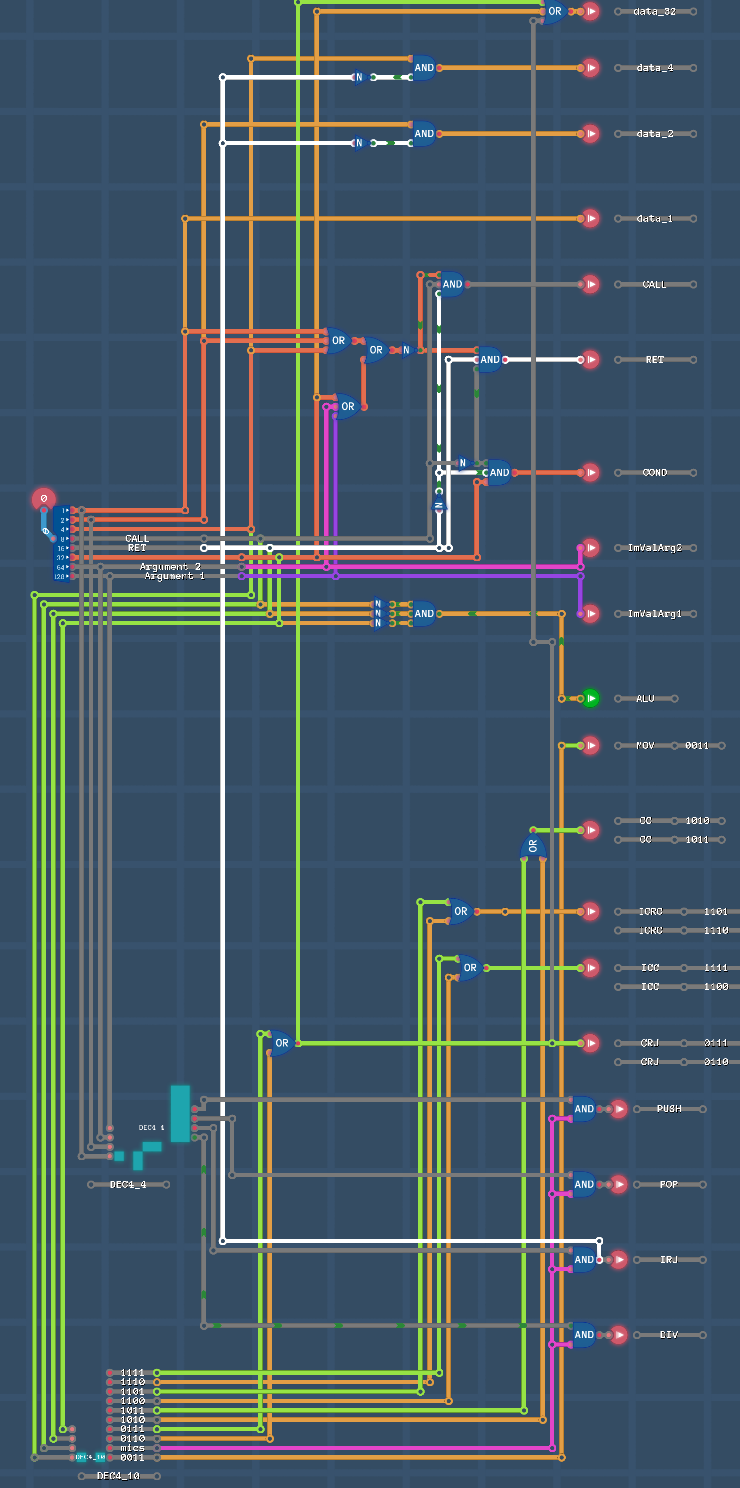
Расширение opcode инструкции
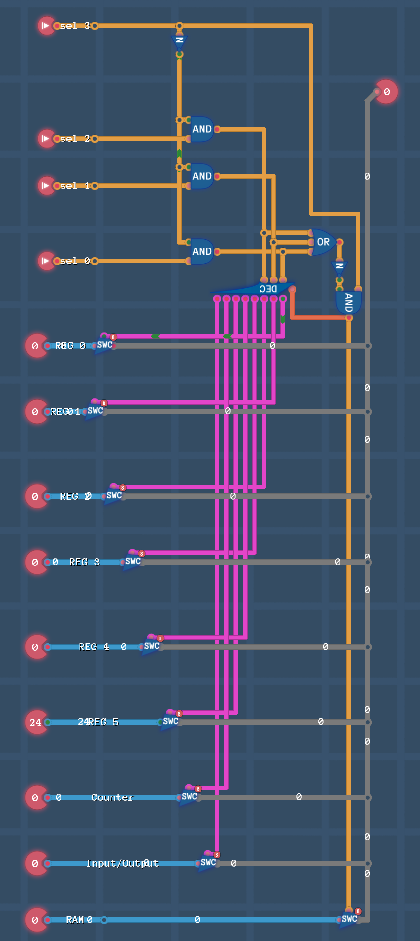
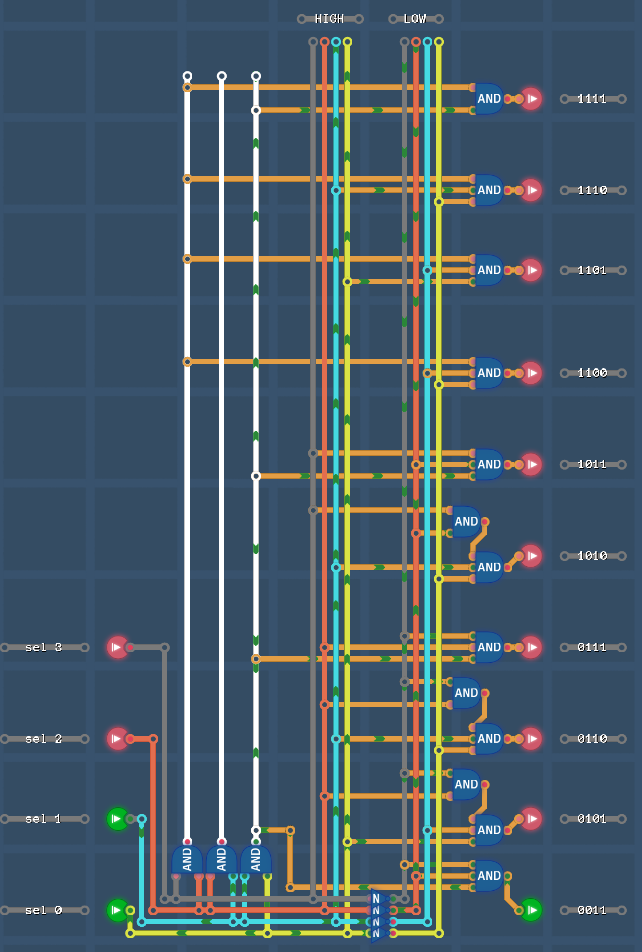
У нас есть четыре бита xx1111xx для кодирования дополнительных инструкций, за вычетом пересечений получим +9 свободных комбинаций.
Не трогаем два старших бита, чтобы иметь возможность напрямую их использовать (Immediate values) с новыми режимами, более того xxxxx1xx 3-й бит конфликтует с режимом COND в новых комбинациях.
Поэтому из двух комбинаций xxxxx1xx и xxxxx0xx мы получаем одну полноценную для совместного использования с режимом COND.
xx0011xx MOV
xx0101xx mix (PUSH,POP,DIV,IRJ)
xx0110xx CRJ (+ изменить 6-й (32) бит режима COND на 1)
xx0111xx CRJ (+ изменить 6-й (32) бит режима COND на 1)
xx1010xx CC для разных COND условий где 3-й бит 0
xx1011xx CC для разных COND условий где 3-й бит 1
xx1100xx ICC для разных COND условий где 3-й бит 0
xx1101xx ICRC для разных COND условий где 3-й бит 1
xx1110xx ICRC для разных COND условий где 3-й бит 0
xx1111xx ICC для разных COND условий где 3-й бит 1
И зафиксируем режим ALU явно:
xx000xxx
(именно эти три бита LOW идентифицируют режим ALU, так как эти биты в HIGH включают режимы COND,RET,CALL которые не нуждаются в вычислениях)
Для увеличения количества команд, можно взять одну команду xx0101xx и закодить ее в четыре (PUSH,POP,RJ,DIV) которые не используют режим COND.
128 64|xxxx|2 1
------------
x x|0101|x x
Биты 128 и 64 это старшие биты для Immediate values, для покрытия всех их пересечений map'им четыре комбинации на одну:
128 64 1 2|command|
----------|-------|
1 1 1 1 | PUSH (for example 11_0101_11 or 10_0101_11 or 00_0101_11 or 01_0101_11 )
0 1 1 1 |
1 0 1 1 |
0 0 1 1 |
----------|-------|
1 1 0 1 | POP (for example 11_0101_01 or 10_0101_01 or 00_0101_01 or 01_0101_01 )
0 1 0 1 |
1 0 0 1 |
0 0 0 1 |
----------|-------|
1 1 1 0 | IRJ (for example 11_0101_10 ... )
0 1 1 0 |
1 0 1 0 |
0 0 1 0 |
----------|-------|
1 1 0 0 | DIV (for example 11_0101_00 ... )
0 1 0 0 |
1 0 0 0 |
0 0 0 0 |
----------|-------|
Для декодирования 4 бит на 10 вариантов, реализуем неполный декодер 4 на 10 DEC4_10
1. Передача данных
Команды MOV/LOAD/STORE:
- MOV: регистр → регистр
- LOAD: память → регистр
- STORE: регистр → память
Команда MOV
Нам нужна операция MOV, что бы мы могли записать данные, минуя ALU
Opcode: xx0011xx
Arg 1: Source
Arg 2: Unused
Result addr: Destination
Как работают регистры при одновременном чтении и записи? - Они могут одновременно выдавать своё старое значение и принимать новое.
-----------------------------------------
# Сценарий проверки режима MOV/LOAD/STORE
# reg_4 - Stack Pointer (SP)
# reg_0 - RAM Pointer
# CALL opcode 00001000 (8)
# RET opcode 00010000 (16)
# MOV opcode xx0011xx
const CALL 0b00001000
const RET 0b00010000
# MOV ImVal to reg_1
0b10001100 #1 opcode MOV
0b00000101 #2 arg1 source ImVal
0b00000000 #3 arg2 source unused
0b00000001 #4 destination reg_1
# MOV reg_1 to reg_2
0b00001100 #1 opcode MOV
0b00000001 #2 arg1 source reg_1
0b00000000 #3 arg2 source unused
0b00000010 #4 destination reg_2
# MOV reg_2 to OUTPUT
0b00001100 #1 opcode MOV
0b00000010 #2 arg1 source reg_2
0b00000000 #3 arg2 source unused
0b00000111 #4 destination OUTPUT
# MOV (STORE)
# reg_2 to RAM
0b00001100 #1 opcode MOV
0b00000010 #2 arg1 source ImVal
0b00000001 #3 arg2 source unused
0b00001000 #4 destination RAM
# MOV (LOAD)
# RAM to reg_3
0b00001100 #1 opcode MOV
0b00001000 #2 arg1 source RAM
0b00000001 #3 arg2 source unused
0b00000011 #4 destination reg_3
# JMP (MOV)
0b10001100 #1 opcode MOV source destination
0b00000000 #2 arg1 source ImVal
0b00000001 #3 arg2 Unused
0b00000110 #4 destination PC
2. Сравнение и переходы (ветвления)
Без них нет циклов, условий (if, while, for, match), функций.
Команда Conditional Jump (CJ)
CJ - Условный переход реализован через команду COND с Result Address в PC:
# CJ always
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
0 #4 destination
Команда JMP
JMP безусловный переход реализован через MOV с Result Address в PC:
# JMP
0b10001100 #1 opcode MOV source destination
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 Unused
0b00000110 #4 destination PC
3. Работа со стеком или вызовами
CALL и RET
Команда CALL:
Opcode: 0b00001000
Arg 1: Unused
Arg 2: Unused
Result addr: Destination PC
Команда RET:
Opcode: 0b00010000
Arg 1: Unused
Arg 2: Unused
Result addr: Unused (Destination PC)
Проверка механизма CALL и RET. Реализуем функцию удвоения числа и вызовем ее два раза.
# reg_0 - RAM Pointer
# reg_1 - arg_1
# reg_2 - result
# CALL opcode xxxx1xxx (8)
# RET opcode xxx1xxxx (16)
const jump_fn_double 24
const CALL 0b00001000
const RET 0b00010000
# first call fn ----------------------
# set arg_1=5
0b11000000 #1 opcode ADD 5+0
5 #2 arg1 source ImVal
0 #3 arg2 source ImVal
0b00000001 #4 destination reg_1
# CALL fn double
CALL #1 opcode CALL
0 #2 arg1 source unused
0 #3 arg2 source unused
jump_fn_double #4 destination PC
# output result
0b10000000 #1 opcode ADD 0+reg_2
0 #2 arg1 source ImVal
0b00000010 #3 arg2 source reg_2
0b00000111 #4 destination OUTPUT
# ------------------------------------
# second call fn----------------------
# set arg_1=8
0b11000000 #1 opcode ADD 8+0
0 #2 arg1 source ImVal
0 #3 arg2 source ImVal
0b00000001 #4 destination reg_1
# CALL fn double
CALL #1 opcode CALL
0 #2 arg1 source unused
0 #3 arg2 source unused
jump_fn_double #4 destination PC
# output result
0b10000000 #1 opcode ADD 0+reg_2
0 #2 arg1 source ImVal
0b00000010 #3 arg2 source reg_2
0b00000111 #4 destination OUTPUT
# -------------------------------------
# HALT (!unimplemented opcode)
# jump_fn_double ---------------------
# function implementation
# fn double(arg_1){reg_2=arg_1+arg_1; return reg_2}
0b00000000 #1 opcode ADD arg_1+arg_1
0b00000001 #2 arg1 source reg_1
0b00000001 #3 arg2 source reg_1
0b00000010 #4 destination reg_2
# RET
RET #1 opcode RET
0 #2 arg1 source unused
0 #3 arg2 source unused
0 #4 destination unused
# ------------------------------------
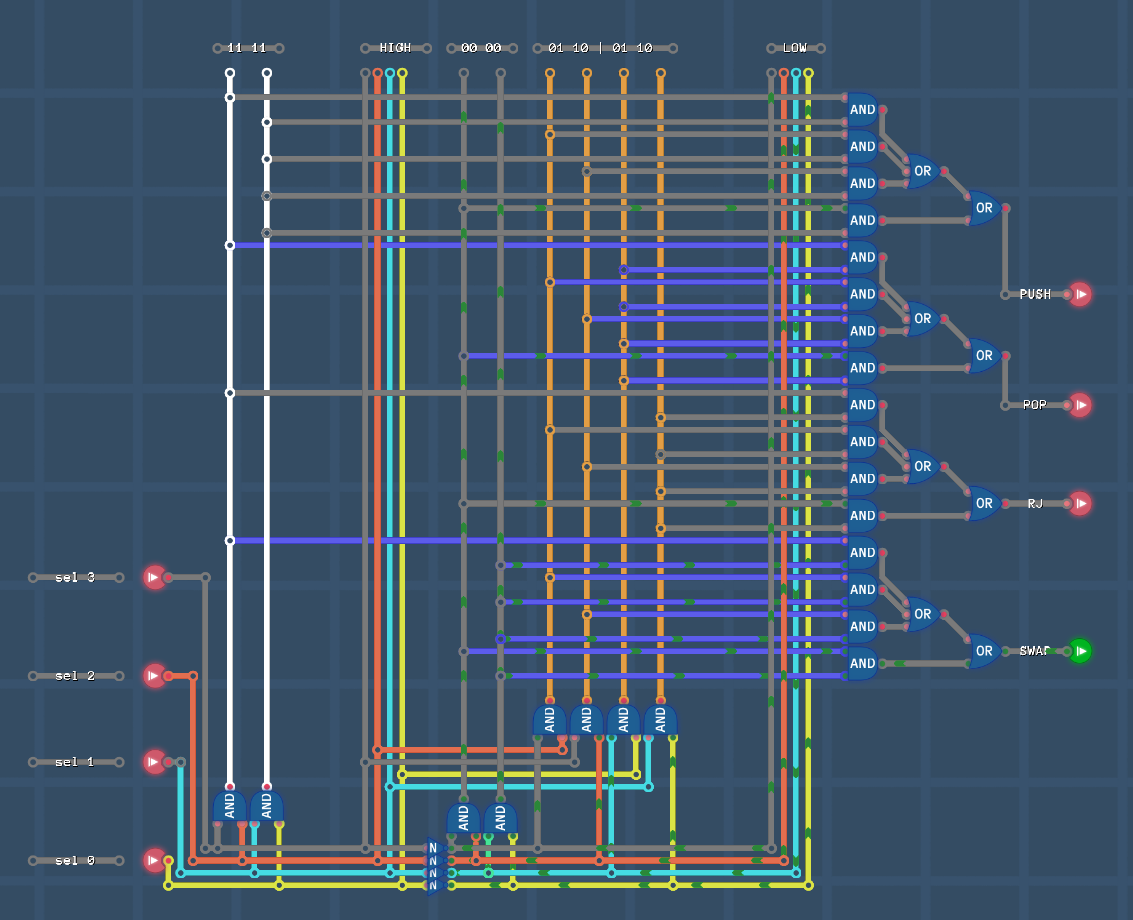
Режим PUSH/POP
- PUSH - добавить в стек
- POP - забрать из стека
Мы можем использовать RAM как стек с последних адресов и использовать регистр REG_0 в роли Stack Pointer (SP) (Указатель стека).
На данный момент для реализации поведения стека мы используем две инструкции
- изменение индекса регистра Stack Pointer (SP)
- запись/чтение из стека RAM[SP]
Для команд PUSH/POP необходимо ограничится одной инструкцией т.е. изменение SP должно происходить в железе. А возможность реализовать стек используя REG_0 в роли SP осталась, просто область адресов нужно выбирать выше адресов стека.
Чтобы не потерять/затереть значение в регистре, в начале вызова функции делают PUSH (кладут значение в RAM «на хранение»), а в конце — POP (забирают обратно).
Это позволит делать функции с любым количеством аргументов, не боясь, что они перезапишут регистры основной программы.
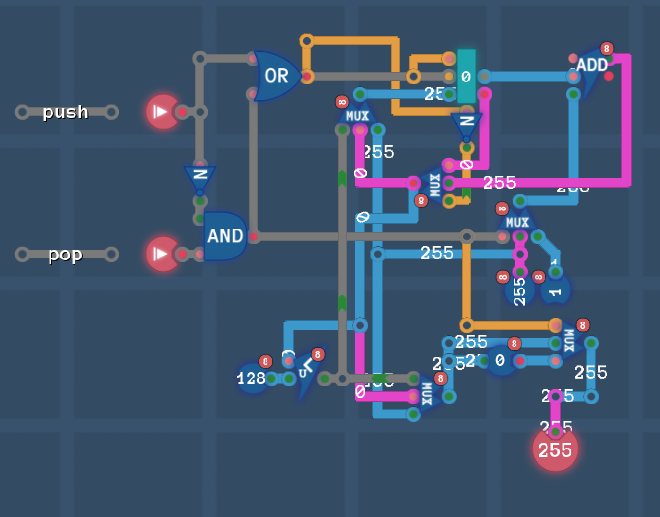
Push
Opcode: xx010111
Arg 1: Source
Arg 2: Unused
Result addr: Unused (destination RAM 0b00001000)
p.s. свободные два байта можно было бы использовать:
Arg 2при наличии его, по прямому назначению для ALUResult addrв роли инструкций ALU/Cond
Pop
Opcode: xx010101
Arg 1: Unused (source RAM 0b00001000)
Arg 2: Unused
Result addr: Destination
Реализация (auto-increment/decrement)
# test PUSH/POP
# 2. PUSH
# 1. POP
#--------------------
# expected behavior:
# OUTPUT: 3, 2, 1, 3, 2, 1...
#--------------------
label jump_start
# PUSH
0b10010111 #1 opcode PUSH
0b00000001 #2 arg1 source ImVal
0 #3 arg2 Unused
0 #4 destination Unused
# PUSH
0b10010111 #1 opcode PUSH
0b00000010 #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000100 #4 destination Unused
# PUSH
0b10010111 #1 opcode PUSH
0b00000011 #2 arg1 source ImVal
0 #3 arg2 Unused
0 #4 destination Unused
# POP
0b00010101 #1 opcode POP
0 #2 arg1 Unused
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
# POP
0b00010101 #1 opcode POP
0 #2 arg1 Unused
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
# POP
0b00010101 #1 opcode POP
0 #2 arg1 Unused
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
# JMP
0b10001100 #1 opcode MOV source destination
jump_start #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000110 #4 destination PC
Схема LEG CPU2
ISA для процессора LEG
[первый байт][второй байт ][трейтий байт ][четвертый байт ]
[что делать ][источник 1 ][источник 2 ][куда девать результат]
[Opcode 8bit][Argument 1 8bit][Argument 2 8bit][Result address 8bit ]
Opcode 8bit:
ALU:
биты xx000111 режима ALU, результат его работы в общую шину:
0: ALU xxxxxxx1 #1
1: ALU xxxxxx1x #2
2: ALU xxxxx1xx #4
ALU DIV:
opcode: xx010100
arg_1 : Source
arg_2 : Source
result_addr: Destination
CALL:
бит режима CALL, данные из Result address (четвертый байт ISA инс.) в общую шину для PC:
3: CALL 00001000 #8 идентификатор режима
RET:
бит режима RET, данные из Result address (четвертый байт ISA инс.) в общую шину для PC:
4: RET 00010000 #16 идентификатор режима
COND:
биты xx1xx111 режима COND, данные из Result address (четвертый байт ISA инс.) в общую шину для PC.
0: COND xxxxxxx1 #1
1: COND xxxxxx1x #2
2: COND xxxxx1xx #4
5: COND xx1xxxxx #32 идентификатор режима, если бит установлен
Immediate values:
биты 11xxxxxx режима Immediate values:
6: x1xxxxxx #64 выбор в роли Immediate values Argument 2 (трейтий байт ISA инс.) идентификатор режима, если бит установлен
7: 1xxxxxxx #128 выбор в роли Immediate values Argument 1 (второй байт ISA инс.) идентификатор режима, если бит установлен
MOV:
биты xx0011xx режима MOV
opcode: xx0011xx
arg_1: Source
arg_2: Unused
result_addr: Destination (для JMP Result addr = 6 PC)
PUSH:
opcode: xx010111
arg_1 : Source
arg_2 : Unused
result_addr: Unused (target RAM)
POP:
opcode: xx010101
arg_1 : Unused (зафиксирован источник RAM 0b00001000)
arg_2 : Unused
result_addr: Destination
Argument 1/Argument 2/Result address 8bit:
биты xxxx1111 кодируют адрес исчтоника/пунтка назначения:
0: #1 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
1: #2 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
2: #4 участвует в кодировании восьми адресов (Register 0-5, PC, Input/Output)
4: #8 xxxx1xxx только для RAM
Результат декодирования трех младших бит xxxxx111:
0: Register 0
1: Register 1
2: Register 2
3: Register 3
4: Register 4
5: Register 5
6: Counter (PC)
7: Input (для Argument 1 и Argument 2) или Output (для Result address)
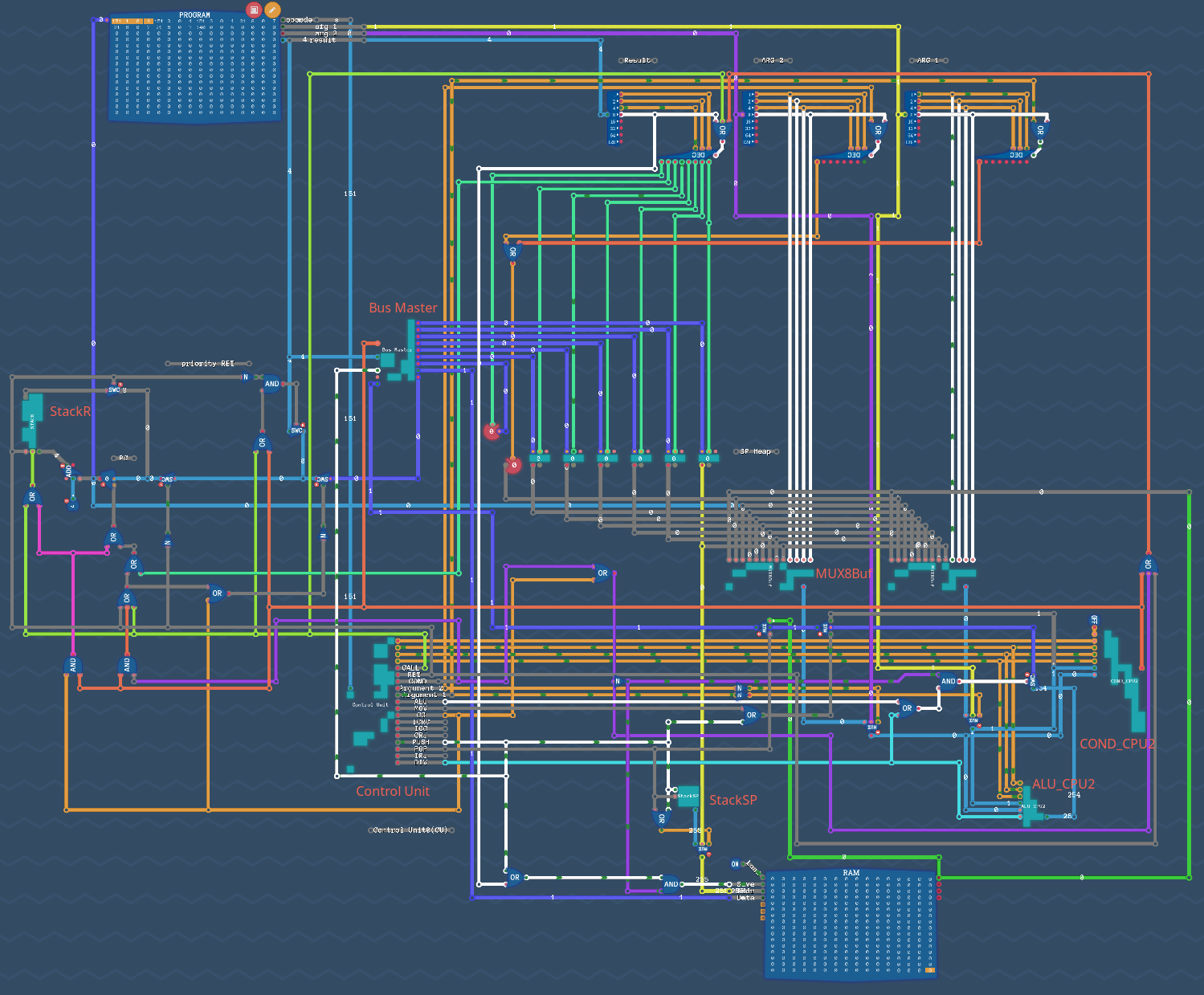
(p.s. команда CC не используется в игре)
Компонент stack с автоматическим счетчиком SP:
Компонент ALU_CPU2 с DIV:
Компонент DIV:
Компонент COND_CPU2
Компонент Control Unit (CU) — Блок управления:
Компонент Decoder 4 to 4:
Компонент Decoder 4 to 10 (был ранее показан):
Компонент StackR адресов возврата:
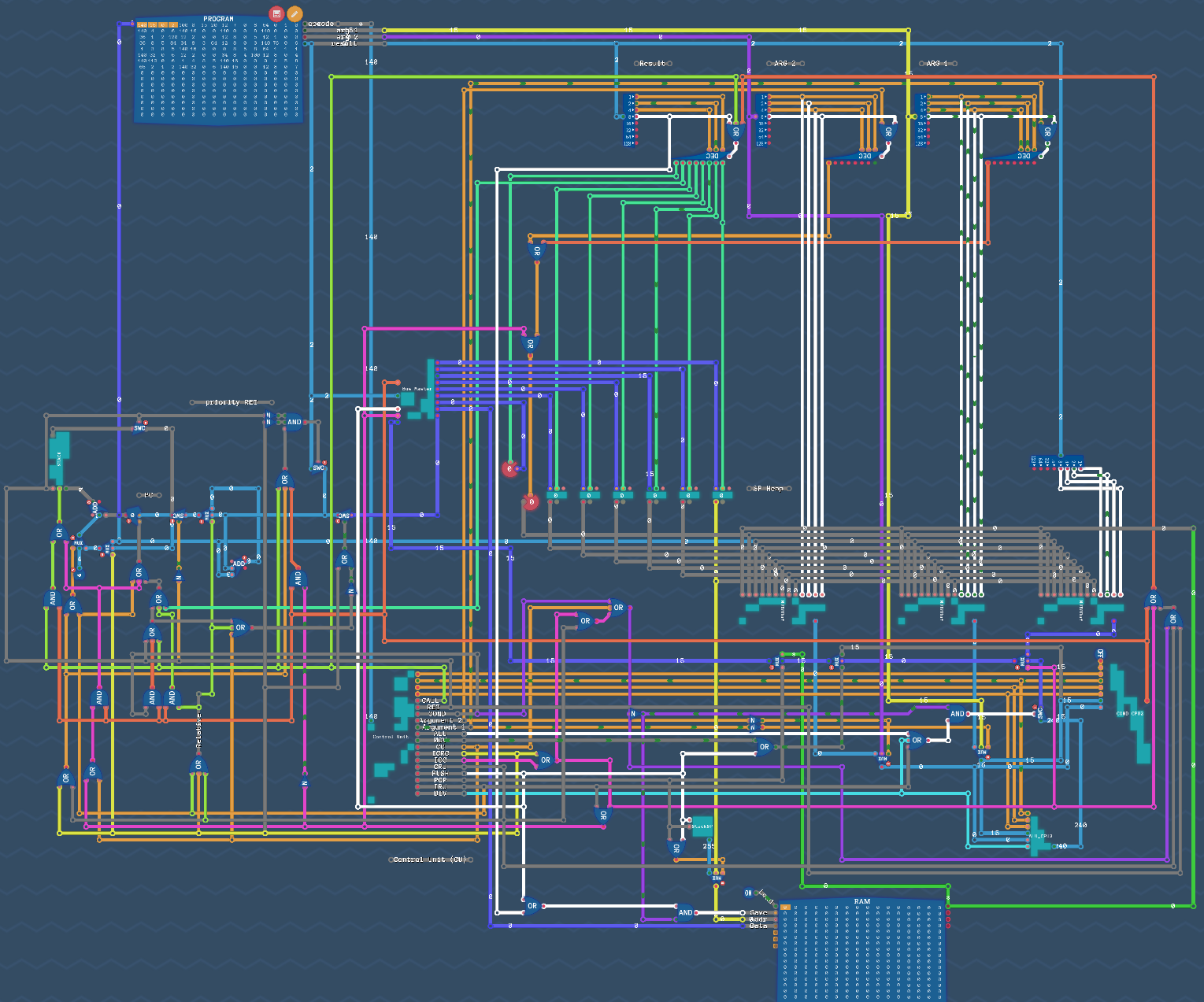
Компонент Bus Master:
Компонент MUX8Buf:
Все команды ниже - не будут применяться в уровнях игры.
Режим Conditional CALL (CC):
CC - Условный CALL (Conditional CALL)
Сейчас нет возможности одной инструкцией выполнить проверку условия и выполнить вызов CALL.
Это позволит писать код типа if (a == 10) run_function().
- Если arg1 == arg2, мы не просто меняем PC, мы сначала запоминаем, где мы стояли, чтобы потом вернуться (командой RET)
- Нужно в «железе» объединить логику записи в стек и логику проверки условия.
Сейчас для этого нужно две инструкции (сначала COND для прыжка на вызов, а потом сам CALL с запоминанием адреса возврата).
Режим CC
Opcode: xx1010xx и xx1011xx
Arg 1: Source
Arg 2: Source
Result addr: Destination
xx1011xx - для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
xx1010xx - для остальных условий COND
# Поведение сейчас:
# always jump
0b11100000 #1 cond IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_while #4 destination
# и тут мы не можем выполнить RET так как адрес возврата никто не запоминал. Адрес возврата запоминается при команде CALL но не COND
# ...
# Поведение которое нам нужно:
# always jump
0b11010100 #1 COND_CALL IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_while #4 destination
# метка jump_while и нас сюда перебросил PC
# мы выполняем RET и нас перебрасывает на следующую инструкцию после места с которого мы пришли по условию COND_CALL
RET #1 opcode RET
0b00000000 #2 arg1 source unused
0b00000000 #3 arg2 source unused
0b00000000 #4 destination unused
# Сценарий проверки режима CC
# MOV opcode xx0011xx
# CC opcode xx1010xx для остальных условий COND
# CC opcode xx1011xx для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
const RET 0b00010000
#--------------------
# expected behavior:
# OUTPUT: 6, 7, 8, 6, 7, 8...
#--------------------
label jump_start
# test CC IF 0==0
0b11101000 #1 CC
0 #2 arg1 source ImVal
0 #3 arg2 source ImVal
jump_success #4 destination
# print 7
0b11000000 #1 ALU ADD
4 #2 arg1 source ImVal
3 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# test CC IF 1==0
0b11101000 #1 CC
1 #2 arg1 source ImVal
0 #3 arg2 source ImVal
jump_success #4 destination
# print 8
0b11000000 #1 ALU ADD
4 #2 arg1 source ImVal
4 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# always jump
0b11100000 #1 COND IF_EQUAL arg1 == arg2
0b00000000 #2 arg1 source ImVal
0b00000000 #3 arg2 source ImVal
jump_start #4 destination
label jump_success
# print 6
0b11000000 #1 ALU ADD
4 #2 arg1 source ImVal
2 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
RET #1 RET
0b00000000 #2 arg1 source
0b00000000 #3 arg2 source
0b00000000 #4 destination
Режим Indirect Jump (ICC):
Про Indirect Jump:
- Косвенный переход (Indirect Jump)
- Сейчас Result address (4-й байт) — это всегда число (адрес в RAM). Но что, если мы захотим прыгнуть по адресу, который лежит в регистре?
- Это нужно для реализации оператора switch (таблицы переходов)
- "Возьми адрес для прыжка не из 4-го байта Result address (Immediate values), а из reg_N, на который этот байт указывает".
- И эта возможность у нас уже реализованна в режиме ALU (или MOV), мы просто для Result address выбираем PC и результат операции ADD данных из reg_N + 0 перезапишет PC
Про Indirect Conditional CALL (ICC):
- Реализуя поведение Indirect Jump вместе с Conditional и CALL, получим Indirect Conditional CALL (ICC), что позволит выполнять переход на указанный адрес из регистра/RAM по условию с сохранением адреса возврата.
Opcode: xx1111xx и xx1100xx
Arg 1: Source
Arg 2: Source
Result addr: используется в роли Source для Result addr
xx1111xx - для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
xx1100xx - для остальных условий COND
# Сценарий проверки режима ICC
# MOV opcode xx0011xx
# CC opcode xx1011xx для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
# CC opcode xx1010xx для остальных условий COND
# ICC opcode xx1111xx для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
# ICC opcode xx1100xx для остальных условий COND
const RET 0b00010000
#--------------------
# expected behavior:
# OUTPUT: 6,7,8,6,7,8...
#--------------------
label jump_start
# MOV 12 to reg_4
0b10001100 #1 MOV
jump_success #2 arg1 source ImVal
0b00000000 #3 arg2 source unused
0b00000100 #4 destination reg_4
# ICC cond IF_EQUAL 44==44
0b11110000 #1 ICC
44 #2 arg1 source ImVal
44 #3 arg2 source ImVal
0b00000100 #4 destination reg_4
# print 7
0b11000000 #1 ALU ADD
5 #2 arg1 source ImVal
2 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
0b10001100 jump_second_step 0 6 #jump
label jump_success
# print 6
0b11000000 #1 ALU ADD
4 #2 arg1 source ImVal
2 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
RET #1 RET
0b00000000 #2 arg1 source
0b00000000 #3 arg2 source
0b00000000 #4 destination
label jump_second_step
# ICC cond IF_EQUAL reg_4==0
0b01110000 #1 ICC
0b00000100 #2 arg1 source reg_4
0b00000000 #3 arg2 source ImVal
0b00000100 #4 destination reg_4
# print 8
0b11000000 #1 ALU ADD
4 #2 arg1 source ImVal
4 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# JMP
0b10001100 #1 MOV source destination
jump_start #2 arg1 source ImVal
0b00000000 #3 arg2 Unused
0b00000110 #4 destination PC
Плюс третий декодер источников специально для этого режима, и регистры заменились на прозрачные т.е. всегда LOAD, тогда может и декодеры для выбора источника не нужны?
Команды Relative Jumps: IRJ, CRJ, ICRC
Поддержка относительных переходов (Relative Jumps)
- Сейчас в режиме COND Result address — это всегда абсолютный адрес (например, "прыгни на 100").
- Это мешает делать перемещаемый код (когда мы можем скопировать кусок программы в другое место памяти, и он продолжит работать).
- Логика: Значение из Result address не просто заменяет PC, а складывается с текущим PC. Это позволит делать короткие циклы типа "прыгни на 5 байт назад".
Про Relative Jumps (RJ): (unimplemented)
- RJ относительный переход
p.s. команда RJ не использует старшие биты, что дает возможность закодировать еще +3 команды без условных операций.
Про Indirect Relative Jumps (IRJ):
- IRJ относительный переход
Opcode: xx010110
Arg 1: Source
Arg 2: Source
Result addr: Unused (target ADD Source+Source=PC)
------------------------
# test IRJ:
#--------------------
# expected behavior:
# jump to jump_success
# OUTPUT: 3,3...
#--------------------
label jump_start
# MOV 6 to reg_3
0b10001100 #1 MOV
6 #2 arg1 source ImVal
0 #3 arg2 unused
0b00000011 #4 destination reg_3
# IRJ ADD source+source=PC
0b10010110 #1 IRJ 2+6=8 result addr
2 #2 arg1 source ImVal
0b00000011 #3 arg2 source reg_3
0 #4 unused
# print 5
0b10001100 #1 MOV
5 #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
label jump_success
# print 3
0b10001100 #1 MOV
3 #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000111 #4 destination OUTPUT
# JMP
0b10001100 #1 MOV source destination
jump_start #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000110 #4 destination PC
Про Conditional Relative Jumps (CRJ):
- CRJ условный относительный переход, т.е. мы по условию выполняем прыжок по результату сложения текущего адреса PC с значением из Result addr
- Применяется когда мы хотим просто прыгнуть по условию внутри if или цикла (без возврата) но без сохранения адреса возврата в стеке.
Opcode: xx0110xx и xx0111xx
Arg 1: Source
Arg 2: Source
Result addr: ImVal
xx0111xx CRJ - для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
xx0110xx CRJ - для остальных условий COND
--------------------------
# test CRJ:
#--------------------
# expected behavior:
# jump to jump_success
# OUTPUT: 6,7,6,7...
#--------------------
label jump_start
# print 7
0b11000000 #1 ADD
4 #2 arg1 source ImVal
3 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# CRJ cond IF_EQUAL 0==0
0b11011000 #1 CRJ +16
0 #2 arg1 source ImVal
0 #3 arg2 source ImVal
16 #4 destination ImVal
# print 5
0b11000000 #1 ADD
0b00000100 #2 arg1 source ImVal
0b00000001 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
label jump_second_step
# CRJ cond IF_EQUAL 1==0
0b11011000 #1 CRJ +8
1 #2 arg1 source reg_1
0 #3 arg2 source reg_2
8 #4 destination ImVal
# JMP
0b10001100 #1 MOV source destination
jump_start #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000110 #4 destination PC
label jump_success
# print 6
0b11000000 #1 ADD
4 #2 arg1 source ImVal
2 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# JMP
0b10001100 #1 MOV source destination
jump_second_step #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000110 #4 destination PC
Про Indirect Conditional Relative CALL (ICRC):
- ICRC Косвенный условный относительный переход с сохранением адреса возврата (т.е нам нужно выполнять RET)
Opcode: xx1101xx и xx1110xx
Arg 1: Source
Arg 2: Source
Result addr: используется в роли Source для Result addr
xx1101xx ICRC - для условий COND: IF_GREATER_OR_EQUAL,IF_GREATER
xx1110xx ICRC - для остальных условий COND
--------------------------------
# test ICRC
#--------------------
# expected behavior:
# jump to jump_success
# OUTPUT: 5,6,7,5,6,7 ...
#--------------------
# RET opcode 00010000 (16)
const RET 0b00010000
label jump_start
# MOV reg_4 20
0b10001100 #1 MOV
20 #2 arg1 source ImVal
0b00000000 #3 arg2 Unused
0b00000100 #4 destination reg_4
# ICRC cond IF_EQUAL 1==1
0b11111000 #1 ICRC +reg_4
1 #2 arg1 source ImVal
1 #3 arg2 source ImVal
0b00000100 #4 destination reg_4
# print 6
0b11000000 #1 ADD
3 #2 arg1 source ImVal
3 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# ICRC cond IF_EQUAL 1==0
0b11111000 #1 ICRC +reg_4
1 #2 arg1 source ImVal
0 #3 arg2 source ImVal
0b00000100 #4 destination reg_4
# print 7
0b11000000 #1 ADD
4 #2 arg1 source ImVal
3 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# JMP
0b10001100 #1 MOV source destination
jump_start #2 arg1 source ImVal
0b00000000 #3 arg2 Unused
0b00000110 #4 destination PC
label jump_success
# print 5
0b11000000 #1 ADD
4 #2 arg1 source ImVal
1 #3 arg2 source ImVal
0b00000111 #4 destination OUTPUT
# RET
RET #1 RET
0 #2 arg1 source
0 #3 arg2 source
0 #4 destination
# JMP
0b10001100 #1 opcode MOV source destination
jump_start #2 arg1 source ImVal
0 #3 arg2 Unused
0b00000110 #4 destination PC
Команды ALU MUL,SIN,COS: (unimplemented)
Арифметичиеские операции - это основа вычислений, поэтому они должны быть максимально реализованы.
- INC/DEC (увеличение/уменьшение на 1)
- MUL/IMUL (умножение без/со знаком)
- DIV/IDIV (деление)
Архитектура ALU через флаги.
Флаги — это специальные биты (Zero, Carry, Sign и др.), которые автоматически обновляются процессором после арифметических или логических операций.
- Z (Zero) Результат = 0
- N (Negative) Результат < 0 (старший бит)
- C (Carry) Была перенос/заём при сложении/вычитании
- V (Overflow) Переполнение знакового числа
Зачем они нужны:
- Для условных переходов: Позволяют выполнять
if/else,whileиforна основе результата предыдущей операции (например, «если результат равен нулю», «если число отрицательное»). - Для математики: Позволяют обрабатывать переносы (carry) при вычислениях с числами больше разрядности процессора (например, 16-битное число на 8-битном процессоре).
- Экономия ресурсов: Позволяют принимать логические решения, не сохраняя промежуточные результаты вычислений в регистры.
Команда HALT: (unimplemented)
У нас еще не реализована возможность завершить работу процессора, остановив счетчик программ PC или CLOCK - HALT
Двухуровневая архитектура: (unimplemented)
Двухуровневая архитектура, с 8-ми битными инструкциями для скорости и 32-х битными для мощности.
Поддержка прерываний (Interrupts): (unimplemented)
Возможность процессора мгновенно бросить выполнение текущей программы, если нажата клавиша или сработал таймер.
Для многозадачности (переключение программ по таймеру) и мгновенной реакции на ввод-вывод.
Схема LEG extend
Схема LEG extend
Создание программы Ассемблер
Нам нужна программа (скрипт или исполняемый файл) которая распарсит наши словесные команды в машинные байты на основе разработанной инструкции ISA.
Этот процесс называется ассемблирование (англ. assembly), а программа, которая это делает - ассемблер:
- лексер (разбиение строк)
- парсер
- IR (Intermediate Representation) внутренний формат программы
- двухпроходный ассемблер
- кодогенератор
Двухпроходный ассемблер (англ. two-pass assembly) нужен из-за одной фундаментальной проблемы: адреса меток неизвестны, пока не будет разобран весь код.
Проход 1 - только поиск меток (symbol table construction)
-
Ассемблер проходит по коду и считает адреса инструкций, создавая таблицу:
labels = { "jump_start": 12, "jump_while": 20 }
Проход 2 - кодирование (code generation/instruction encoding)
- Теперь ассемблер снова идет по коду. Встречая в коде метку
JMP jump_startсмотрит таблицу и подставляет реальный адрес расположения инструкцииJMP 12
Директивы ассемблера - команды для самого ассемблера, управляют тем, как именно этот код и данные размещаются в памяти (адресом и выходным буфером):
- .data - секция данных, говорит ассемблеру что началась секция данных
- .text - секция кода, говорит ассемблеру что началась секция инструкций
- .org 0x100 - установить адрес смещения, позволяет указать точный адрес, откуда начинается запись.
- .byte 5 - позволяет добавить конкретные данные в память
.org 0
.text
start:
MOV 5, r1
.data
.org 20
value:
.byte 42
-
Директива
.org <addr>- Устанавливает текущий адрес записи на 0.
- Всё, что будет дальше, помещается в память начиная с адреса 0.
- Это полезно, если нужно разместить код или данные в конкретном месте памяти.
-
Директива
.text(пока секции можно использовать для логики)- Начальная секция адреса начинается с адреса 0 (если нет
.org) - Начало секции кода (инструкции).
- Константы Immediate Value, это просто директива ассемблеру подставить значение, физически место в исполняемом файле оно не занимет, так как это сам код, а не данные.
- Начальная секция адреса начинается с адреса 0 (если нет
-
Директива
.data- Начало секции данных. По умолчанию
.dataидёт сразу после.text, а если есть.org- он имеет приоритет. - Если
.dataс.orgперекрывает код -Error: data section overlaps with text section - Всё, что после этого (например,
.byte) - не инструкции, а сырые данные в памяти. - Ассемблер только размечает место для данных, а загрузчик операционной системы уже физически(виртуальная память процесса) выдает инструкции памяти выделить по этому адресу место.
Для реализации
constразместим данные в секции.data..org 0 .text start: MOV [my_value2], r1 # indirect addressing unimplimented MOV my_value2, r1 # .data label MOV 40, r1 MOV r2, r1 .data my_value: .byte 42 my_value2: .byte 43# label addresses: # my_value: 016 # my_value2: 017 # start: 000 # ------------------------------ # bytes |:addr|text instruction 0b10001100 #:000 |MOV 17, r1 0b00010001 #:001 0b00000000 #:002 0b00000001 #:003 0b10001100 #:004 |MOV 43, r1 0b00101011 #:005 0b00000000 #:006 0b00000001 #:007 0b10001100 #:008 |MOV 40, r1 0b00101000 #:009 0b00000000 #:010 0b00000001 #:011 0b00001100 #:012 |MOV r2, r1 0b00000010 #:013 0b00000000 #:014 0b00000001 #:015 - Начало секции данных. По умолчанию
-
Директива
.byte42- Записывает один байт со значением 42 по текущему адресу.
- После этого текущий адрес увеличится на 1.
Пример работы .org:
.org 8
.text
start:
CJE 255, 255, start
CJE 255, 255, end
end:
MOV 255, io
# label addresses:
# start: 008
# end: 016
# ------------------------------
# bytes |:addr|text instruction
0b00000000 #:000 |ADD r0, r0, r0
0b00000000 #:001
0b00000000 #:002
0b00000000 #:003
0b00000000 #:004 |ADD r0, r0, r0
0b00000000 #:005
0b00000000 #:006
0b00000000 #:007
0b11100000 #:008 |CJE 255, 255, :008
0b11111111 #:009
0b11111111 #:010
0b00001000 #:011
0b11100000 #:012 |CJE 255, 255, :016
0b11111111 #:013
0b11111111 #:014
0b00010000 #:015
0b10001100 #:016 |MOV 255, io
0b11111111 #:017
0b00000000 #:018
0b00000111 #:019
-
Пример автоматического расчета адреса для данных:
(данные начнутся с адреса :016)
.org 4 .text start: CJE 255, 255, start CJE 255, 255, end end: MOV 255, io .data .byte 5# label addresses: # start: 004 # end: 012 # ------------------------------ # bytes |:addr|text instruction 0b00000000 #:000 |ADD r0, r0, r0 0b00000000 #:001 0b00000000 #:002 0b00000000 #:003 0b11100000 #:004 |CJE 255, 255, :004 0b11111111 #:005 0b11111111 #:006 0b00000100 #:007 0b11100000 #:008 |CJE 255, 255, :012 0b11111111 #:009 0b11111111 #:010 0b00001100 #:011 0b10001100 #:012 |MOV 255, io 0b11111111 #:013 0b00000000 #:014 0b00000111 #:015 -
Можно и явно задать адрес данных, главное он должен начинаться после секции
.text.org 4 .text start: CJE 255, 255, start CJE 255, 255, end end: MOV 255, io .data .org 16 .byte 5 -
Перекрытие адресов секции станет причиной ошибки ассемблирования:
Error: data section overlaps with text section.org 4 .text start: CJE 255, 255, start CJE 255, 255, end end: MOV 255, io .data .org 14 .byte 5
Готовый Ассемблер
Список поддерживаемых команд:
.org 0
.text
jump_start:
# comment
MOV 1, r3 # comment
MOV 2, ram
MOV 3, pc
MOV 4, io
MOV r1, r2
MOV ram, r2
MOV ram, ram
MOV ram, pc
MOV pc, ram
MOV io, ram
MOV io, pc
MOV io, io
PUSH r0
PUSH 255
PUSH ram
PUSH io
PUSH pc
POP r0
POP ram
POP io
POP pc
ADD 5, r2, r3
ADD r1, r2, r3
SUB 5, r2, r3
SUB r1, r2, r3
AND 5, r2, r3
AND r1, r2, r3
OR 5, r2, r3
OR r1, r2, r3
NOT 5, r3
NOT r1, r3
XOR 5, r2, r3
XOR r1, r2, r3
NAND 5, r2, r3
NAND r1, r2, r3
NOR 5, r2, r3
NOR r1, r2, r3
DIV 5, r2, r3
DIV r1, r2, r3
CALL jump_here
CJE 5, 4, jump_start
CJNE 5, 4, jump_start
CJL 5, 4, jump_start
CJLE 5, 4, jump_start
CJG 5, 4, jump_start
CJGE 5, 4, jump_start
JMP jump_start
MOV [var_1], r1 # косвенная адресация не поддерживается LEG
MOV var_1, r1 # подстановка констант Immediate Value
MOV 40, r1 # Immediate Value
MOV r2, r1
jump_here:
NOR 5, r2, r3
NOR r1, r2, r3
RET
.data
var_1:
.byte 42
var_2:
.byte 43
Поле с кодом - редактируемое.
use legassembly::assembly; fn main(){ static INPUT: &str = " .org 0 .text jump_start: MOV [var_1], r1 # косвенная адресация, не поддерживается LEG MOV var_1, r1 # подстановка констант Immediate Value MOV 40, r1 # Immediate Value MOV r2, r1 JMP jump_start .data var_1: .byte 42 "; let output_debug = true; assembly(INPUT, output_debug); } #[allow(unused_assignments)] #[allow(unused_variables)] mod legassembly{ use self::disassembly::decode; use std::collections::HashMap; #[derive(Debug)] enum ParsedLine { Label(String), Instruction(Instruction), Directive(Directive), Empty, } #[derive(Debug)] enum Directive { Data, Text, Org(u8), Byte(u8), } #[derive(Debug)] enum Operand { Source(u8), Immediate(u8), IndirectAddr(String), MemLabel(String), } #[derive(Debug)] struct SourceOperand{ imm_flag: u8, src: Operand } impl SourceOperand { pub fn new(imm_flag: u8, src: Operand) -> Self{ Self{imm_flag, src} } } #[derive(Debug)] enum Instruction { Mov { src: SourceOperand, dst: u8 }, Push { src: SourceOperand}, Pop { dst: u8 }, Jmp { label: String }, Cj { a: SourceOperand, b: SourceOperand, label: String, inst: u8 }, Add { a: SourceOperand, b: SourceOperand, dst: u8 }, Sub { a: SourceOperand, b: SourceOperand, dst: u8 }, And { a: SourceOperand, b: SourceOperand, dst: u8 }, Or { a: SourceOperand, b: SourceOperand, dst: u8 }, Not { a: SourceOperand, dst: u8 }, Xor { a: SourceOperand, b: SourceOperand, dst: u8 }, Nand { a: SourceOperand, b: SourceOperand, dst: u8 }, Nor { a: SourceOperand, b: SourceOperand, dst: u8 }, Div { a: SourceOperand, b: SourceOperand, dst: u8 }, Call { label: String }, Ret, } #[derive(Debug)] struct EncodedInstruction { opcode: u8, arg1: u8, arg2: u8, result: u8, } enum AluOp { Add, Sub, And, Or, Xor, Nand, Nor, Div, } #[derive(Clone, Copy, PartialEq)] enum Section { Text, Data, } /* jump_start: # comment MOV 1, r3 # comment MOV 2, ram MOV 3, pc MOV 4, io MOV r1, r2 MOV ram, r2 MOV ram, ram MOV ram, pc MOV pc, ram MOV io, ram MOV io, pc MOV io, io PUSH r0 PUSH 255 PUSH ram PUSH io PUSH pc POP r0 POP ram POP io POP pc ADD 5, r2, r3 ADD r1, r2, r3 SUB 5, r2, r3 SUB r1, r2, r3 AND 5, r2, r3 AND r1, r2, r3 OR 5, r2, r3 OR r1, r2, r3 NOT 5, r3 NOT r1, r3 XOR 5, r2, r3 XOR r1, r2, r3 NAND 5, r2, r3 NAND r1, r2, r3 NOR 5, r2, r3 NOR r1, r2, r3 DIV 5, r2, r3 DIV r1, r2, r3 CALL jump_here CJE 5, 4, jump_start CJNE 5, 4, jump_start CJL 5, 4, jump_start CJLE 5, 4, jump_start CJG 5, 4, jump_start CJGE 5, 4, jump_start JMP jump_start jump_here: NOR 5, r2, r3 NOR r1, r2, r3 RET */ pub fn assembly(input: &str, output_debug: bool) { const INSTRUCTION_BIT_DEPTH: u8 = 4; let lines: Vec<&str> = input.lines().collect(); let mut data_values: HashMap<String, u8> = HashMap::new(); // PASS 1: collect labels let mut labels = HashMap::new(); let mut address: u8 = 0; let mut last_label: Option<String> = None; let mut section = Section::Text; let mut text_end: u8 = 0; let mut data_org: Option<u8> = None; for line in &lines { match parse_line(line) { ParsedLine::Label(name) => { labels.insert(name.clone(), address); last_label = Some(name); } ParsedLine::Instruction(_) => { address = address.checked_add(INSTRUCTION_BIT_DEPTH) .unwrap_or_else(|| panic!("Address overflow! \nThe maximum address value is 255. \nCurrent address:{} + depth:{} > 255",address,INSTRUCTION_BIT_DEPTH)); } ParsedLine::Directive(d) => { match d { Directive::Org(addr) => { if section == Section::Data { data_org = Some(addr); if addr < text_end { panic!("Error: data section overlaps with text section"); } } address = addr; } Directive::Byte(value) => { if section == Section::Data { if let Some(label) = &last_label { data_values.insert(label.clone(), value); } else { panic!(".byte without label in data section"); } } address = address.checked_add(1) .unwrap_or_else(|| panic!("Address overflow! \nThe maximum address value is 255. \nCurrent address:{} + 1 > 255",address)); } Directive::Text => { section = Section::Text; } Directive::Data => { section = Section::Data; // фиксируем конец текста text_end = address; let data_start = match data_org { Some(addr) => addr, None => text_end, }; if data_start < text_end { panic!("Error: data section overlaps with text section"); } address = data_start; } } } ParsedLine::Empty => {} } } // Debug label addresses if output_debug { println!("# label addresses:"); for (key, value) in &labels { println!("# {}: {:03}", key, value); } println!("# ------------------------------"); } // PASS 2: encode instructions let mut output: Vec<u8> = vec![0; 256]; let mut max_address: u8 = 0; address = 0; let mut section = Section::Text; let mut text_end: u8 = 0; let mut data_org: Option<u8> = None; for line in &lines { match parse_line(line) { ParsedLine::Instruction(instr) => { let encoded = encode_instruction(instr, &labels, &data_values); output[address as usize] = encoded.opcode; output[(address + 1) as usize] = encoded.arg1; output[(address + 2) as usize] = encoded.arg2; output[(address + 3) as usize] = encoded.result; address += INSTRUCTION_BIT_DEPTH; max_address = max_address.max(address); } ParsedLine::Directive(d) => { match d { Directive::Org(addr) => { if section == Section::Data { data_org = Some(addr); } address = addr; } Directive::Byte(value) => { output[address as usize] = value; address += 1; max_address = max_address.max(address); } Directive::Text => { section = Section::Text; } Directive::Data => { section = Section::Data; text_end = address; let data_start = match data_org { Some(addr) => addr, None => text_end, }; if data_start < text_end { panic!("Error: data section overlaps with text section"); } address = data_start; } } } ParsedLine::Label(_) | ParsedLine::Empty => {} } } let used = max_address as usize; // show assembly code if !output_debug { for (chunk_idx, inst) in output[..used].chunks(INSTRUCTION_BIT_DEPTH as usize).enumerate(){ if inst.len() < 4 { break; } println!("0b{:08b}", inst[0]); println!("0b{:08b}", inst[1]); println!("0b{:08b}", inst[2]); println!("0b{:08b}", inst[3]); println!(); } } // Debug if output_debug { println!("# Program size: {max_address} bytes"); println!("# ------------------------------\n"); println!("# bytes |:addr|text instruction"); for (chunk_idx, inst) in output[..used].chunks(INSTRUCTION_BIT_DEPTH as usize).enumerate(){ if inst.len() < 4 { break; } let base_addr = chunk_idx * INSTRUCTION_BIT_DEPTH as usize; let text_inst = decode(inst[0], inst[1], inst[2], inst[3]); println!("0b{:08b} #:{:03} |{}", inst[0],base_addr,text_inst); println!("0b{:08b} #:{:03}", inst[1],base_addr+1); println!("0b{:08b} #:{:03}", inst[2],base_addr+2); println!("0b{:08b} #:{:03}", inst[3],base_addr+3); println!(); } } } fn strip_comment(line: &str) -> &str { if let Some(pos) = line.find('#') { &line[..pos] } else { line } } fn parse_line(line: &str) -> ParsedLine { let line = line.trim(); let code = strip_comment(line).trim(); if code.is_empty() { return ParsedLine::Empty; } if code.ends_with(':') { let label = code.trim_end_matches(':').to_string(); return ParsedLine::Label(label); } let tokens: Vec<&str> = code .split([' ', ',']) .filter(|s| !s.is_empty()) .collect(); if tokens.is_empty() { return ParsedLine::Empty; } match tokens[0] { ".data" => ParsedLine::Directive(Directive::Data), ".text" => ParsedLine::Directive(Directive::Text), ".org" => { let value = parse_number(tokens[1]); ParsedLine::Directive(Directive::Org(value)) } ".byte" => { let value = parse_number(tokens[1]); ParsedLine::Directive(Directive::Byte(value)) }, "MOV" => parse_mov(&tokens), "PUSH" => parse_push(&tokens), "POP" => parse_pop(&tokens), "JMP" => { let label = tokens[1].to_string(); ParsedLine::Instruction(Instruction::Jmp { label }) }, "CJE"|"CJNE"|"CJL"|"CJLE"|"CJG"|"CJGE" => parse_cj(&tokens), "ADD" => parse_alu(&tokens, AluOp::Add), "SUB" => parse_alu(&tokens, AluOp::Sub), "AND" => parse_alu(&tokens, AluOp::And), "OR" => parse_alu(&tokens, AluOp::Or), "NOT" => parse_not(&tokens), "XOR" => parse_alu(&tokens, AluOp::Xor), "NAND" => parse_alu(&tokens, AluOp::Nand), "NOR" => parse_alu(&tokens, AluOp::Nor), "DIV" => parse_alu(&tokens, AluOp::Div), "CALL" => { let label = tokens[1].to_string(); ParsedLine::Instruction(Instruction::Call { label }) }, "RET" => ParsedLine::Instruction(Instruction::Ret), _ => panic!("Unknown instruction: {}", tokens[0]), } } // MOV: // * src регистров/RAM/INPUT/PC/Immediate Value // * dest регистр/RAM/OUTPUT/PC fn parse_mov(tokens: &[&str]) -> ParsedLine { let src = parse_operand(tokens[1], 128); let dst = parse_source( tokens[2]); ParsedLine::Instruction(Instruction::Mov { src, dst }) } fn parse_push(tokens: &[&str]) -> ParsedLine { let src = parse_operand(tokens[1], 128); ParsedLine::Instruction(Instruction::Push {src}) } fn parse_pop(tokens: &[&str]) -> ParsedLine { let dst= { match tokens[1] { "r0" | "r1" | "r2" | "r3" | "r4" | "r5" | "pc" | "io" | "ram" => { parse_source(tokens[1]) } _ => { panic!("Unknown source: {}", tokens[1]); } } }; ParsedLine::Instruction(Instruction::Pop { dst, }) } fn parse_cj(tokens: &[&str]) -> ParsedLine { let a = parse_operand(tokens[1], 128); let b = parse_operand(tokens[2], 64); let label = tokens[3].to_string(); let inst = { let inst = tokens[0]; match inst { "CJE" => {0b00100000}, // 32 IF_EQUAL "CJNE" => {0b00100001},// 33 IF_NOT_EQUAL "CJL" => {0b00100010}, // 34 IF_LESS "CJLE" => {0b00100011},// 35 IF_LESS_OR_EQUAL "CJG" => {0b00100100}, // 36 IF_GREATER "CJGE" => {0b00100101},// 37 IF_GREATER_OR_EQUAL _ => panic!("Unknown command:{}",inst) } }; ParsedLine::Instruction(Instruction::Cj {a, b, label, inst }) } fn parse_alu(tokens: &[&str], kind: AluOp) -> ParsedLine { let a = parse_operand(tokens[1], 128); let b = parse_operand(tokens[2], 64); let dst = parse_source(tokens[3]); match kind{ AluOp::Add => {ParsedLine::Instruction(Instruction::Add {a, b, dst })}, AluOp::Sub => {ParsedLine::Instruction(Instruction::Sub {a, b, dst })}, AluOp::And => {ParsedLine::Instruction(Instruction::And { a, b, dst })}, AluOp::Or => {ParsedLine::Instruction(Instruction::Or {a, b, dst })}, AluOp::Xor => {ParsedLine::Instruction(Instruction::Xor {a, b, dst })}, AluOp::Nand => {ParsedLine::Instruction(Instruction::Nand {a, b, dst })}, AluOp::Nor => {ParsedLine::Instruction(Instruction::Nor {a, b, dst })}, AluOp::Div => {ParsedLine::Instruction(Instruction::Div {a, b, dst })}, } } fn parse_not(tokens: &[&str]) -> ParsedLine { let a = parse_operand(tokens[1], 128); let dst = parse_source(tokens[2]); ParsedLine::Instruction(Instruction::Not {a, dst }) } fn parse_operand(s: &str, imm_flag: u8) -> SourceOperand { // [label] — адрес if s.starts_with('[') && s.ends_with(']') { let label = &s[1..s.len() - 1]; return SourceOperand::new(imm_flag, Operand::IndirectAddr(label.to_string())); } // регистр match s { "r0" | "r1" | "r2" | "r3" | "r4" | "r5" | "pc" | "io" | "ram" => { return SourceOperand::new(0, Operand::Source(parse_source(s))); } _ => {} } // число if let Ok(num) = s.parse::<u8>() { return SourceOperand::new(imm_flag, Operand::Immediate(num)); } // иначе это метка с константой SourceOperand::new(imm_flag, Operand::MemLabel(s.to_string())) } fn parse_source(name: &str) -> u8 { match name { "r0" => 0, "r1" => 1, "r2" => 2, "r3" => 3, "r4" => 4, "r5" => 5, "pc" => 6, "io" => 7, "ram" => 8, _ => panic!("Unknown register: {}", name), } } fn parse_number(s: &str) -> u8 { s.parse::<u8>().expect("Invalid number") } fn encode_src(src: SourceOperand, labels: &HashMap<String, u8>, data_values: &HashMap<String, u8>) -> u8 { match src.src { Operand::Source(s) => {s}, Operand::Immediate(v) => {v}, Operand::IndirectAddr(label) => { *labels.get(&label).expect("Unknown label") } Operand::MemLabel(label) => { // Если есть значение в data_values - берем его как immediate if let Some(val) = data_values.get(&label) { *val } else { // иначе используем адрес (если, например, jump) *labels.get(&label).expect("Unknown label") } } } } fn encode_instruction( instr: Instruction, labels: &HashMap<String, u8>, data_values: &HashMap<String, u8> ) -> EncodedInstruction { match instr { Instruction::Mov { src, dst } => EncodedInstruction { opcode: src.imm_flag|0b00001100, arg1: encode_src(src, labels, data_values), arg2: 0, result: dst, }, Instruction::Push { src } => EncodedInstruction { opcode: src.imm_flag|0b00010111, arg1: encode_src(src, labels, data_values), arg2: 0, result: 0b00001000, }, Instruction::Pop { dst } => EncodedInstruction { opcode: 0b00010101, arg1: 0, arg2: 0, result: dst, }, Instruction::Add { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Sub { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000001, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::And { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000010, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Or { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000011, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Not { a,dst } => EncodedInstruction { opcode: a.imm_flag|0b00000100, arg1: encode_src(a, labels, data_values), arg2: 0, result: dst, }, Instruction::Xor { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000101, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Nand { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000110, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Nor { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000111, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Div { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00010100, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Call { label} => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: 0b00001000, arg1: 0, arg2: 0, result: addr, } }, Instruction::Jmp { label } => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: 0b10001100, arg1: addr, arg2: 0, result: 0b00000110, } }, Instruction::Cj { a, b, label, inst} => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: a.imm_flag|b.imm_flag|inst|0b00100000, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: addr, } }, Instruction::Ret => EncodedInstruction { opcode: 0b00010000, arg1: 0, arg2: 0, result: 0, }, } } pub mod disassembly { fn reg_name(id: u8) -> &'static str { match id { 0 => "r0", 1 => "r1", 2 => "r2", 3 => "r3", 4 => "r4", 5 => "r5", 6 => "pc", 7 => "io", 8 => "ram", _ => "unk", } } fn decode_operand(flag: bool, value: u8) -> String { if flag { value.to_string() } else { reg_name(value).to_string() } } pub fn decode(opcode: u8, arg1: u8, arg2: u8, result: u8) -> String { let ai = opcode & 0b10000000 != 0; let bi = opcode & 0b01000000 != 0; let base = opcode & 0b00111111; let a = decode_operand(ai, arg1); let b = decode_operand(bi, arg2); let dst = reg_name(result); match base { 0b00000000 => format!("ADD {}, {}, {}", a, b, dst), 0b00000001 => format!("SUB {}, {}, {}", a, b, dst), 0b00000010 => format!("AND {}, {}, {}", a, b, dst), 0b00000011 => format!("OR {}, {}, {}", a, b, dst), 0b00000100 => format!("NOT {}, {}", a, dst), 0b00000101 => format!("XOR {}, {}, {}", a, b, dst), 0b00000110 => format!("NAND {}, {}, {}", a, b, dst), 0b00000111 => format!("NOR {}, {}, {}", a, b, dst), 0b00001100 => { let src = decode_operand(ai, arg1); let dst = reg_name(result); format!("MOV {}, {}", src, dst) }, 0b00010111 => { let src = decode_operand(ai, arg1); format!("PUSH :{}", src) }, 0b00010101 => { let dst = reg_name(result); format!("POP {}", dst) }, 0b00010100 => format!("DIV {}, {}, {}", a, b, dst), 0b00001000 => { format!("CALL :{:03}", result) }, 0b00010000 => "RET".to_string(), 0b00100000 => format!("CJE {}, {}, :{:03}", a, b, result), 0b00100001 => format!("CJNE {}, {}, :{:03}", a, b, result), 0b00100010 => format!("CJL {}, {}, :{:03}", a, b, result), 0b00100011 => format!("CJLE {}, {}, :{:03}", a, b, result), 0b00100100 => format!("CJG {}, {}, :{:03}", a, b, result), 0b00100101 => format!("CJGE {}, {}, :{:03}", a, b, result), _ => format!( "Unknown opcode={:08b} arg1={} arg2={} dst={:08}", opcode, arg1, arg2, result ), } } } }
Assembly:
use disassembly::decode; use std::collections::HashMap; #[derive(Debug)] enum ParsedLine { Label(String), Instruction(Instruction), Directive(Directive), Empty, } #[derive(Debug)] enum Directive { Data, Text, Org(u8), Byte(u8), } #[derive(Debug)] enum Operand { Source(u8), Immediate(u8), IndirectAddr(String), MemLabel(String), } #[derive(Debug)] struct SourceOperand{ imm_flag: u8, src: Operand } impl SourceOperand { pub fn new(imm_flag: u8, src: Operand) -> Self{ Self{imm_flag, src} } } #[derive(Debug)] enum Instruction { Mov { src: SourceOperand, dst: u8 }, Push { src: SourceOperand}, Pop { dst: u8 }, Jmp { label: String }, Cj { a: SourceOperand, b: SourceOperand, label: String, inst: u8 }, Add { a: SourceOperand, b: SourceOperand, dst: u8 }, Sub { a: SourceOperand, b: SourceOperand, dst: u8 }, And { a: SourceOperand, b: SourceOperand, dst: u8 }, Or { a: SourceOperand, b: SourceOperand, dst: u8 }, Not { a: SourceOperand, dst: u8 }, Xor { a: SourceOperand, b: SourceOperand, dst: u8 }, Nand { a: SourceOperand, b: SourceOperand, dst: u8 }, Nor { a: SourceOperand, b: SourceOperand, dst: u8 }, Div { a: SourceOperand, b: SourceOperand, dst: u8 }, Call { label: String }, Ret, } #[derive(Debug)] struct EncodedInstruction { opcode: u8, arg1: u8, arg2: u8, result: u8, } enum AluOp { Add, Sub, And, Or, Xor, Nand, Nor, Div, } #[derive(Clone, Copy, PartialEq)] enum Section { Text, Data, } static INPUT_ASM_CODE: &str = " jump_start: comment MOV 1, r3 # comment MOV 2, ram MOV 3, pc MOV 4, io MOV r1, r2 MOV ram, r2 MOV ram, ram MOV ram, pc MOV pc, ram MOV io, ram MOV io, pc MOV io, io PUSH r0 PUSH 255 PUSH ram PUSH io PUSH pc POP r0 POP ram POP io POP pc ADD 5, r2, r3 ADD r1, r2, r3 SUB 5, r2, r3 SUB r1, r2, r3 AND 5, r2, r3 AND r1, r2, r3 OR 5, r2, r3 OR r1, r2, r3 NOT 5, r3 NOT r1, r3 XOR 5, r2, r3 XOR r1, r2, r3 NAND 5, r2, r3 NAND r1, r2, r3 NOR 5, r2, r3 NOR r1, r2, r3 DIV 5, r2, r3 DIV r1, r2, r3 CALL jump_here CJE 5, 4, jump_start CJNE 5, 4, jump_start CJL 5, 4, jump_start CJLE 5, 4, jump_start CJG 5, 4, jump_start CJGE 5, 4, jump_start JMP jump_start jump_here: NOR 5, r2, r3 NOR r1, r2, r3 RET "; fn main() { const INSTRUCTION_BIT_DEPTH: u8 = 4; let input = INPUT_ASM_CODE; let lines: Vec<&str> = input.lines().collect(); let mut data_values: HashMap<String, u8> = HashMap::new(); // PASS 1: collect labels let mut labels = HashMap::new(); let mut address: u8 = 0; let mut last_label: Option<String> = None; let mut section = Section::Text; let mut text_end: u8 = 0; let mut data_org: Option<u8> = None; for line in &lines { match parse_line(line) { ParsedLine::Label(name) => { labels.insert(name.clone(), address); last_label = Some(name); } ParsedLine::Instruction(_) => { address = address.checked_add(INSTRUCTION_BIT_DEPTH) .unwrap_or_else(|| panic!("Address overflow! \nThe maximum address value is 255. \nCurrent address:{} + depth:{} > 255",address,INSTRUCTION_BIT_DEPTH)); } ParsedLine::Directive(d) => { match d { Directive::Org(addr) => { if section == Section::Data { data_org = Some(addr); if addr < text_end { panic!("Error: data section overlaps with text section"); } } address = addr; } Directive::Byte(value) => { if section == Section::Data { if let Some(label) = &last_label { data_values.insert(label.clone(), value); } else { panic!(".byte without label in data section"); } } address = address.checked_add(1) .unwrap_or_else(|| panic!("Address overflow! \nThe maximum address value is 255. \nCurrent address:{} + 1 > 255",address)); } Directive::Text => { section = Section::Text; } Directive::Data => { section = Section::Data; // фиксируем конец текста text_end = address; let data_start = match data_org { Some(addr) => addr, None => text_end, }; if data_start < text_end { panic!("Error: data section overlaps with text section"); } address = data_start; } } } ParsedLine::Empty => {} } } // Debug label addresses println!("# label addresses:"); for (key, value) in &labels { println!("# {}: {:03}", key, value); } println!("# ------------------------------"); // PASS 2: encode instructions let mut output: Vec<u8> = vec![0; 256]; let mut max_address: u8 = 0; address = 0; let mut section = Section::Text; let mut text_end: u8 = 0; let mut data_org: Option<u8> = None; for line in &lines { match parse_line(line) { ParsedLine::Instruction(instr) => { let encoded = encode_instruction(instr, &labels, &data_values); output[address as usize] = encoded.opcode; output[(address + 1) as usize] = encoded.arg1; output[(address + 2) as usize] = encoded.arg2; output[(address + 3) as usize] = encoded.result; address += INSTRUCTION_BIT_DEPTH; max_address = max_address.max(address); } ParsedLine::Directive(d) => { match d { Directive::Org(addr) => { if section == Section::Data { data_org = Some(addr); } address = addr; } Directive::Byte(value) => { output[address as usize] = value; address += 1; max_address = max_address.max(address); } Directive::Text => { section = Section::Text; } Directive::Data => { section = Section::Data; text_end = address; let data_start = match data_org { Some(addr) => addr, None => text_end, }; if data_start < text_end { panic!("Error: data section overlaps with text section"); } address = data_start; } } } ParsedLine::Label(_) | ParsedLine::Empty => {} } } let used = max_address as usize; // show assembly code /* for (chunk_idx, inst) in output[..used].chunks(INSTRUCTION_BIT_DEPTH as usize).enumerate(){ if inst.len() < 4 { break; } println!("0b{:08b}", inst[0]); println!("0b{:08b}", inst[1]); println!("0b{:08b}", inst[2]); println!("0b{:08b}", inst[3]); println!(); } */ // Debug println!("# Program size: {max_address} bytes"); println!("# ------------------------------\n"); println!("# bytes |:addr|text instruction"); for (chunk_idx, inst) in output[..used].chunks(INSTRUCTION_BIT_DEPTH as usize).enumerate(){ if inst.len() < 4 { break; } let base_addr = chunk_idx * INSTRUCTION_BIT_DEPTH as usize; let text_inst = decode(inst[0], inst[1], inst[2], inst[3]); println!("0b{:08b} #:{:03} |{}", inst[0],base_addr,text_inst); println!("0b{:08b} #:{:03}", inst[1],base_addr+1); println!("0b{:08b} #:{:03}", inst[2],base_addr+2); println!("0b{:08b} #:{:03}", inst[3],base_addr+3); println!(); } } fn strip_comment(line: &str) -> &str { if let Some(pos) = line.find('#') { &line[..pos] } else { line } } fn parse_line(line: &str) -> ParsedLine { let line = line.trim(); let code = strip_comment(line).trim(); if code.is_empty() { return ParsedLine::Empty; } if code.ends_with(':') { let label = code.trim_end_matches(':').to_string(); return ParsedLine::Label(label); } let tokens: Vec<&str> = code .split([' ', ',']) .filter(|s| !s.is_empty()) .collect(); if tokens.is_empty() { return ParsedLine::Empty; } match tokens[0] { ".data" => ParsedLine::Directive(Directive::Data), ".text" => ParsedLine::Directive(Directive::Text), ".org" => { let value = parse_number(tokens[1]); ParsedLine::Directive(Directive::Org(value)) } ".byte" => { let value = parse_number(tokens[1]); ParsedLine::Directive(Directive::Byte(value)) }, "MOV" => parse_mov(&tokens), "PUSH" => parse_push(&tokens), "POP" => parse_pop(&tokens), "JMP" => { let label = tokens[1].to_string(); ParsedLine::Instruction(Instruction::Jmp { label }) }, "CJE"|"CJNE"|"CJL"|"CJLE"|"CJG"|"CJGE" => parse_cj(&tokens), "ADD" => parse_alu(&tokens, AluOp::Add), "SUB" => parse_alu(&tokens, AluOp::Sub), "AND" => parse_alu(&tokens, AluOp::And), "OR" => parse_alu(&tokens, AluOp::Or), "NOT" => parse_not(&tokens), "XOR" => parse_alu(&tokens, AluOp::Xor), "NAND" => parse_alu(&tokens, AluOp::Nand), "NOR" => parse_alu(&tokens, AluOp::Nor), "DIV" => parse_alu(&tokens, AluOp::Div), "CALL" => { let label = tokens[1].to_string(); ParsedLine::Instruction(Instruction::Call { label }) }, "RET" => ParsedLine::Instruction(Instruction::Ret), _ => panic!("Unknown instruction: {}", tokens[0]), } } // MOV: // * src регистров/RAM/INPUT/PC/Immediate Value // * dest регистр/RAM/OUTPUT/PC fn parse_mov(tokens: &[&str]) -> ParsedLine { let src = parse_operand(tokens[1], 128); let dst = parse_source( tokens[2]); ParsedLine::Instruction(Instruction::Mov { src, dst }) } fn parse_push(tokens: &[&str]) -> ParsedLine { let src = parse_operand(tokens[1], 128); ParsedLine::Instruction(Instruction::Push {src}) } fn parse_pop(tokens: &[&str]) -> ParsedLine { let dst= { match tokens[1] { "r0" | "r1" | "r2" | "r3" | "r4" | "r5" | "pc" | "io" | "ram" => { parse_source(tokens[1]) } _ => { panic!("Unknown source: {}", tokens[1]); } } }; ParsedLine::Instruction(Instruction::Pop { dst, }) } fn parse_cj(tokens: &[&str]) -> ParsedLine { let a = parse_operand(tokens[1], 128); let b = parse_operand(tokens[2], 64); let label = tokens[3].to_string(); let inst = { let inst = tokens[0]; match inst { "CJE" => {0b00100000}, // 32 IF_EQUAL "CJNE" => {0b00100001},// 33 IF_NOT_EQUAL "CJL" => {0b00100010}, // 34 IF_LESS "CJLE" => {0b00100011},// 35 IF_LESS_OR_EQUAL "CJG" => {0b00100100}, // 36 IF_GREATER "CJGE" => {0b00100101},// 37 IF_GREATER_OR_EQUAL _ => panic!("Unknown command:{}",inst) } }; ParsedLine::Instruction(Instruction::Cj {a, b, label, inst }) } fn parse_alu(tokens: &[&str], kind: AluOp) -> ParsedLine { let a = parse_operand(tokens[1], 128); let b = parse_operand(tokens[2], 64); let dst = parse_source(tokens[3]); match kind{ AluOp::Add => {ParsedLine::Instruction(Instruction::Add {a, b, dst })}, AluOp::Sub => {ParsedLine::Instruction(Instruction::Sub {a, b, dst })}, AluOp::And => {ParsedLine::Instruction(Instruction::And { a, b, dst })}, AluOp::Or => {ParsedLine::Instruction(Instruction::Or {a, b, dst })}, AluOp::Xor => {ParsedLine::Instruction(Instruction::Xor {a, b, dst })}, AluOp::Nand => {ParsedLine::Instruction(Instruction::Nand {a, b, dst })}, AluOp::Nor => {ParsedLine::Instruction(Instruction::Nor {a, b, dst })}, AluOp::Div => {ParsedLine::Instruction(Instruction::Div {a, b, dst })}, } } fn parse_not(tokens: &[&str]) -> ParsedLine { let a = parse_operand(tokens[1], 128); let dst = parse_source(tokens[2]); ParsedLine::Instruction(Instruction::Not {a, dst }) } fn parse_operand(s: &str, imm_flag: u8) -> SourceOperand { // [label] — адрес if s.starts_with('[') && s.ends_with(']') { let label = &s[1..s.len() - 1]; return SourceOperand::new(imm_flag, Operand::IndirectAddr(label.to_string())); } // регистр match s { "r0" | "r1" | "r2" | "r3" | "r4" | "r5" | "pc" | "io" | "ram" => { return SourceOperand::new(0, Operand::Source(parse_source(s))); } _ => {} } // число if let Ok(num) = s.parse::<u8>() { return SourceOperand::new(imm_flag, Operand::Immediate(num)); } // иначе это метка с константой SourceOperand::new(imm_flag, Operand::MemLabel(s.to_string())) } fn parse_source(name: &str) -> u8 { match name { "r0" => 0, "r1" => 1, "r2" => 2, "r3" => 3, "r4" => 4, "r5" => 5, "pc" => 6, "io" => 7, "ram" => 8, _ => panic!("Unknown register: {}", name), } } fn parse_number(s: &str) -> u8 { s.parse::<u8>().expect("Invalid number") } fn encode_src(src: SourceOperand, labels: &HashMap<String, u8>, data_values: &HashMap<String, u8>) -> u8 { match src.src { Operand::Source(s) => {s}, Operand::Immediate(v) => {v}, Operand::IndirectAddr(label) => { *labels.get(&label).expect("Unknown label") } Operand::MemLabel(label) => { // Если есть значение в data_values - берем его как immediate if let Some(val) = data_values.get(&label) { *val } else { // иначе используем адрес (если, например, jump) *labels.get(&label).expect("Unknown label") } } } } fn encode_instruction( instr: Instruction, labels: &HashMap<String, u8>, data_values: &HashMap<String, u8> ) -> EncodedInstruction { match instr { Instruction::Mov { src, dst } => EncodedInstruction { opcode: src.imm_flag|0b00001100, arg1: encode_src(src, labels, data_values), arg2: 0, result: dst, }, Instruction::Push { src } => EncodedInstruction { opcode: src.imm_flag|0b00010111, arg1: encode_src(src, labels, data_values), arg2: 0, result: 0b00001000, }, Instruction::Pop { dst } => EncodedInstruction { opcode: 0b00010101, arg1: 0, arg2: 0, result: dst, }, Instruction::Add { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Sub { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000001, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::And { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000010, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Or { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000011, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Not { a,dst } => EncodedInstruction { opcode: a.imm_flag|0b00000100, arg1: encode_src(a, labels, data_values), arg2: 0, result: dst, }, Instruction::Xor { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000101, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Nand { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000110, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Nor { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00000111, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Div { a, b, dst } => EncodedInstruction { opcode: a.imm_flag|b.imm_flag|0b00010100, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: dst, }, Instruction::Call { label} => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: 0b00001000, arg1: 0, arg2: 0, result: addr, } }, Instruction::Jmp { label } => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: 0b10001100, arg1: addr, arg2: 0, result: 0b00000110, } }, Instruction::Cj { a, b, label, inst} => { let addr = *labels .get(&label) .expect("Unknown label"); EncodedInstruction { opcode: a.imm_flag|b.imm_flag|inst|0b00100000, arg1: encode_src(a, labels, data_values), arg2: encode_src(b, labels, data_values), result: addr, } }, Instruction::Ret => EncodedInstruction { opcode: 0b00010000, arg1: 0, arg2: 0, result: 0, }, } } pub mod disassembly { fn reg_name(id: u8) -> &'static str { match id { 0 => "r0", 1 => "r1", 2 => "r2", 3 => "r3", 4 => "r4", 5 => "r5", 6 => "pc", 7 => "io", 8 => "ram", _ => "unk", } } fn decode_operand(flag: bool, value: u8) -> String { if flag { value.to_string() } else { reg_name(value).to_string() } } pub fn decode(opcode: u8, arg1: u8, arg2: u8, result: u8) -> String { let ai = opcode & 0b10000000 != 0; let bi = opcode & 0b01000000 != 0; let base = opcode & 0b00111111; let a = decode_operand(ai, arg1); let b = decode_operand(bi, arg2); let dst = reg_name(result); match base { 0b00000000 => format!("ADD {}, {}, {}", a, b, dst), 0b00000001 => format!("SUB {}, {}, {}", a, b, dst), 0b00000010 => format!("AND {}, {}, {}", a, b, dst), 0b00000011 => format!("OR {}, {}, {}", a, b, dst), 0b00000100 => format!("NOT {}, {}", a, dst), 0b00000101 => format!("XOR {}, {}, {}", a, b, dst), 0b00000110 => format!("NAND {}, {}, {}", a, b, dst), 0b00000111 => format!("NOR {}, {}, {}", a, b, dst), 0b00001100 => { let src = decode_operand(ai, arg1); let dst = reg_name(result); format!("MOV {}, {}", src, dst) }, 0b00010111 => { let src = decode_operand(ai, arg1); format!("PUSH :{}", src) }, 0b00010101 => { let dst = reg_name(result); format!("POP {}", dst) }, 0b00010100 => format!("DIV {}, {}, {}", a, b, dst), 0b00001000 => { format!("CALL :{:03}", result) }, 0b00010000 => "RET".to_string(), 0b00100000 => format!("CJE {}, {}, :{:03}", a, b, result), 0b00100001 => format!("CJNE {}, {}, :{:03}", a, b, result), 0b00100010 => format!("CJL {}, {}, :{:03}", a, b, result), 0b00100011 => format!("CJLE {}, {}, :{:03}", a, b, result), 0b00100100 => format!("CJG {}, {}, :{:03}", a, b, result), 0b00100101 => format!("CJGE {}, {}, :{:03}", a, b, result), _ => format!( "Unknown opcode={:08b} arg1={} arg2={} dst={:08}", opcode, arg1, arg2, result ), } } }
Следующий логический шаг
important
Следующий логический шаг для создания практичного инструмента под LEG архитектуру:
- A. Создать свой мини-язык высокого уровня и компилятор в LEG-ассемблер.
- B. Создать компилятор subset C/Rust/Python в LEG-ассемблер, если цель - изучение компиляторов.
- C. Понять реальные архитектуры:
- RISC-V (RISCV64GC) - современная открытая архитектура (ESP32-C3/C6/H2, Arduino Portenta C33). Spike - официальный симулятор RISC‑V, что бы не покупать ESP32-C3 или FPGA. (создание арх. RV32I на языке VHDL)
- MIPS - классическая учебная RISC-архитектура
- 6502 - ретро-архитектуры 8-битных процессоров
- ARM - для мобильных и встраиваемых устройств
- x86-64 - для настольных ПК и серверов
- ARM Cortex-M - стандарт embedded-мира (Raspberry Pi)
- AVR - для Arduino Uno/Nano