Visual Studio Code расширение: C/C++ Extension Pack
|
|
|
|
Язык С разрабатывался с 1969 года по 1973 год Деннисом Ритчи (Dennis Ritchie), сотрудником Bell Laboratories. Национальный институт стандартизации США (American National Standards Institute, ANSI) утвердил стандарт ANSI С в 1989 году.
Язык С был тесно связан с операционной системой Unix. Он разрабатывался с самого начала как язык системного программирования для Unix. Большая часть ядра, а также все вспомогательные инструменты и библиотеки были написаны на С.
С разрабатывался для решения практических задач. Первоначально его целью была реализация операционной системы Unix. Потом обнаружилось, что на нем можно писать любые программы, потому что сам язык давал такую возможность.
|
|
Application Binary Interface (ABI) Бинарный интерфейс приложения
|
ABI критичен в C потому что C работает напрямую с бинарными файлами и железом.
Если ABI не совпадет между объектными файлами → программа крашнется.
Если API — это правила вызова функций в исходном коде,
то ABI — это правила вызова функций в бинарном коде.
ABI определяет:
1. Как функции передают аргументы
- где лежат параметры → в регистрах или на стеке
- какие регистры должен сохранять вызывающий
- как возвращается значение
- какой стек создаётся
2. Как устроена память
- выравнивание типов
- размер struct / union
- порядок полей
- правила упаковки битовых полей
3. Как работает связка между разными объектными файлами
- формат ELF / Mach-O / PE
- имена символов
- соглашение о ленивом связывании
Примеры
1. Компилятор превращает вызов в машинный код
Например код printf("Hello %d\n", 42);
Компилятор не знает ничего о printf кроме его сигнатуры.
Но он обязан следовать ABI платформы.
Допустим: Linux x86_64, System V ABI (самый распространённый).
ABI говорит:
- 1-й аргумент → RDI
- 2-й аргумент → RSI
- 3-й аргумент → RDX
- 4-й → RCX
- 5-й → R8
- 6-й → R9
- rest → стек
Компилятор выделит строку в сегменте .rodata:
.rodata:
.LC0: "Hello %d\n\0"
И сгенерирует код (упрощённо):
lea rdi, [rip + .LC0] ; 1-й аргумент → RDI
mov esi, 42 ; 2-й аргумент → RSI
xor eax, eax ; для variadic функций — очистить AL
call printf@PLT
2. Вызов printf через PLT/GOT
ABI также определяет динамическую линковку.
В ELF-бинаре вызов printf выглядит так:
call printf@PLT
3. Что делает внутренняя реализация printf
Теперь мы в libc.
Сигнатура:
int printf(const char* fmt, ...);
ABI передал регистры:
- RDI = pointer to "Hello %d\n"
- RSI = 42
- AL = 0 (число float-аргументов)
Внутри printf есть:
int printf(const char* fmt, ...) {
va_list ap;
va_start(ap, fmt);
int r = vfprintf(stdout, fmt, ap);
va_end(ap);
return r;
}
С помощью ABI-определённых правил va_start() знает:
- где на стеке лежат дополнительные аргументы
- какие аргументы лежат в регистрах
Даже само перемещение по аргументам работает благодаря ABI.
|
|
|
C99 — оптимален
gcc -std=c89 main.c
gcc -std=c99 main.c
gcc -std=c11 main.c
gcc -std=c17 main.c
gcc -std=c2x main.c
Также есть расширенные варианты от GNU:
-std=gnu89 C89 + GNU расширения
-std=gnu99 C99 + GNU расширения (по умолчанию в старых GCC)
-std=gnu11 C11 + GNU расширения (дефолт в современных GCC)
-std=gnu17 C17 + расширения
-std=gnu23 C23 + расширения
GNU-расширения — это всякие удобные вещи вроде asm, typeof, __attribute__, #include_next и т.д.,
которые не входят в “чистый” стандарт ISO C.
Эти стандарты — это не отдельные версии языка, а C + расширения от GCC (GNU C extensions).
То есть:
-std=gnu17 = -std=c17 + несколько нестандартных возможностей, специфичных для GCC.
|
|
|
| Версия | Основные изменения |
|---|
| C89/C90 | Базовый стандарт |
| C99 | inline, //, stdint.h, for (int i=0;...) |
| C11 | _Thread_local, _Atomic, static_assert |
| C17 | уточнение UB, улучшения совместимости |
| C23 | новые типы (char8_t), nullptr, улучшения макросов |
Почему C99 — оптимален:
- Совместим почти с любым контроллером (AVR, STM32, ESP, PIC, MSP430, ARM Cortex-M).
- Включает всё, что реально нужно:
- stdint.h — строгие типы (uint8_t, uint32_t).
- stdbool.h — тип bool.
- inline — функции для быстрого вызова.
- for (int i=0;...) — нормальный синтаксис.
- snprintf, va_copy, и т.д.
- Используется большинством стандартов безопасности:
- MISRA C:2012 базируется именно на C99.
- Отлично работает и для bare metal, и для RTOS-проектов (FreeRTOS, Zephyr).
Используйте C89/C90 если работаете со старым контроллером / компилятором (Keil C51, MPLAB XC8)
Можно C11/C17 — ради _Static_assert, _Generic, _Thread_local. Если используете современный ARMCLANG, GCC 12+ и RTOS
Используйте C99, соблюдайте MISRA C:2012. Если проект должен пройти MISRA сертификацию
Используйте C17 или C23 Если пишете host tools (утилиты, анализаторы) под ПК
|
|
Процесс создания исполняемого файла
(Файлы объектного кода, исполняемые файлы и библиотеки)
|
Трансляция выполняется в четыре этапа. Совокупность программ, выполняющих эти четыре этапа (препроцессор, компилятор, ассемблер и компоновщик), называется системой компиляции.
gcc -о hello hello.с
1. Этап препроцессора (или этап предварительной обработки). Препроцессор (срр)
изменяет исходную программу в соответствии с директивами, которые начинаются с символа «#». Например, директива #inciude <stdio.h> заставляет препроцессор прочитать содержимое системного заголовочного файла stdio.h и вставить его непосредственно в текст программы. В результате получается другая программа на языке С, обычно с расширением .i (например hello.i)
/* hello.c */
#include <stdio.h>
int main(){
printf("hello, world\n");
return 0;
}
2. Этап компиляции. Компилятор (ccl) транслирует текстовый файл hello.i в текстовый файл hello.s, который содержит программу на языке ассемблера. Польза языка ассемблера прежде всего в том, что он представляет общий выходной язык для компиляторов разных языков высокого уровня.
main:
subq $8, %rsp
movl $.LC0, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
3. Этап ассемблирования. Ассемблер (as) транслирует файл hello.s в машинные инструкции, упаковывает их в форму, известную как перемещаемый объектный код, и запоминает результат в объектном файле hello.о. Файл hello.о – это двоичный файл, содержащий байты, которые кодируют машинные инструкции, составляющие функцию main.
4. Этап компоновки. Обратите внимание, что наша программа hello вызывает функцию printf из стандартной библиотеки С, которая поставляется в комплекте с любым компилятором языка С. Функция printf находится в отдельном предварительно скомпилированном объектном файле с именем printf.о, который тем или иным способом должен быть объединен с нашей программой hello.о. Это объединение осуществляет компоновщик (ld). В результате получается выполняемый объектный файл (или просто выполняемый файл), готовый к загрузке и выполнению системой.
1. Объектный код - мы его получаем после компилятора, он создает из нашей программы объектный файл с машинным кодом но без дополнительного кода запуска на конкретной ОС.
2. Код запуска - добавляется компоновщиком для целевой ОС
3. Библиотечный код (C standard library) - набор заранее скомпилированных функций, предоставляемых реализацией языка. Когда мы устанавливаем компилятор (например GCC, Clang, ARMCC, Keil, IAR и т. д.), вместе с ним ставится реализация стандартной библиотеки.
Эта библиотека живёт в виде скомпилированных объектных файлов и заголовков.
Роль компоновщика заключается в сборе вместе этих трех элементов — объектного кода, стандартного кода запуска для установленной системы и библиотечного кода — и последующем их помещении в отдельный файл, который называется исполняемым. Что касается библиотечного кода, то компоновщик извлекает только код, который необходим для функций, вызываемых из библиотеки.
Когда мы устанавливаем GCC, мы обычно устанавливаешь целый toolchain, а не “голый” компилятор.
Что такое toolchain — это комплект: компилятор + линкер + ассемблер + библиотеки.
Toolchain — это среда для сборки программ под конкретную платформу.
Она включает несколько компонентов:
| Компонент | Что делает | Пример |
|---|
| compiler (gcc) | Компилирует .c → .o | arm-none-eabi-gcc |
| assembler (as) | Собирает .s → .o | arm-none-eabi-as |
| linker (ld) | Собирает .o + библиотеки → .elf | arm-none-eabi-ld |
| libc | Стандартная библиотека C (printf, memcpy, malloc) | newlib, glibc, musl |
| libm | Математические функции (sin, pow) | часть libc |
| startup code | Код запуска _start, crt0.o | идёт в комплекте |
| headers | Файлы #include <stdio.h> | из libc |
Что именно лежит в этих файлах:
| Файл | Что содержит | Откуда берётся |
|---|
| libc.a | Стандартная библиотека C — printf, malloc, fopen, strlen, и т.д. | из glibc, musl, newlib или аналогов |
| libm.a | Математические функции (sin, pow, log) | часть glibc или newlib |
| libpthread.a | Потоки POSIX (pthread_create, pthread_join) | glibc (или отдельная реализация) |
| libgcc.a | Вспомогательные функции, нужные самому компилятору (__divsi3, __muldf3, __udivdi3, обработка исключений в C++) | встроено в GCC |
| libc.so / libc.a | может быть статической (.a) или динамической (.so) | зависит от сборки |
Из чего состоит стандартная библиотека C (C standard library)
| Заголовок | Что реализует |
|---|
<stdio.h> | Ввод/вывод (printf, scanf, fopen и т.д.) |
<stdlib.h> | Память (malloc, free), случайные числа, конверсии |
<string.h> | Строки (memcpy, strcmp, strlen) |
<math.h> | Математика (sin, pow, sqrt) |
<time.h> | Дата, время |
<ctype.h> | Проверка символов (isdigit, isalpha) |
<errno.h> | Ошибки исполнения |
<assert.h> | Диагностика |
<stddef.h>, <stdint.h> | Определения базовых типов |
В <stdlib.h> определены базовые служебные функции, включая:
- Управление памятью: malloc, calloc, realloc, free.
- Преобразование строк: atoi, atof, strtol.
- Управление процессами: exit, abort, getenv, system.
- Разное: abs, div, rand, atexit.
Поэтому подключенная библиотека stdio.h берется из toolchain системы: Однако фактический код функции находится в библиотечном файле предварительно скомпилированного кода, а не в заголовочном файле. Компоновщик, являющийся компонентом компилятора, позаботится о поиске необходимого библиотечного кода. Символ # в первой строке означает, что до передачи компилятору она должна обрабатываться препроцессором.
#include <stdio.h>
int main(void) {
printf("Hello, world!\n");
return 0;
}
|
|
|
<img src="/snippet-stash/images/base_c_a805e40832e1256e_content_aeeb.png" alt="..." style="width: 90%; height: auto;">
|
|
|
В embedded-мире часто нет “полноценной” libc.
Тогда применяются специальные минималистичные реализации стандартной библиотеки C (C standard library), например:
| Библиотека | Используется в | Особенности |
|---|
| newlib | ARM GCC, ESP32 | Полная POSIX-совместимая libc |
| newlib-nano | ARM Cortex-M | Облегчённая версия без тяжёлых функций |
| uClibc | Linux embedded | Лёгкая альтернатива glibc |
| musl | Linux embedded | Современная, быстрая |
| avr-libc | AVR (Atmega) | Специально для 8-битных контроллеров |
| picolibc | ARM, RISC-V | Новая малогабаритная libc для микроконтроллеров |
| libnosys.a | ARM GCC | Заглушки системных вызовов (например, _write) |
Пример:
- printf объявлен в
<stdio.h>
- Реализован в libc.a (newlib)
- printf вызывает write()
- write() вызывает _write() (твой драйвер UART)
- Символы реально уходят в UART или терминал
На микроконтроллере нет Linux, значит, нет syscall, printf не знает, куда писать, malloc не знает, где память.
newlib даёт “скелет” — функции стандартной библиотеки, но требует, чтобы вы реализовали системные вызовы
Если вы работаете с микроконтроллерами, у вас может быть cross-compiler — компилятор, который собирает код не под вашу ОС, а под целевую платформу.
$ arm-none-eabi-gcc --version
$ riscv-none-elf-gcc --version
$ avr-gcc --version
|
|
|
$ gcc --version
gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0
Copyright (C) 2023 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
|
Узнать target triple — описание того, для какой платформы компилятор собирает код
|
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-linux-gnu/13/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 13.3.0-6ubuntu2~24.04' --with-bugurl=file:///usr/share/doc/gcc-13/README.Bugs --enable-languages=c,ada,c++,go,d,fortran,objc,obj-c++,m2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-13 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/libexec --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-libstdcxx-backtrace --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --enable-libphobos-checking=release --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --enable-cet --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-13-fG75Ri/gcc-13-13.3.0/debian/tmp-nvptx/usr,amdgcn-amdhsa=/build/gcc-13-fG75Ri/gcc-13-13.3.0/debian/tmp-gcn/usr --enable-offload-defaulted --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu --with-build-config=bootstrap-lto-lean --enable-link-serialization=2
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 13.3.0 (Ubuntu 13.3.0-6ubuntu2~24.04)
|
|
Узнать, какая libc используется
Это указывает, какая именно библиотека C подключается (glibc, newlib и т.д.)
|
Работает только для native Linux
$ ldd --version
ldd (Ubuntu GLIBC 2.39-0ubuntu8.6) 2.39
Copyright (C) 2024 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
|
|
Выбор компилятора GCC vs Clang
|
| Задача | Что выбрать |
|---|
| Embedded / bare-metal (ARM, RISC-V, STM32 и т.п.) | GCC (arm-none-eabi-gcc) — стандарт де-факто |
| Системное программирование под Linux / ядро / драйверы | GCC — лучше совместим с kernel и toolchain |
| Современная разработка под macOS / iOS / Android / LLVM-проекты | Clang — там он встроен по умолчанию |
| Разработка под Linux user-space (CLI, серверы) | Любой — Clang чуть быстрее компилирует, GCC чуть быстрее оптимизирует |
| Статический анализ, codegen, IDE-интеграция (VSCode, JetBrains) | Clang — API и диагностика лучше |
| Разработка под микроконтроллеры / RTOS | GCC (Clang здесь пока сырый) |
|
|
|
|
|
Компиляция с подробностями:
$ gcc -std=c99 main.c -v
Запуск исполняемого файла:
$ ./a.out
Компиляция с указанием имени целевого файла:
$ gcc -std=c99 main.c -o my_program.out
$ ./my_program.out
|
Компоновщик удаляет промежуточный обьектный файл с расширением .o при компиляции исполняемого файла, но только если программа состояла из одного исходного файла, если было больше то промежуточный объектный файл останется.
Файл main.c:
#include <stdio.h>
int main(void){
printf("Привет МИР\n");
return 0;
}
Компиляция с подробностями:
$ gcc main.c -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-linux-gnu/13/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none:amdgcn-amdhsa
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 13.3.0-6ubuntu2~24.04' --with-bugurl=file:///usr/share/doc/gcc-13/README.Bugs --enable-languages=c,ada,c++,go,d,fortran,objc,obj-c++,m2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-13 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/libexec --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-bootstrap --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-libstdcxx-backtrace --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --enable-libphobos-checking=release --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --enable-cet --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-13-fG75Ri/gcc-13-13.3.0/debian/tmp-nvptx/usr,amdgcn-amdhsa=/build/gcc-13-fG75Ri/gcc-13-13.3.0/debian/tmp-gcn/usr --enable-offload-defaulted --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu --with-build-config=bootstrap-lto-lean --enable-link-serialization=2
Thread model: posix
Supported LTO compression algorithms: zlib zstd
gcc version 13.3.0 (Ubuntu 13.3.0-6ubuntu2~24.04)
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
/usr/libexec/gcc/x86_64-linux-gnu/13/cc1 -quiet -v -imultiarch x86_64-linux-gnu main.c -quiet -dumpdir a- -dumpbase main.c -dumpbase-ext .c -mtune=generic -march=x86-64 -version -fasynchronous-unwind-tables -fstack-protector-strong -Wformat -Wformat-security -fstack-clash-protection -fcf-protection -o /tmp/cc2iDeVu.s
GNU C17 (Ubuntu 13.3.0-6ubuntu2~24.04) version 13.3.0 (x86_64-linux-gnu)
compiled by GNU C version 13.3.0, GMP version 6.3.0, MPFR version 4.2.1, MPC version 1.3.1, isl version isl-0.26-GMP
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/local/include/x86_64-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/13/include-fixed/x86_64-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/13/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/13/../../../../x86_64-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/13/include
/usr/local/include
/usr/include/x86_64-linux-gnu
/usr/include
End of search list.
Compiler executable checksum: 38987c28e967c64056a6454abdef726e
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a-'
as -v --64 -o /tmp/cciIqt6W.o /tmp/cc2iDeVu.s
GNU assembler version 2.42 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.42
COMPILER_PATH=/usr/libexec/gcc/x86_64-linux-gnu/13/:/usr/libexec/gcc/x86_64-linux-gnu/13/:/usr/libexec/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/13/:/usr/lib/gcc/x86_64-linux-gnu/
LIBRARY_PATH=/usr/lib/gcc/x86_64-linux-gnu/13/:/usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/13/../../../../lib/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/13/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
/usr/libexec/gcc/x86_64-linux-gnu/13/collect2 -plugin /usr/libexec/gcc/x86_64-linux-gnu/13/liblto_plugin.so -plugin-opt=/usr/libexec/gcc/x86_64-linux-gnu/13/lto-wrapper -plugin-opt=-fresolution=/tmp/ccQdj6Ia.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s -plugin-opt=-pass-through=-lc -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_s --build-id --eh-frame-hdr -m elf_x86_64 --hash-style=gnu --as-needed -dynamic-linker /lib64/ld-linux-x86-64.so.2 -pie -z now -z relro /usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/Scrt1.o /usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/13/crtbeginS.o -L/usr/lib/gcc/x86_64-linux-gnu/13 -L/usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/13/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/13/../../.. /tmp/cciIqt6W.o -lgcc --push-state --as-needed -lgcc_s --pop-state -lc -lgcc --push-state --as-needed -lgcc_s --pop-state /usr/lib/gcc/x86_64-linux-gnu/13/crtendS.o /usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/crtn.o
COLLECT_GCC_OPTIONS='-v' '-mtune=generic' '-march=x86-64' '-dumpdir' 'a.'
|
|
Способы компиляции программы из нескольких файлов
|
Способы компиляции программы из нескольких файлов
Статическая линковка (Static Linking)
- Что происходит: весь объектный код библиотеки добавляется в итоговый исполняемый файл на этапе компиляции/линковки.
- Результат: получаем один .exe или .out, который самодостаточен и не зависит от внешних библиотек во время выполнения.
- Файлы: обычно .a (archive) на Unix/Linux, .lib на Windows.
- Минусы: Больший размер бинарника (встраивается код всех библиотек).. Если библиотека обновилась — нужно пересобирать программу, чтобы получить обновления.
gcc main.c libfoo.a -o my_program
Динамическая линковка (Dynamic Linking)
- Что происходит: в исполняемый файл включается только ссылка на библиотеку, а не сам код. Код подгружается во время выполнения.
- Результат: исполняемый файл меньше, библиотека должна присутствовать на системе во время запуска.
- Библиотеки можно обновлять без перекомпиляции программы.
gcc main.c -lmylib -o my_program # ищет libmylib.so при запуске
Если сборка падает с undefined reference → явно добавляй -lm.
Если линковка проходит без -lm → значит линкер сам подхватывает libm, либо libc уже содержит нужные функции.
|
|
Способы компиляции программы из нескольких файлов
Способ 1
|
Способ 1. Прямая компиляция всех файлов
gcc -c main.c
gcc -c utils.c
gcc -o my_program main.o utils.o
Или сразу одной командой:
$ gcc -o my_program.out main.c utils.c
Запускаем
$ ./my_program.out
|
|
Способы компиляции программы из нескольких файлов
Способ 2
|
Способ 2.
Отдельная компиляция + статическая линковка (инкрементальная сборка - компиляция только измененных файлов с последующей линковкой)
# Компилируем каждый файл в объектный файл
$ gcc -c main.c -o main.o
$ gcc -c utils.c -o utils.o
# Линкуем (статически) объектные файлы в исполняемый файл
$ gcc main.o utils.o -o my_program.out
# Запускаем
$ ./my_program.out
|
|
Способы компиляции программы из нескольких файлов
Способ 3
|
Способ 3.
Отдельная компиляция + динамическая линковка
1. Компилируем динамическую библиотеку
utils.c — это файл с функциями, которые мы хотим вынести в библиотеку.
# компилируем объектный файл для динамической библиотеки с флагом -fPIC (позиционно-независимый код)
gcc -c -fPIC utils.c -o utils.o
# создаем динамическую библиотеку libutils.so
gcc -shared -o libutils.so utils.o
# -shared говорит компилятору сделать .so
# -fPIC — чтобы код был позиционно-независимым (обязательно для динамических библиотек)
2. Компилируем исполняемый файл
Теперь main.c будет ссылаться на функции из этой библиотеки:
# компилируем main.c в объектным файлом
gcc -c main.c -o main.o
# линковка с динамической библиотекой libutils.so
gcc main.o -L. -lutils -o my_program.out
# -L. — искать библиотеки в текущей директории
# -lutils — подключаем libutils.so (имя без префикса lib и суффикса .so)
3. Запуск программы
dynamic_linking/my_program.out: error while loading shared libraries: libutils.so: cannot open shared object file: No such file or directory
Linux должен знать, где находится .so. Есть несколько способов:
- Указать переменную окружения LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=/home/jeka/Projects/C/HelloWorld/dynamic_linking:$LD_LIBRARY_PATH
./my_program.out
- Или задать путь при линковке (rpath):
gcc main.o -L/home/jeka/Projects/C/HelloWorld/dynamic_linking -lutils -Wl,-rpath=/home/jeka/Projects/C/HelloWorld/dynamic_linking -o my_program.out
Теперь .so будет искаться в текущей директории.
- Или скопировать libutils.so в системные каталоги типа /usr/lib или /usr/local/lib и обновить кэш ldconfig
4. Теперь можно менять utils.c и пересобрать только библиотеку libutils.so:
Повторяем шаг 1
# компилируем объектный файл для динамической библиотеки с флагом -fPIC (позиционно-независимый код)
gcc -c -fPIC utils.c -o utils.o
# создаем динамическую библиотеку libutils.so
gcc -shared -o libutils.so utils.o
|
|
Способы компиляции программы из нескольких файлов
Способ 4
|
Способ 4.
Используя Makefile (автоматизация предыдущих способов)
FILE ?= main.c utils.c stack_static/stack_static.c stack_api/stack_api.c stack_dyn/stack_dyn.c stack_bytes/stack_bytes.c hashtable_bytes/hashtable_bytes.c bst/bs_tree.c
FILE_TEST ?= stack_static/stack_static.c stack_api/stack_api.c stack_dyn/stack_dyn.c stack_bytes/stack_bytes.c hashtable_bytes/hashtable_bytes.c bst/bs_tree.c tests/test.c tests/unity/unity.c
TARGET_FILE ?= my_program.out
TARGET_FILE_TEST ?= test_my_program.out
DIAG_FLAGS = -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag
.PHONY: all
all: compile-gcc run
week: week-compile-gcc run
test: compile-gcc-test run-test
week-compile-gcc:
gcc -std=c99 -O0 $(FILE) -o $(TARGET_FILE)
compile-gcc:
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security $(DIAG_FLAGS) -O0 $(FILE) -o $(TARGET_FILE)
compile-gcc-test:
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security $(DIAG_FLAGS) -O0 $(FILE_TEST) -o $(TARGET_FILE_TEST)
compile-clang:
clang -fsanitize=memory -fsanitize=address $(FILE) -o $(TARGET_FILE)
run-test:
./$(TARGET_FILE_TEST)
run:
./$(TARGET_FILE)
run-gcc:
valgrind --leak-check=full --track-origins=yes ./$(TARGET_FILE)
help:
@echo "Use:"
@echo " make - compile (gcc) and run"
@echo " make week - compile (gcc) and run without strong rules"
@echo " make FILE=test.c - compile and run custom C file"
@echo " make test - run tests"
|
|
|
// utils.h --- заголовочный файл
#ifndef UTILS_H // Защита от повторного включения
#define UTILS_H
extern int global_var;
// Объявления функций
int add(int a, int b);
int multiply(int a, int b);
void print_message(const char* message);
#endif
// utils.c - реализация
#include <stdio.h>
#include "utils.h"
int global_var=9;
int add(int a, int b) {
return a + b;
}
int multiply(int a, int b) {
return a * b;
}
void print_message(const char* message) {
printf("Message: %s\n", message);
}
// main.c -- программа входа
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include "utils.h" // Подключаем наш заголовок, для своих заголовков "file.h"
extern int global_var; // тут можно не обьявлять если в "utils.h" уже есть
int main() {
printf("Сборка из нескольких файлов! %d\n",global_var);
int result = add(5, 3);
printf("5 + 3 = %d\n", result);
result = multiply(4, 7);
printf("4 * 7 = %d\n", result);
print_message("Hello from multiple files!");
return EXIT_SUCCESS;
}
|
|
Правильное разделение между .h и .c файлами
Заголовочный файл (.h) — это просто «обещание» или декларация. Когда вы пишете #include "my_lib.h" внутри main.c, вы говорите компилятору: «Верь мне, функция с таким именем и такими аргументами существует, я опишу её позже». Но линкеру это не нужно, он слинкует объектный файл и сопоставит внешний код в main.c
|
В заголовочном файле (.h) - определения
// structures.h
#ifndef STRUCTURES_H
#define STRUCTURES_H
// Объявляем структуры (определение)
struct Point {
int x;
int y;
};
// Объявляем константы
#define MAX_SIZE 100
extern const double PI; // только для глобальных констант
// Объявляем функции
void print_point(struct Point p);
// **ОБЪЯВЛЯЕМ** глобальные переменные (ключевое слово extern!)
extern int global_counter;
extern struct Point global_point;
#endif
В исходном файле (.c) - реализации
// structures.c
#include "structures.h"
// **ОПРЕДЕЛЯЕМ** глобальные переменные (без extern!)
int global_counter = 0;
struct Point global_point = {0, 0};
const double PI = 3.141592653589793;
// Определяем функции
void print_point(struct Point p) {
printf("Point(%d, %d)\n", p.x, p.y);
}
// Реализуем приватные функции/струтуры
static void print_private(struct Point p) {
printf("Point(%d, %d)\n", p.x, p.y);
}
|
|
|
|
|
|
Выразительность языка С в сочетании с богатством его операций делает возможным написание кода, который исключительно сложно понять. Конечно, вы отнюдь не обязаны писать неясный код, но такая возможность имеется. В конце концов, для какого еще языка устраивается ежегодный конкурс на самый запутанный код?
Какие типы ошибок чаще всего допускают программисты на C:
- Чаще всего в C допускают ошибку null pointer:
- Разыменование нулевого указателя (NULL pointer dereference)
- Использование неинициализированного указателя
- Утечка памяти (Memory Leak)
- Выход за границы массива (Buffer Overflow)
- Двойное освобождение памяти (Double Free)
В книге "Компьютерные системы. Архитектура и программирование [2022] Брайант Р. Э., О'Халларон Д. Р." Глава 9.11
|
|
Язык позволяет создавать переменные без данных
sudo apt install clang
|
// main.c -- программа входа
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
int i; // резервирование памяти для типа int
printf("i=%d\n",i);// i=32766 это случайное число на стеке, “неопределённое поведение” (undefined behavior)
i = 99; // присваивание
printf("i=%d\n",i);// i=99
int y = 5; // инициализация
// множественное присвоение справа на лево
int a,b,c;
a = b = c = 9;
return EXIT_SUCCESS;
}
Но если компилировать через gcc с флагами предупреждениями статического анализа:
$ gcc -std=c99 -Wall -Wextra -O0 main.c -o main.out
то мы получим предупреждение:
main.c: In function ‘main’:
main.c:4:5: warning: ‘i’ is used uninitialized [-Wuninitialized]
4 | printf("i=%d\n",i);
| ^~~~~~~~~~~~~~~~~~
main.c:3:9: note: ‘i’ was declared here
3 | int i;
|
^
А вот что покажет компилятор clang с настройкой проверки использования неинициализированной памяти:
$ clang -fsanitize=memory main.c -o main.out
==28405==WARNING: MemorySanitizer: use-of-uninitialized-value
#0 0x5b568b676378 in main (/home/jeka/Projects/C/HelloWorld/my_program.out+0xca378) (BuildId: d142d2104297a1903d9a60471c8722da7d51b49b)
#1 0x7e1bc2a2a1c9 in __libc_start_call_main csu/../sysdeps/nptl/libc_start_call_main.h:58:16
#2 0x7e1bc2a2a28a in __libc_start_main csu/../csu/libc-start.c:360:3
#3 0x5b568b5de2f4 in _start (/home/jeka/Projects/C/HelloWorld/my_program.out+0x322f4) (BuildId: d142d2104297a1903d9a60471c8722da7d51b49b)
SUMMARY: MemorySanitizer: use-of-uninitialized-value (/home/jeka/Projects/C/HelloWorld/my_program.out+0xca378) (BuildId: d142d2104297a1903d9a60471c8722da7d51b49b) in main
Exiting
|
|
Язык позволяет производить инициализацию слишком вольно
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int a,b,c=4;
printf("a=%d b=%d c=%d\n",a,b,c);// a=32767 b=-1801395848 c=4 // данные в 'a' и 'b' мусор
int d,e,f;
d=e=f=8; // сомнительное удобство
// Значением всего выражения является значение выражения справа от знака операции запятая.
int x = (249,7,8,500); // оператор запятая все порешал за вас !!!
printf("%d ",x);// 500
return EXIT_SUCCESS;
}
|
|
Язык позволяет создавать данные не соответствующие типу
И язык позволяет автоматическое (понижение) преобразование типов с усечением данных
В связи с этим появилась привычка именовать переменную ее типом, что является плохой практикой в современных языках
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int a = 3.3; // произойдет явное приведение к типу int с потерей точности
printf("%d\n", a);
float pi = 3.1415926536; // инициализация переменной типа float (6 знаков) значением double
printf("%f\n", pi);// 3.141593 тоже потеряли точность
// Автоматическое понижающее преобразование (Implicit narrowing conversion)
int n = 300; // 00000000 00000000 00000001 00101100 = 4 байта = 32 бита
char c = n; // 00101100 = 1 байт = 8 бит
// автоматически преобразует int в char происходит автоматическое отсекание всех бит, кроме младших восьми (Lattice-8) "... 00101100"
// что и остается в типе char
printf("%d", c);// 44 это 00101100 в двоичной форме
return EXIT_SUCCESS;
}
|
|
Скрытое автоматическое преобразование типов
(флаги компиляции и факт потерь точности выбрасывает ошибку компиляции)
|
// -Werror -Wconversion - флаги компиляции для отлова неяных преобразований с потерями
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int foo_correct(int, int);
int main(void) {
float z = (float) 5 / 3; // Error происходит автоматическое преобразование, флаг `-Wconversion` выдаст предупреждение
float k = (float) 5 / (float) 3; // OK
int result = 5/3; // OK, Усечение (дробная часть, полученная при делении двух целых чисел, отбрасывается) не относится к автоматическому преобразованию с потерей, хотя именно это и происходит
printf("%d\n",foo_correct(1.0f, 1.0L)); // Ok. компилятор не считает, что есть потери при преобразование этих чисел в int
// Но в этом случае хоть и нет потерь преобразования, компилятор выдает ошибку форматирования
double d = 0.0;
printf("%d",d);// error: format ‘%d’ expects argument of type ‘int’, but argument 2 has type ‘double’ [-Werror=format=]
printf("%d\n",foo_correct(1.00000001f, 1.00000000000000000001L)); // Ok. Тут превышение точности типа, но это уже не про преобразование (Литералы с превышением точности - легальны в C)
printf("%d\n",foo_correct(1.1f, 1.1L)); // Error, тут уже будут потери и компилятор с флагами не пропустит
return EXIT_SUCCESS;
}
int foo_correct(int a, int b){
return a + b;
}
Output:
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 main.c -o my_program.out
main.c: In function ‘main’:
main.c:11:31: error: conversion from ‘float’ to ‘int’ changes value from ‘1.10000002e+0f’ to ‘1’ [-Werror=float-conversion]
11 | printf("%d\n",foo_correct(1.1f, 1.1L)); // Error, тут уже будут потери
| ^~~~
main.c:11:37: error: conversion from ‘long double’ to ‘int’ changes value from ‘1.10000000000000000002e+0l’ to ‘1’ [-Werror=float-conversion]
11 | printf("%d\n",foo_correct(1.1f, 1.1L)); // Error, тут уже будут потери
| ^~~~
cc1: all warnings being treated as errors
make: *** [Makefile:10: compile-gcc] Error 1
|
|
Язык позволяет не указывать аргументы в printf и scanf
т.е. способствует UB
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int a = 3;
printf("%d\t%f\n", a); // 3 0.000000 мусор
printf("%d\n");// -1243254112 мусор
return EXIT_SUCCESS;
}
|
|
Язык имеет скрытые побочные эффекты в printf
Неопределённое поведение (Undefined Behavior, UB)
|
Если выбрали неверный формат спецификатора преобразования, то ломается весь вывод printf, а не только неверный спецификатор
В примере только для типа long выбран верный спецификатор %ld, но он так и не будет выведен корректно
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define BLURB "Authentic imitation !"
int main(void) {
long n = 777;
float f = 1.1f;
double d = 1.1;
// вариант 1
//printf("%ld\n", n); // 777
//printf("%ld %ld %ld\n", f, d, n); // 777 777 0
// вариант 2
printf("%ld %ld %ld\n", f, d, n); // 777 777 108430082014656
return EXIT_SUCCESS;
}
Как так получается, все аргументы функции складываются в стек с конкретным своим типом но когда функция printf начинает забирать значения она руководствуется нашими спецификаторами преобразования, и получается что тип имеет один размер, а неверный спецификатор дает несоответствующий размер типа и забирает мусор
|
|
Язык имеет логику истинности в которой -1 или пустая строка это истина
|
#include <stdio.h>
#include <stdbool.h>
#include <math.h> // для констант NAN и INFINITY
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// За счет автоматического преобразования типов, строка преобразуется в число-мусор которое подходит под истину true
int count = "";
printf("%d\n", count);// -711057404
_Bool b = count;
printf("%d\n", b);// 1
b = -45;
printf("%d", b);// 1
float f_nan = NAN; // или так = 1.0 / 0.0;
double d_inf = INFINITY; // или так = -1.0 / 0.0;
printf("%f\n", f_nan);// nan
printf("%lf\n", d_inf);// inf
b = f_nan;
printf("%d\n", b);// 1
b = d_inf;
printf("%d\n", b);// 1
return EXIT_SUCCESS;
}
|
|
В C программист полностью самостоятельно управляет временем жизни переменных, и компилятор не предотвращает такие ошибки.
|
#include <stdio.h>
#include <stdlib.h>
#include <stdlib.h> // EXIT_SUCCESS
int *create_number() {
int num = 42; // Локальная переменная в стеке
return # // Возвращаем указатель на нее
} // num перестает существовать здесь
int main() {
int *ptr = create_number(); // ptr указывает на несуществующую память
printf("%d\n", *ptr); // Ошибка: обращение к освобожденной памяти
return EXIT_SUCCESS;
}
|
|
Особенность побитового сдвига вправо для чисел со знаком signed
В C нельзя полагаться на конкретное поведение >> для знаковых отрицательных чисел — это ловушка переносимости.
|
Например, в языках С и C++ не определено (Implementation-Defined Behavior), должна ли операция поразрядного сдвига вправо заполнять очищенные биты нулями (логический сдвиг) или значением знакового бита (арифметический сдвиг) для чисел со знаком (signed integers). Новички часто получают неожиданный ответ, потому что они ожидают, что i >> 1 будет вести себя как деление на 2 с округлением к нулю, что верно только для положительных чисел.
i = -1;
printf("%d\n", i >> 1);
Программист, переходящий с одного компилятора/архитектуры на другой, может столкнуться с тем, что:
- На новой системе
-1 >> 1 = -1 (если компилятор выбрал арифметический сдвиг)
- На старой системе
-1 >> 1 = 0 (если компилятор выбрал логический сдвиг)
Два возможных варианта:
- 1. Арифметический сдвиг (чаще всего, добавляется слева т.е. в старшую позицию копию старшего бита знака 0 или 1):
-8 >> 1 = -4
Что происходит бинарно (8-битный пример):
-8: 11111000 (дополнение до двух)
>>1: 11111100 = -4 (копируется старший бит)
- 2. Логический сдвиг (редко, слева добавляется старший бит 0 всегда):
-8 >> 1 = 124 (для 8-бит) или большие числа для 32-бит
Что происходит бинарно (8-битный пример):
-8: 11111000
>>1: 01111100 = 124 (добавляется 0 слева)
Именно эта непредсказуемость и является ошибкой программиста, поскольку он полагался на поведение, которое не гарантируется стандартом языка.
Решение (Хорошая практика) Если вы работаете с побитовыми операциями и вам нужно гарантированное поведение, всегда используйте числа без знака (unsigned int или uint32_t)
int i = -1;
unsigned int u = (unsigned int)i;
// u >> 1 всегда будет выполнять логический сдвиг, заполняя нулями.
printf("%u\n", u >> 1); // Выведет 2147483647 (0x7FFFFFFF)
#include <stdio.h>
int main() {
int x = -8;
// НЕПОРТАТИВНО (зависит от компилятора):
printf("%d >> 1 = %d\n", x, x >> 1);
// ПОРТАТИВНОЕ решение:
if (x < 0) {
// Для отрицательных - делаем арифметический сдвиг сами
printf("%d >> 1 = %d\n", x, (x + 1) / 2 - 1);
} else {
printf("%d >> 1 = %d\n", x, x >> 1);
}
// Или используем беззнаковый тип:
unsigned int y = (unsigned int)x;
printf("%u >> 1 = %u\n", y, y >> 1); // Всегда логический
}
|
|
Особенность побитового сдвига влево << на число равное или более числу бит
В языке C это поведение — «черная дыра» (Undefined Behavior).
- на одном компьютере программа может выдать 0.
- на другом — оставить число прежним.
- на третьем — вообще сломаться.
|
#include <stdio.h>
#include <stdint.h>
int main() {
uint8_t a = 13; // 0000 1101
int k = 10;
// 1. ОПАСНЫЙ ВАРИАНТ (Undefined Behavior)
// В C сдвиг на число >= разрядности типа — это неопределенное поведение.
// Может быть сдвиг по модулю:
// Число сдвига считается так:
// k = 10; то на сколько мы хотели сдвинуть
// w - это разряд числа, для uint8_t это 8, для uint16_t это 16, для int это 32
// k = k % w
// На x86 это скорее всего даст 13 << (10 % 8) = 52, но верить этому нельзя.
uint8_t risky = a << k;
printf("Risky shift: %u\n", risky);
// 2. БЕЗОПАСНЫЙ ВАРИАНТ 1: Эмуляция "Wrapping" (как в Rust)
// Мы сами явно берем остаток от деления.
uint8_t w = sizeof(a) * 8; // получаем 8
uint8_t wrap = a << (k % w);
printf("Safe wrapping: %u (binary: 00110100)\n", wrap);
// 3. БЕЗОПАСНЫЙ ВАРИАНТ 2: Эмуляция "Saturating" (уход в 0)
// Если сдвиг слишком большой — возвращаем 0.
uint8_t sat = (k >= w) ? 0 : (a << k);
printf("Safe saturating: %u\n", sat);
return 0;
}
|
|
|
|
|
|
Например имя "__job" следует соглашению стандарта ANSI С о том, что все закрытые имена реализации, видимые снаружи, должны начинаться с двух знаков подчеркивания. Это снижает вероятность конфликта имен.
Имена функций
- Понятные префиксы:
vec_, str_, list_ — чтобы ясно было, к какой «модели» относится функция.
void read_file(void);
int get_value_from_sensor(void);
Локальные переменные
int count;
char *buffer;
float temperature_celsius;
Глобальные переменные (принято давать префикс модуля или _g_):
int g_counter;
char g_device_name[32];
Константы и макросы
#define MAX_BUFFER_SIZE 256
#define PI 3.1415926
const int max_clients = 10;
Типы и структуры (часто пишут в PascalCase (с заглавной буквы)):
typedef struct {
int x;
int y;
} Point;
typedef enum {
STATE_INIT,
STATE_READY,
STATE_ERROR
} SystemState;
typedef struct sensor_data_t {
int temperature;
int pressure;
} sensor_data_t;
Префиксы и неймспейсы
Так как в C нет пространств имён, принято добавлять префиксы для модулей:
// file: motor.c
void motor_init(void);
void motor_start(void);
void motor_stop(void);
// file: adc.c
void adc_init(void);
int adc_read(void);
|
|
|
|
|
|
RAII
Это, пожалуй, самое главное архитектурное преимущество C++ перед C:
Язык C++ использует конструкторы и деструкторы классов. Память, файлы, блокировки и другие ресурсы автоматически освобождаются при выходе объекта из области видимости.
А язык C требует ручного освобождения не используемой памяти.
C++ не устраняет свободу C, но направляет ее, предоставляя программисту безопасные, высокоуровневые абстракции (классы, векторы, строки, умные указатели), которые автоматически обрабатывают большинство рискованных задач (управление памятью, контроль границ) без потери производительности. C++ широко используется во встроенных системах, но часто в ограниченном подмножестве (Embedded C++)
|
|
|
В C нет RAII (Resource Acquisition Is Initialization — «получение ресурса есть инициализация») — это идиома программирования, преимущественно используемая в языках с детерминированным временем жизни объектов, таких как C++. Суть RAII заключается в том, что управление ресурсами (например, памятью, файлами, сокетами, мьютексами и т.д.) привязывается к времени жизни объекта.
Основные принципы RAII:
- Ресурс захватывается в конструкторе объекта.
Когда объект создаётся, он сразу получает нужный ресурс (например, открывает файл или выделяет память).
- Ресурс освобождается в деструкторе объекта.
Как только объект выходит из области видимости (или удаляется явно), его деструктор автоматически вызывается и освобождает ресурс.
- Гарантия безопасности исключений (exception safety).
Даже если в программе произойдёт исключение, деструкторы локальных объектов всё равно будут вызваны, и ресурсы не «утекут».
Преимущества RAII:
- Устраняет утечки ресурсов.
- Упрощает код — не нужно вручную освобождать ресурсы.
- Повышает надёжность и читаемость.
- В сочетании с умными указателями (std::unique_ptr, std::shared_ptr) делает управление памятью почти автоматическим.
Почему в C нет RAII?
RAII основан на автоматическом вызове деструкторов при выходе объекта из области видимости. В C:
- Нет конструкторов и деструкторов.
- Нет перегрузки операторов.
- Нет исключений, а значит, нет необходимости в строгой exception safety.
- Управление ресурсами (памятью, файлами и т.д.) — всегда ручное: программист сам вызывает
free(), fclose(), pthread_mutex_destroy() и т.п.
Это делает C особенно подходящим для встроенных систем, ядер ОС, real-time приложений, где важна полная прозрачность управления ресурсами.
|
|
Очистка "Мусора"
В деле сборки мусора существует целый ряд подходов и приемов. В некоторых схемах подсчитывается количество обращений к каждому объекту из модулей — ведется его счетчик ссылок. Объект освобождается тогда, когда его счетчик ссылок становится равным нулю. Эту технику можно запрограммировать в С и C++ явным образом для управления объектами общего пользования.
|
В стандартных библиотечных функциях C очистка буферов (например, буферов потоков ввода/вывода, таких как stdout или stderr) происходит автоматически при нормальном завершении программы, либо с помощью механизма, подобного функциям, зарегистрированным через atexit().
Что касается "мусора" (то есть неосвобожденной динамически выделенной памяти), то в C и C++ нет механизма автоматической очистки кучи, как это происходит в языках со сборщиком мусора (например, Java, C#, Python).
В C ответственность за управление памятью полностью лежит на программисте. "Мусор" — это память, выделенная в куче (heap) с помощью функций malloc(), calloc(), или realloc(), которая перестала быть нужной, но не была возвращена операционной системе.
1. Нормальный механизм: free()
#include <stdlib.h>
#include <stdio.h>
#include <stddef.h> // NULL
void allocate_and_free() {
int *data = (int*)malloc(10 * sizeof(int));
if (data == NULL) return;
// Используем память...
data[0] = 42;
// Освобождаем память, предотвращая "мусор" (утечку)
free(data);
data = NULL; // Хорошая практика: обнулить указатель
}
2. При завершении программы
Если программа завершается нормально (return из main или вызов exit()):
-
Динамическая память (Куча): Память, которая была не освобождена с помощью free(), называется утечкой памяти (memory leak). Однако, когда процесс программы полностью завершается, операционная система автоматически очищает все ресурсы, выделенные этому процессу, включая всю память, которую он занимал в куче.
- С точки зрения операционной системы, "мусора" не остается; память просто возвращается обратно в системный пул.
-
Регистрируемые функции (atexit): Вы можете использовать atexit() для регистрации функции, которая освободит глобальные или статические структуры данных перед завершением, тем самым "очищая мусор" до того, как его уберет ОС.
#include <stddef.h> // NULL
void cleanup_globals() {
// Освобождение глобально выделенной памяти
if (global_ptr != NULL) {
free(global_ptr);
}
}
int main() {
atexit(cleanup_globals); // Регистрируем функцию очистки
// ...
return 0; // cleanup_globals будет вызвана здесь
}
3. Аварийное завершение (abort())
Если программа завершается аварийно (например, вызов abort(), или критическая ошибка сегментации):
-
Функции, зарегистрированные через atexit(), не вызываются.
-
Буферы потоков ввода/вывода могут не быть сброшены (flushed).
-
Динамическая память все равно будет очищена операционной системой при прекращении работы процесса.
Таким образом, хотя ОС в конечном счете освободит всю память, программировать освобождение через free() обязательно для корректной работы программы и предотвращения утечек во время ее выполнения.
|
|
Если C++ раздувает код, то когда я пишу безопасную обвертку для массива на C это раздует код? Что в итоге я приду такими шагами из C в C++ подобие?
А как тогда Rust, он не раздувает код? Rust лучше использовать на замену C для embedded?
|
Ваша безопасная обертка на C ("объектно-ориентированное C") добавит накладные расходы на логику (проверки), но не добавит накладные расходы на рантайм C++ (виртуальные таблицы, исключения, сложный ABI, большую библиотеку libstdc++).Таким образом, создавая безопасные обертки в C, вы идете по пути C++-подобной архитектуры (инкапсуляция и безопасность), но избегаете большинства причин, по которым C++ "раздувает" код в Embedded-системах.
Rust не раздувает код так, как C++. Он разработан с философией "нулевых абстракционных накладных расходов" (Zero-Cost Abstraction).
Да, Rust — отличная и все более популярная замена C для Embedded-разработки.
Rust позволяет писать код с производительностью C и с высоким уровнем безопасности памяти, устраняя наиболее частые причины ошибок в C.
| Аспект | C | Rust |
|---|
| Безопасность памяти | Ручная. Главный источник ошибок. | Автоматическая (Compile-Time). Практически исключает утечки и висячие указатели. |
| Скрытые расходы | Минимальные, но легко допустить ошибки. | Минимальные ("Zero-Cost Abstraction"). |
| Абстракции | Через struct и указатели на функции (сложно). | Через классы (structs/impl) и трейты (Traits) (чисто и типобезопасно). |
| Инструменты | make, gcc. Слабый линтер. | Cargo (стандартный), Clippy (мощный линтер), rustfmt (стандартное форматирование). |
В Embedded-среде, где критически важна предсказуемость, отсутствие скрытых накладных расходов и безопасность (нет места для malloc и ошибок с указателями), Rust предлагает лучшее из обоих миров: высокую производительность C и безопасность, которую C++ предоставляет только ценой большого "раздувания" кода.
|
|
|
Да, язык C будет оставаться необходимым и широко используемым в течение очень долгого времени, несмотря на появление более безопасных и современных языков, таких как C++ и Rust.
Его востребованность обусловлена не только исторической инерцией, но и рядом фундаментальных технических причин.
Причины долголетия C
1. Совместимость и Портируемость (ABI)
C является общепризнанным языком-посредником (Lingua Franca) для всех языков программирования и операционных систем.
- Стабильность ABI: Бинарный интерфейс приложений (ABI) C (то, как вызываются функции, как передаются аргументы и как возвращаются значения) невероятно стабилен и стандартизирован почти на всех платформах. Это позволяет легко создавать библиотеки на C, которые будут работать с кодом на C++, Rust, Python, Java и других языках.
- Универсальный интерфейс: Если вы пишете библиотеку, которую планируется использовать в разных экосистемах (например, криптографический движок или парсер), создание ее интерфейса на C гарантирует, что она будет легко и без проблем подключаться ко всем другим языкам.
2. Разработка Операционных Систем (ОС)
C является основным языком для создания ядер ОС и низкоуровневых компонентов.
- Ядро Linux: Подавляющее большинство кода ядра Linux написано на C, потому что C не зависит от какой-либо стандартной библиотеки (например, $\texttt{libstdc++}$) и позволяет писать код с минимальными накладными расходами.
- Системные вызовы: C необходим для реализации системных вызовов, которые являются мостом между приложениями и ядром ОС.
3. Производительность и Предсказуемость
В ситуациях, требующих максимальной скорости и предсказуемости, C часто остается выбором по умолчанию.
- "Ассемблер высокого уровня": C дает самый прозрачный и прямой контроль над машинной архитектурой и памятью, позволяя программисту точно знать, какие инструкции будут выполнены. Это критически важно для:
- Драйверов устройств.
- Встроенных систем (Embedded) с очень ограниченными ресурсами.
- Высокопроизводительных вычислений (HPC), где важна оптимизация на уровне кэша и регистров.
4. Создание Компиляторов и Интерпретаторов
Многие компиляторы, интерпретаторы и инструменты для других языков написаны на C.
- Python, Ruby, PHP: Их основные интерпретаторы (CPython, MRI) написаны на C, что позволяет им быть быстрыми и легко переносимыми на разные платформы.
- Современные компиляторы: Например, компилятор Rust ($\texttt{rustc}$) использует компоненты, которые в конечном итоге опираются на инфраструктуру компилятора LLVM, написанную в основном на C++.
Заключение
C остается востребованным там, где безопасность (которую добавляют C++ и Rust) является вторичным требованием по отношению к абсолютному контролю, минимальному размеру кода (footprint) и универсальной совместимости между различными языковыми экосистемами.
|
|
Какие преимущества C++ перед C можно использовать в Embedde
|
Многие опытные программисты (особенно те, кто работает с ядрами ОС, драйверами или в Embedded-системах с жесткими ограничениями) хорошо относятся к C, но настороженно или плохо к C++ из-за его сложности, непредсказуемости и накладных расходов.
Основная ценность C — его прозрачность.
C — "Что видишь, то и получаешь": Каждая строка кода C ( char *ptr = malloc(10) ) ясно соответствует одной или нескольким низкоуровневым машинным инструкциям. Программист точно знает, что и когда произойдет (нет скрытого выделения памяти, нет неявных вызовов).
C++ — Скрытая магия: В C++ многие высокоуровневые возможности (конструкторы, деструкторы, виртуальные функции, итераторы std::vector ) приводят к скрытым вызовам функций, выделению памяти на Куче ( new ), и дополнительному коду, который вставляется компилятором. Это делает поведение программы менее предсказуемым по времени и памяти.Пример: Использование std::string может вызвать скрытое выделение памяти, даже если вы не видите new/delete в коде.
Проблемы с ABI и Инструментами
Нестабильность C++ ABI: В отличие от C, где бинарный интерфейс (ABI) очень стабилен, ABI C++ (особенно декорирование имен и макет объектов) может меняться между версиями компиляторов или операционных систем. Это затрудняет создание библиотек, которые будут работать с любым сторонним кодом.
Когда C побеждает
В итоге, те, кто предпочитает C, выбирают его, когда:
- Требуется минимальный footprint: Исполняемый файл должен быть максимально маленьким (Embedded).
- Критически важна предсказуемость: Недопустимы скрытые аллокации памяти или задержки (Ядра ОС, драйверы, Real-Time-системы).
- Требуется стабильный ABI: Для создания публичных API и библиотек.
|
|
Какие преимущества C++ перед C можно использовать в Embedde
|
Использование C++ во встроенных системах (Embedded) — это компромисс: вы отключаете опасные "тяжелые" функции (исключения, динамическую память), но сохраняете ключевые преимущества, которые делают код чище, безопаснее и удобнее для поддержки, чем чистый C.
Вот основные преимущества C++ перед C, которые сохраняются и активно используются в Embedded-разработке:
1. Безопасное управление ресурсами (RAII)
RAII (Resource Acquisition Is Initialization) — это самый важный архитектурный принцип C++, который идеально подходит для Embedded-систем.
2. Абстракция оборудования (ООП)
C++ позволяет использовать классы для создания высокоуровневых абстракций, которые скрывают низкоуровневые детали работы с регистрами.
- Инкапсуляция: Вы можете создать класс SPI_Driver или GPIO_Pin, который содержит данные (например, адрес регистра) и методы (read(), write()). Это делает код более модульным и предотвращает случайный доступ к аппаратным регистрам.
- Наследование: Можно создать базовый класс I2C_Device и унаследовать от него конкретные сенсоры (BME280_Sensor), повторно используя общие методы работы с шиной.
- Типобезопасность: Передача объектов вместо "сырых" указателей на структуры.
3. Шаблоны и Compile-Time Безопасность (Templates)
Шаблоны C++ позволяют создавать обобщенный, типобезопасный код, который компилируется в эффективные инструкции, не уступая по скорости C, но при этом безопаснее, чем макросы C.
- Типобезопасные дженерики: Создание универсальных FIFO-очередей, буферов или драйверов, которые работают с любым типом данных, но компилятор проверяет типы во время сборки.
- std::array: Замена "сырых" массивов C на std::array. Это контейнер фиксированного размера, который находится на стеке (не использует Heap), но поддерживает методы STL (size(), at()) и может выполнять проверку границ в отладочных сборках.
- constexpr: Позволяет выполнять сложные вычисления (например, расчет задержек или размеров буферов) во время компиляции, а не во время выполнения, что экономит процессорное время в критических местах.
4. Строгий контроль типов и const
C++ имеет гораздо более строгие правила приведения типов, что позволяет компилятору поймать больше ошибок, которые в C привели бы к неявным (и часто ошибочным) преобразованиям.
- Улучшенный const: Более последовательное применение const позволяет компилятору строго контролировать, какие функции могут изменять состояние объекта или регистра, а какие — нет.
- Приведение типов: Использование static_cast, reinterpret_cast и const_cast заставляет программиста явно указать свое намерение, делая опасные операции более заметными, в отличие от неявного приведения типов в C.
|
|
|
|
|
|
Анализ Флагов Компиляции (C99)
$ gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -O0 main.c -o main.out
$ gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 main.c -o main.out
Стандарт языка:
- -std=c99 - Гарантирует, что компилятор использует правила и особенности стандарта C99.
Все распространенные предупреждения:
- -Wall - Включает обширный набор базовых, но важных предупреждений (напр., неинициализированные переменные).
Дополнительные предупреждения:
- -Wextra - Включает менее распространенные, но полезные проверки, которые не входят в -Wall (напр., неиспользуемые параметры функций).
Базовая проверка printf/scanf:
- -Wformat - Проверяет, что аргументы функций ввода/вывода (с использованием
%d, %s) соответствуют их типу.
Усиленная проверка printf/scanf:
- -Wformat=2 - Включает более строгие проверки безопасности и соответствия форматов.
Проверка безопасности формата:
- -Wformat-security - Предупреждает о потенциальных уязвимостях "Format String Attack" (атака через строку формата).
Предупреждает о неявных преобразованиях:
- -Wconversion - Предупреждает о неявных преобразованиях, которые могут изменить значение с потерями, без потерь игнорируется
Уровень оптимизации:
- -O0 - Устанавливает уровень оптимизации в ноль (0), что критически важно для отладки в GDB. Гарантирует, что код в отладчике GDB (исполняемые инструкции) строго соответствует исходному коду. Оптимизация может переупорядочить или удалить переменные, делая отладку невозможной или непредсказуемой.
- -Og - Оптимизируй всё, что не мешает отладке
- -O2 или -O3 агрессивные уровни оптимизации
Output выходной файл
- -o - имя для готового исполняемого файла компиляции
Превратить предупреждения в ошибки:
- -Werror - Гарантирует, что код не скомпилируется, если компилятор обнаружит хотя бы одно предупреждение. Это отличная практика для поддержания чистого и безопасного кода.
|
|
|
|
|
|
Операции ввода-вывода не столь дешевы, как и другие библиотечные функции:
| Input/Output | Наносекунды |
|---|
| fputs(s, fp) | 270 |
| fgets(s, 9, fp) | 222 |
| fprintf(fp, "%d\n", i) | 1820 |
| fscanf(fp, "%d", &i1) | 2070 |
| Malloc | Наносекунды |
|---|
| free(malloc(8)) | 342 |
| String Functions | Наносекунды |
|---|
| strcpy(s, "0123456789") | 157 |
| i1 = strcmp(s, s) | 176 |
| i1 = strcmp(s, "al23456789") | 64 |
| String/Number Conversions | Наносекунды |
|---|
| i1 = atoi("12345") | 402 |
| sscanf("12345", "%d', &i1) | 2376 |
| sprintf(s, "%d", i) | 1492 |
| f1 = atof("123.45") | 4098 |
| sscanf("123.45", "%f", &f1) | 6438 |
| sprintf(s, "%6.2f", 123.45) | 3902 |
|
|
int getchar(void); построчно буферизированный ввод
|
Т.е. сброс буфера после ввода конца строки \0 через клавишу Enter
Обычно функция getchar() возвращает значение в диапазоне от 0 до 127, поскольку они соответствуют стандартному набору символов, но она может возвращать значения от 0 до 255, если система распознает расширенный набор символов.
getchar() ВСЕГДА построчно буферизирован в каноническом режиме терминала, независимо от настроек setvbuf()
Построчно буферизированный ввод-вывод буфер сбрасывается всякий раз, когда появляется символ нов о й строки. (Клавиатурный ввод обычно построчно буф., нажатие Enter вызывает сброс)
Читает следующий символ из стандартного потока ввода stdin
Служит для чтения символьных данных (байтов) из консоли, файла или другого источника ввода.
Возвращает: int (целое число). Это ключевой момент.
- Если чтение прошло успешно, возвращается прочитанный символ (преобразованный в int)
- Если достигнут конец файла или произошла ошибка ввода/вывода, возвращается специальное значение EOF (End-Of-File), которое гарантированно является отрицательным числом (обычно -1)
getchar() возвращает int (а не char), чтобы иметь возможность вернуть все 256 возможных байтовых значений (если char беззнаковый) плюс специальное значение EOF
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
printf("Введите строку: ");
// Читаем всю строку посимвольно - как и задумано
int c;
while ((c = getchar()) != '\n' && c != EOF) {
printf("Символ: '%c'\n", c);
}
return EXIT_SUCCESS;
}
// Здесь "остаток в буфере" - это и есть нужные данные
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
// В Linux типичный размер буфера терминала - 4096 байт
// Но stdio может использовать свой буфер 4K-8K поверх этого
printf("STDIN_FILENO buffer size: %ld\n", fpathconf(STDIN_FILENO, _PC_MAX_INPUT));
// по идее должны ожидать три приглашения для ввода, но если ввести строку сразу целиком, то ничего больше не будет предложенно вводить.
// При нажатии Enter, вводится еще символ новой строки `\n` (0x0A) в буфер, так что до третьего приглашения ввода не дойдет!
printf("Введите 'abc': ");
int c1 = getchar(); // забирает из очереди буфера первый символ 'a'
if (c1 == '\n') {
c1 = getchar(); // пропускаем перевод строки
}
int c2 = getchar(); // далее ввод не предлагается так как буфер еше имеет данные 'bс', и getchar забирает следующий символ getchar 'b'
if (c2 == '\n') {
c2 = getchar(); // пропускаем перевод строки
}
int c3 = getchar(); // далее ввод так же не предлагается, так как буфер еше имеет данные 'c'
if (c3 == '\n') {
c3 = getchar(); // пропускаем перевод строки
}
printf("%c %c %c\n", c1, c2, c3); // a b c
return EXIT_SUCCESS;
}
|
|
Канонический режим - это строка отправляется только по Enter
Использование int getchar(void);
Выключаем канонический режим
|
Порядок вычисления выражений. В языках С и C++ порядок вычисления операндов выражений и аргументов функций, а также некоторых других значений не определен.
Рассмотрим следующее присваивание:
n = (getchar() << 8) | getchar();
Вторая функция getchar могла быть вызвана первой, поскольку порядок записи выражения не всегда совпадает с порядком его выполнения.
Выключаем канонический режим
#include <stdio.h>
#include <termios.h>
#include <unistd.h>
#include <stdlib.h> // EXIT_SUCCESS
void set_noncanonical() {
struct termios t;
tcgetattr(STDIN_FILENO, &t);
t.c_lflag &= ~ICANON; // Выключаем канонический режим
t.c_cc[VMIN] = 1; // Минимум 1 символ для read()
t.c_cc[VTIME] = 0; // Без таймаута
tcsetattr(STDIN_FILENO, TCSANOW, &t);
}
int main() {
set_noncanonical();
printf("Теперь символы читаются сразу (без Enter): ");
int c = getchar();
printf("Получили: '%c'\n", c);
// Не забудь восстановить режим!
return EXIT_SUCCESS;
}
|
|
int putchar(int c) Записывает один символ (байт) в стандартный поток вывода stdout
|
Записывает один символ (байт) в стандартный поток вывода stdout.
Служит для вывода символьных данных (байтов) на экран консоли, в файл или другой поток вывода.
Вывод также часто буферизуется. Символы могут накапливаться в буфере и не отображаться на экране, пока буфер не заполнится, не будет встречен символ новой строки (\n), или не будет вызван fflush(stdout) для принудительного сброса буфера.
- Принимает: int (целое число), которое представляет символ (байт), который нужно вывести.
- Возвращает: int.
- Если вывод прошел успешно, возвращает выведенный символ (байт).
- Если произошла ошибка вывода, возвращает EOF
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(){
int c = 'A';
putchar(c); // Выведет 'A' на консоль
// Пример копирования ввода в вывод
int input_char;
while ((input_char = getchar()) != EOF) {
putchar(input_char);
}
return EXIT_SUCCESS;
}
|
|
setvbuf - управляет буферизацией в библиотеке stdio
setbuf - это упрощенная версия setvbuf
|
Применение:
- Нужен контроль над размером буфера
- Нужна построчная буферизация (_IOLBF)
- Точный контроль над типом буферизации
Ключевые сценарии применения:
- Большие файлы → большие буферы (_IOFBF, 64K+)
- Интерактивный вывод → построчная буферизация (_IOLBF)
- Реал-тайм логи → без буферизации (_IONBF)
- Критические ошибки → немедленный вывод
- Оптимизация производительности → подбор размера буфера
Результат: Ускорение операций I/O в 2-10 раз за счет уменьшения системных вызовов!
// Влияет на то, как stdio буферизует данные
setvbuf(stdin, NULL, _IONBF, 0); // Выключить буферизацию stdio
=== СРАВНЕНИЕ РАЗМЕРОВ БУФЕРА ===
Без буферизации: 310.039 ms
Буфер 1K: 11.933 ms
Буфер 64K: 6.871 ms
Ускорение 64K vs без буфера: 45.12x
=== ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ: ЛОГИРОВАНИЕ ===
Логи записаны. Проверьте error.log - ошибка должна быть сразу!
Пример
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
// 1. Оптимизация записи в файл
void file_write_optimization() {
printf("=== ОПТИМИЗАЦИЯ ЗАПИСИ В ФАЙЛ ===\n");
FILE *fp = fopen("large_output.txt", "w");
if (!fp) {
perror("fopen");
return;
}
// Устанавливаем большой буфер 64K для записи
char *buffer = malloc(65536);
setvbuf(fp, buffer, _IOFBF, 65536); // Полная буферизация
clock_t start = clock();
// Пишем 100,000 строк
for (int i = 0; i < 100000; i++) {
fprintf(fp, "Line %d: This is some data that we're writing to the file\n", i);
}
clock_t end = clock();
printf("Запись с буферизацией 64K: %.3f ms\n",
(double)(end - start) * 1000 / CLOCKS_PER_SEC);
fclose(fp);
free(buffer);
}
// 2. Построчная буферизация для интерактивного вывода
void line_buffered_output() {
printf("\n=== ПОСТРОЧНАЯ БУФЕРИЗАЦИЯ ===\n");
// Устанавливаем построчную буферизацию для stdout
setvbuf(stdout, NULL, _IOLBF, BUFSIZ);
printf("Эта строка появится сразу: ");
fflush(stdout); // Явный сброс буфера
sleep(2);
printf("а эта - тоже сразу благодаря \\n\n"); // \n вызывает сброс буфера
sleep(1);
printf("Строка 1 без перевода...");
sleep(1);
printf("Строка 2 без перевода...");
sleep(1);
printf("И только теперь \\n выведет все сразу\n");
}
// 3. Отключение буферизации для реального времени
void unbuffered_realtime() {
printf("\n=== РЕЖИМ БЕЗ БУФЕРИЗАЦИИ ===\n");
// Отключаем буферизацию для stderr (часто используется по умолчанию)
setvbuf(stderr, NULL, _IONBF, 0);
fprintf(stderr, "Ошибка: ");
sleep(1);
fprintf(stderr, "сообщение выводится ");
sleep(1);
fprintf(stderr, "немедленно!\n");
}
// 4. Оптимизация чтения большого файла
void efficient_file_reading() {
printf("\n=== ОПТИМИЗАЦИЯ ЧТЕНИЯ ===\n");
FILE *fp = fopen("/usr/share/dict/words", "r"); // Большой файл
if (!fp) {
perror("fopen");
return;
}
// Устанавливаем буфер 32K для чтения
char *read_buffer = malloc(32768);
setvbuf(fp, read_buffer, _IOFBF, 32768);
char line[256];
int line_count = 0;
clock_t start = clock();
while (fgets(line, sizeof(line), fp)) {
line_count++;
}
clock_t end = clock();
printf("Прочитано %d строк за %.3f ms\n", line_count,
(double)(end - start) * 1000 / CLOCKS_PER_SEC);
fclose(fp);
free(read_buffer);
}
// 5. Сравнение производительности с разными буферами
void buffer_size_comparison() {
printf("\n=== СРАВНЕНИЕ РАЗМЕРОВ БУФЕРА ===\n");
const int NUM_WRITES = 100000;
// Тест 1: Без буферизации
FILE *fp1 = fopen("test1.txt", "w");
setvbuf(fp1, NULL, _IONBF, 0);
clock_t start = clock();
for (int i = 0; i < NUM_WRITES; i++) {
fprintf(fp1, "Data %d\n", i);
}
clock_t time1 = clock() - start;
fclose(fp1);
// Тест 2: Буфер 1K
FILE *fp2 = fopen("test2.txt", "w");
char buf1k[1024];
setvbuf(fp2, buf1k, _IOFBF, 1024);
start = clock();
for (int i = 0; i < NUM_WRITES; i++) {
fprintf(fp2, "Data %d\n", i);
}
clock_t time2 = clock() - start;
fclose(fp2);
// Тест 3: Буфер 64K
FILE *fp3 = fopen("test3.txt", "w");
char *buf64k = malloc(65536);
setvbuf(fp3, buf64k, _IOFBF, 65536);
start = clock();
for (int i = 0; i < NUM_WRITES; i++) {
fprintf(fp3, "Data %d\n", i);
}
clock_t time3 = clock() - start;
fclose(fp3);
free(buf64k);
printf("Без буферизации: %.3f ms\n", (double)time1 * 1000 / CLOCKS_PER_SEC);
printf("Буфер 1K: %.3f ms\n", (double)time2 * 1000 / CLOCKS_PER_SEC);
printf("Буфер 64K: %.3f ms\n", (double)time3 * 1000 / CLOCKS_PER_SEC);
printf("Ускорение 64K vs без буфера: %.2fx\n", (double)time1 / time3);
}
// 6. Практический пример: логирование с разной буферизацией
void logging_example() {
printf("\n=== ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ: ЛОГИРОВАНИЕ ===\n");
FILE *debug_log = fopen("debug.log", "w");
FILE *error_log = fopen("error.log", "w");
// Отладочные логи - полная буферизация для производительности
char debug_buffer[8192];
setvbuf(debug_log, debug_buffer, _IOFBF, 8192);
// Логи ошибок - без буферизации, чтобы видеть ошибки сразу
setvbuf(error_log, NULL, _IONBF, 0);
for (int i = 0; i < 10; i++) {
// Обычные логи - буферизуются
fprintf(debug_log, "Debug: Iteration %d\n", i);
if (i == 5) {
// Критическая ошибка - выводится немедленно
fprintf(error_log, "ERROR: Something went wrong at iteration %d!\n", i);
}
sleep(1);
}
// Явно сбрасываем буфер отладочных логов
fflush(debug_log);
fclose(debug_log);
fclose(error_log);
printf("Логи записаны. Проверьте error.log - ошибка должна быть сразу!\n");
}
int main() {
file_write_optimization();
line_buffered_output();
unbuffered_realtime();
efficient_file_reading();
buffer_size_comparison();
logging_example();
// Удаляем временные файлы
remove("large_output.txt");
remove("test1.txt");
remove("test2.txt");
remove("test3.txt");
remove("debug.log");
remove("error.log");
return 0;
}
|
|
ioctl/termios - управляет поведением терминала/устройства
|
// Влияет на то, как терминал отправляет данные в программу
t.c_lflag &= ~ICANON; // Терминал отправляет символы сразу, а не построчно
|
|
ioctl() в UNIX для указания желаемого типа ввода терминалов и сокетов
ioctl переключает:
- Блокирующий/неблокирующий режим
- Канонический/неканонический режим терминала
- Размеры терминала
- Параметры устройства
|
Что переключает ioctl:
1. Режим ввода/вывода
// Блокирующий vs неблокирующий режим
int nonblock = 1;
ioctl(fd, FIONBIO, &nonblock); // Переключаем в НЕБЛОКИРУЮЩИЙ режим
int nonblock = 0;
ioctl(fd, FIONBIO, &nonblock); // Переключаем в БЛОКИРУЮЩИЙ режим
2. Режим терминала
struct termios t;
tcgetattr(fd, &t);
// Канонический vs неканонический режим
t.c_lflag &= ~ICANON; // ВКЛЮЧАЕМ неканонический режим (символы сразу)
// или
t.c_lflag |= ICANON; // ВКЛЮЧАЕМ канонический режим (ждать Enter)
tcsetattr(fd, TCSANOW, &t);
#include <stdio.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <termios.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <errno.h>
// 1. IOCTL для ТЕРМИНАЛА
void terminal_examples() {
printf("=== ТЕРМИНАЛ ===\n");
int fd = STDIN_FILENO; // Файловый дескриптор stdin
// а) Получить размер терминала
struct winsize ws;
if (ioctl(fd, TIOCGWINSZ, &ws) == 0) {
printf("Размер терминала: %d строк x %d столбцов\n",
ws.ws_row, ws.ws_col);
}
// б) Получить количество байт в буфере ввода
int bytes_available;
if (ioctl(fd, FIONREAD, &bytes_available) == 0) {
printf("Байт в буфере ввода: %d\n", bytes_available);
}
// в) Установить неблокирующий режим
int nonblock = 1;
if (ioctl(fd, FIONBIO, &nonblock) == 0) {
printf("Неблокирующий режим установлен\n");
}
}
// 2. IOCTL для СОКЕТОВ
void socket_examples() {
printf("\n=== СОКЕТЫ ===\n");
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
return;
}
// а) Получить количество байт доступных для чтения
int bytes_available;
if (ioctl(sockfd, FIONREAD, &bytes_available) == 0) {
printf("Байт доступно для чтения из сокета: %d\n", bytes_available);
}
// б) Установить неблокирующий режим сокета
int nonblock = 1;
if (ioctl(sockfd, FIONBIO, &nonblock) == 0) {
printf("Сокет в неблокирующем режиме\n");
}
// в) Получить размер буфера отправки
int send_buffer_size;
socklen_t len = sizeof(send_buffer_size);
if (ioctl(sockfd, TIOCOUTQ, &send_buffer_size) == 0) {
printf("Размер буфера отправки: %d байт\n", send_buffer_size);
}
close(sockfd);
}
// 3. Практический пример: неблокирующий ввод с терминала
void nonblocking_input() {
printf("\n=== НЕБЛОКИРУЮЩИЙ ВВОД ===\n");
printf("Нажимайте клавиши (q для выхода)...\n");
int fd = STDIN_FILENO;
// Сохраняем оригинальные настройки
struct termios original, new;
tcgetattr(fd, &original);
new = original;
// Настраиваем raw режим
new.c_lflag &= ~(ICANON | ECHO);
new.c_cc[VMIN] = 0; // Минимум 0 символов - неблокирующий
new.c_cc[VTIME] = 0; // Таймаут 0
tcsetattr(fd, TCSANOW, &new);
// Устанавливаем неблокирующий режим через ioctl
int nonblock = 1;
ioctl(fd, FIONBIO, &nonblock);
int c;
int count = 0;
while (count < 10) { // 10 итераций для демонстрации
// Проверяем есть ли данные для чтения
int bytes_available;
ioctl(fd, FIONREAD, &bytes_available);
if (bytes_available > 0) {
c = getchar();
if (c == 'q') {
printf("\nВыход по клавише 'q'\n");
break;
}
printf("Нажата клавиша: '%c' (код: %d)\n", c, c);
} else {
printf(".");
fflush(stdout);
usleep(100000); // 100ms
}
count++;
}
// Восстанавливаем настройки терминала
tcsetattr(fd, TCSANOW, &original);
}
// 4. Пример с сокетом: проверка данных перед чтением
void socket_buffer_check() {
printf("\n=== ПРОВЕРКА БУФЕРА СОКЕТА ===\n");
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
return;
}
// Устанавливаем неблокирующий режим
int nonblock = 1;
ioctl(sockfd, FIONBIO, &nonblock);
// Подключаемся к примерному серверу (закомментировано для демо)
/*
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons(80),
.sin_addr.s_addr = inet_addr("93.184.216.34") // example.com
};
if (connect(sockfd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
if (errno != EINPROGRESS) {
perror("connect");
close(sockfd);
return;
}
}
*/
// Проверяем буфер в цикле
for (int i = 0; i < 5; i++) {
int bytes_available;
if (ioctl(sockfd, FIONREAD, &bytes_available) == 0) {
if (bytes_available > 0) {
printf("Доступно для чтения: %d байт\n", bytes_available);
// read(sockfd, buffer, bytes_available);
} else {
printf("Данных нет, ждем...\n");
}
}
sleep(1);
}
close(sockfd);
}
int main() {
terminal_examples();
socket_examples();
nonblocking_input();
socket_buffer_check();
return 0;
}
|
|
Вот почему иногда кажется что getchar() "не работает" - данные просто застряли в буфере ядра или stdio.
|
Вот почему иногда кажется что getchar() "не работает" - данные просто застряли в буфере ядра или stdio.
[Пользователь] -> [Клавиатура] -> [Ядро TTY] -> [stdio] -> [getchar()]
↓ ↓ ↓ ↓ ↓
Нажал 'A' Буфер 16B Буфер 4K Буфер 8K Ваш код
Уровни буферизации:
- Терминал/Клавиатура (железный буфер)**
Физический буфер клавиатуры ~ 16-32 байта.
Хранит нажатые клавиши ДО их обработки.
// Прерывание клавиатуры → скан-коды → ASCII
// Может хранить несколько нажатых клавиш до обработки
2. Ядро ОС (буфер TTY)
Драйвер терминала в ядре ~ 4K.
Обрабатывает специальные символы (Ctrl+C, Backspace).
#include <stdio.h>
#include <termios.h>
int main() {
struct termios t;
tcgetattr(0, &t);
printf("Размер буфера ядра: %d\n", t.c_cc[VTIME]); // Настройки TTY
printf("Канонический режим: %s\n", (t.c_lflag & ICANON) ? "ON" : "OFF");
}
3. Библиотека stdio (пользовательский буфер)
BUFSIZ (обычно 4K-8K) в вашей программе.
Добавляет свою буферизацию поверх ядра.
#include <stdio.h>
#include <stdio_ext.h>
int main() {
printf("Размер буфера stdio: %d\n", BUFSIZ); // Обычно 8192
// Можно посмотреть/изменить буферизацию
printf("Тип буферизации stdin: ");
if (stdin->_flags & _IO_UNBUFFERED) printf("UNBUFFERED\n");
else if (stdin->_flags & _IO_LINE_BUF) printf("LINE BUFFERED\n");
else printf("FULLY BUFFERED\n");
}
Практическая демонстрация:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
char input[100];
printf("Введите строку: ");
// 1. Пользователь вводит "hello" + Enter
// 2. Данные идут: клавиатура → ядро → stdio
// 3. fgets читает ИЗ БУФЕРА stdio, а не напрямую с клавиатуры!
fgets(input, sizeof(input), stdin);
// Убираем \n
input[strcspn(input, "\n")] = 0;
printf("Вы ввели: '%s'\n", input);
// Докажем что данные уже в буфере ядра
printf("Оставшиеся данные в буфере ядра: ");
system("stty -echo -icanon min 0 time 0; cat | od -c");
}
|
|
Полностью буферизированный ввод
НЕ используется для:
- ❌ stdin (интерактивный ввод)
- ❌ stdout (интерактивный вывод)
- ❌ stderr (ошибки)
Причина: Для интерактивности нужна немедленная реакция, а не ожидание заполнения буфера.
|
При полностью буферизированном вводе буфер сбрасывается (его содержимое отправляется в место назначения), когда он полон. Буферизация такого вида обычно происходит при файловом вводе. Размер буфера зависит от системы, но наиболее распространены значения 512 и 4096 байтов.
Чтение/запись файлов
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <stddef.h> // NULL
int main() {
FILE *fp = fopen("large_file.bin", "rb");
// Устанавливаем полную буферизацию 8K
setvbuf(fp, NULL, _IOFBF, 8192);
char buffer[8192];
while (fread(buffer, 1, 8192, fp) > 0) {
// Данные читаются блоками по 8K
// Меньше системных вызовов = выше производительность
}
fclose(fp);
return EXIT_SUCCESS;
}
Сетевые сокеты
#include <stdio.h>
#include <sys/socket.h>
#include <stddef.h> // NULL
void handle_client(int sockfd) {
FILE *sock_file = fdopen(sockfd, "r+");
// Полная буферизация для сетевого трафика
setvbuf(sock_file, NULL, _IOFBF, 4096);
char data[4096];
while (fgets(data, sizeof(data), sock_file)) {
// Чтение больших блоков данных из сети
}
}
Высокопроизводительная обработка данных
#include <stdio.h>
void process_large_csv() {
FILE *input = fopen("huge_dataset.csv", "r");
FILE *output = fopen("processed.csv", "w");
// Полная буферизация для ввода и вывода
setvbuf(input, NULL, _IOFBF, 16384); // 16K
setvbuf(output, NULL, _IOFBF, 16384);
char line[1024];
while (fgets(line, sizeof(line), input)) {
// Обработка данных...
fputs(line, output);
}
fclose(input);
fclose(output);
}
|
|
Прямой системный вызов read() для чтения без буферов т.е. сразу дать ввод
|
#include <unistd.h>
#include <termios.h>
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int getch_immediate() {
char c;
// Настройка raw режима
struct termios old, new;
tcgetattr(STDIN_FILENO, &old);
new = old;
new.c_lflag &= ~(ICANON | ECHO);
new.c_cc[VMIN] = 1; // Ждать 1 символ
new.c_cc[VTIME] = 0; // Без таймаута
tcsetattr(STDIN_FILENO, TCSANOW, &new);
// ПРЯМОЙ системный вызов - обходит ВСЕ буферы
ssize_t result = read(STDIN_FILENO, &c, 1);
// Восстановление режима
tcsetattr(STDIN_FILENO, TCSANOW, &old);
return (result == 1) ? (unsigned char)c : EOF;
}
int main() {
printf("Нажимайте клавиши (q для выхода):\n");
int c;
while ((c = getch_immediate()) != 'q') {
printf("Символ: '%c' (ASCII: %d)\n", c, c);
}
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Все функции из библиотеки stdio.h
|
- printf(const char *format, ...) — выводит форматированную строку в stdout.
- fprintf(FILE *stream, const char *format, ...) — выводит форматированную строку в указанный поток.
- snprintf(char *str, size_t size, const char *format, ...) — форматированный вывод в буфер с ограничением размера.
- vprintf(const char *format, va_list ap) — аналог printf с va_list.
- vfprintf(FILE *stream, const char *format, va_list ap) — аналог fprintf с va_list.
- sprintf(char *str, const char *format, ...) — форматированный вывод в буфер (без ограничения размера).
- fscanf(FILE *stream, const char *format, ...) — чтение форматированных данных из потока.
- scanf(const char *format, ...) — чтение форматированных данных из stdin.
- sscanf(const char *str, const char *format, ...) — чтение форматированных данных из строки.
- fopen(const char *filename, const char mode) — открывает файл с заданным режимом, возвращает FILE.
- fclose(FILE *stream) — закрывает файл.
- fread(void *ptr, size_t size, size_t nmemb, FILE *stream) — считывает nmemb объектов размера size из потока.
- fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) — записывает nmemb объектов размера size в поток.
- fseek(FILE *stream, long offset, int whence) — перемещает указатель текущей позиции файла.
- ftell(FILE *stream) — возвращает текущую позицию в файле.
- rewind(FILE *stream) — перемещает указатель в начало файла.
- fflush(FILE *stream) — сбрасывает буфер потока.
- fgets(char *s, int n, FILE *stream) — читает строку из потока (с ограничением длины n-1).
- fputs(const char *s, FILE *stream) — записывает строку в поток (без символа конца строки).
- gets(char *s) — устаревшая функция для чтения строки из stdin (небезопасно).
- puts(const char *s) — выводит строку в stdout с добавлением '\n'.
- getc(FILE *stream) — читает один символ из потока.
- getchar(void) — читает один символ из stdin.
- putc(int c, FILE *stream) — записывает один символ в поток.
- putchar(int c) — записывает один символ в stdout.
- ungetc(int c, FILE *stream) — возвращает символ в поток.
- feof(FILE *stream) — проверяет достижение конца файла.
- ferror(FILE *stream) — проверяет наличие ошибки потока.
- clearerr(FILE *stream) — сбрасывает флаги ошибок потока.
- perror(const char *s) — выводит сообщение об ошибке в stderr, используя strerror(errno).
- setbuf(FILE *stream, char *buf) — задает буфер потока.
- setvbuf(FILE *stream, char *buf, int mode, size_t size) — задает режим буферизации потока.
- tmpfile(void) — создает временный бинарный файл, возвращает FILE*.
- tmpnam(char *s) — создает уникальное имя временного файла.
|
|
Для вывода
Функция printf(%.2f, %10.3f, %e, %g)
Возвращаемое значение — количество выведенных символов, включая пробелы и символ новой строки.
Если произошла ошибка вывода, printf() возвратит отрицательное значение.
% [Флаги] [Ширина] [.Точность] [Тип]
В printf — %f всегда принимает double
В scanf — %f ожидает указатели float*, %lf — double*
Модификатор L (%Lf) — для long double и в scanf, и в printf
|
| Тип | Формат | Пример | Вывод |
|---|
char число | %hhd | char c = 42; printf("%hhd", c); | 42 |
char символ | %c | printf("%c", 'g'); | g |
short | %hd | short n = 42; printf("%hd", n); | 42 |
int / signed int | %d или %i | printf("%d", 42); | 42 |
unsigned int | %u | printf("%u", 42); | 42 |
int (8-ричная) | %o | printf("%o", 9); | 11 (восьмеричная) |
int (8-ричная) | %#o | printf("%#o", 9); | 011 (восьмеричная) |
int (16-ричная) | %x | printf("%x", 255); | ff (шестнадцатеричная, строчные) |
unsigned long int (16-ричная) | %lx | printf("%lx", 255); | ff (шестнадцатеричная, строчные) |
int (16-ричная) | %#x | printf("%#x", 255); | 0xff (шестнадцатеричная, строчные) |
int (16-ричная) | %X | printf("%X", 255); | FF (шестнадцатеричная, заглавные) |
long int | %ld | printf("%ld", 123456789L); | 123456789 |
unsigned long int | %lu | printf("%lu", 4000000000UL); | 4000000000 |
long long int | %lld | printf("%lld", 9223372036854775807LL); | 9223372036854775807 |
unsigned long long int | %llu | printf("%llu", 18446744073709551615ULL); | 18446744073709551615 |
*char / строка | %s | `printf("%s","Hello World!"); | Hello World! |
| указатель | %p | char *s="" ; printf("%p",s); | 0x5bf5f68c8004 |
| вывод % | %% | printf("perc %%"); | perc % |
| Тип | Формат | Пример | Вывод |
|---|
float / double | %f | printf("%f", 3.14); | 3.140000 |
| %.2f | printf("%.2f", 3.14159); | 3.14 |
| %10.2f | printf("%10.2f", 3.14); | ' 3.14' (ширина 10 символов) |
| %e | printf("%e", 3.14); | 3.140000e+00 |
| %g | printf("%g", 3.14); | 3.14 (автоматический выбор %f или %e) |
long double | %Lf | printf("%Lf", 3.14L); | 3.140000 |
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char *name = "Jeka";
int rt = printf("hello " "%s\n" , name); // так тоже возможно, строки склеются
printf("Функция printf() вывела %d символов.\n",rt); // 11
// многострочный вариант
printf("hello "
"%s\n" , name);
printf("hello \
%s\n" , name);
return EXIT_SUCCESS;
}
|
|
Флаги функции printf()
% [Флаги] [Ширина] [.Точность] [Тип]
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int num = 45;
// 1. Принудительный знак (+) и Пробел (' ')
printf("1. Знак (+): |%+-5d|\n", num); // |+45 |
printf("2. Пробел (' '): |% 5d|\n", num); // | 45| (5d - ширина 5, пробел для положительного)
// 3. Заполнение нулями (0)
printf("3. Заполнение 0: |%08d|\n", num); // |00000045| (8d - ширина 8)
// 4. Левое выравнивание (-)
printf("4. Левое (-): |%-10d|\n", num); // |45 | (10d - ширина 10)
// 5. Альтернативная форма (#) - Шестнадцатеричное число
printf("5. Hex (#): |%#x|\n", 45); // |0x2d|
// 6. Комбинация (Заполнение 0 и принудительный знак)
printf("6. Комбо (+0): |%+06d|\n", num); // |+00045|
// 7. Флаг '#' для float (принудительное отображение десятичной точки)
printf("7. Float (#): |%#g|\n", 3.0); // |3.00000| (без # было бы 3)
return EXIT_SUCCESS;
}
|
|
Для ввода
Функция scanf(%f, %lf, %Lf)
Возвращает количество элементов, которые она успешно прочитала.
В scanf — %f ожидает указатели float*, %lf — double*
Модификатор L (%Lf) — для long double и в scanf, и в printf
ей лучше не пользоваться! используйте fgets
В scanf(), модификаторы h для short и hh для char критически важны и обязательны.
scanf() должна знать точный размер памяти, который ей нужно заполнить по указанному адресу.
Если вы передадите адрес переменной типа short или char, но используете спецификатор %d (который ожидает адрес int), это приведет к неопределенному поведению (UB) или повреждению памяти, поскольку scanf попытается записать 4 или 8 байт (размер int) в меньшую ячейку памяти.
// ПРАВИЛЬНО: Указываем scanf, что нужно записать только 1 байт (char)
if (scanf("%hhd", &c_val) == 1) {
// ...
}
В функции printf() применяются имена переменных, константы и выражения, а в scanf() — указатели на переменные.
|
Таблица модификаторов длины
Для printf() модификаторы длины менее критичны, потому что маленькие типы (char, short) автоматически продвигаются до int,
а вот в scanf() это уже жесткое требование, иначе получишь undefined behavior и краш.
| Модификатор | Тип аргумента | Пример вызова | Пример формата |
|---|
| (нет) | int *, unsigned int * | scanf("%d", &i); | %d, %u |
hh | signed char *, unsigned char * | scanf("%hhd", &c); | %hhd, %hhu |
h | short *, unsigned short * | scanf("%hd", &s); | %hd, %hu |
l | long *, unsigned long *, double * | scanf("%ld", &l);, scanf("%lf", &d); | %ld, %lu, %lf |
ll | long long *, unsigned long long * | scanf("%lld", &ll); | %lld, %llu |
j | intmax_t *, uintmax_t * | scanf("%jd", &x); | %jd, %ju |
z | size_t * | scanf("%zu", &z); | %zu |
t | ptrdiff_t * | scanf("%td", &t); | %td |
l | double * | scanf("%lf", &ld); | %lf |
L | long double * | scanf("%Lf", &ld); | %Lf |
| (float) | float * | scanf("%f", &f); | %f |
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char *name="";
float salary=0.0f;
printf("Введите имя:");
scanf("%s", &name);
printf("Введите желаемую сумму месячной зарплаты:\n");
scanf("%f", &salary);
printf("Вы ввели имя:%s и запралату:%f\n", &name, &salary);
return EXIT_SUCCESS;
}
|
|
Модификатор длины N (цифра или цифры) гарантирует, что вывод займёт минимум N символов
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int short_num = 42;
int long_num = 987654;
const char *short_word = "cat";
const char *long_word = "hippopotamus";
printf("### Минимальная ширина для чисел (%%Nd) ###\n");
// 1. Ширина больше данных (N > фактическая длина)
// Правое выравнивание, заполнение пробелами.
printf("1. %%6d (42): |%6d|\n", short_num); // | 42| (4 пробела + 2 цифры)
// 2. Ширина меньше данных (N < фактическая длина)
// Ширина игнорируется, выводится полная длина.
printf("2. %%4d (987654): |%4d|\n", long_num); // |987654| (ширина 6)
// 3. Комбинация с флагом '0'
// Заполнение нулями вместо пробелов.
printf("3. %%06d (42): |%06d|\n", short_num);// |000042|
printf("\n### Минимальная ширина для строк (%%Ns) ###\n");
// 4. Ширина больше данных (N > фактическая длина)
// Правое выравнивание, заполнение пробелами.
printf("4. %%8s (\"cat\"): |%8s|\n", short_word);// | cat| (5 пробелов + 'cat')
// 5. Комбинация с флагом '-' (Левое выравнивание)
// Заполнение пробелами справа.
printf("5. %%-8s (\"cat\"):|%-8s|\n", short_word);// |cat |
// 6. Ширина меньше данных (N < фактическая длина)
// Ширина игнорируется, выводится полная строка.
printf("6. %%8s (\"hippo\"):|%8s|\n", long_word);// |hippopotamus|
return EXIT_SUCCESS;
}
|
|
|
|
|
|
В языке С файл рассматривается как непрерывную последовательность байтов, каждый из которых может быть прочитан индивидуально. Это соответствует файловой структуре в среде Unix, откуда С берет свое начало.
Существует предельное количество одновременно открытых файлов, которое зависит от системы и реализации; часто этот предел находится в диапазоне от 10 до 20.
|
|
Прежде всего, давайте проведем различие между:
- текстовым и двоичным содержимым
- текстовым и двоичным файловыми форматами
- текстовым и двоичным режимами для файлов
|
Золотое правило: Всегда используйте двоичный режим ("rb", "wb"), если вы работаете не с чисто текстовыми данными. Это гарантирует, что данные будут прочитаны и записаны без искажений.
Отличный вопрос! Это фундаментальные понятия в программировании, и их четкое различие очень важно, особенно в языке C. Давайте разберем каждый пункт подробно.
1. Текстовое и двоичное содержимое (Content)
Это относится к природе самих данных, независимо от того, как они хранятся.
- Текстовое содержимое: Это данные, состоящие из символов, которые можно прочитать и понять человеку. Они представлены в виде последовательности кодов символов (чаще всего ASCII или Unicode). Примеры: строка
"Hello, World!\n", исходный код программы, файл CSV, HTML-страница.
- Двоичное содержимое: Это данные, чья внутренняя структура не основана на интерпретации как текст. Они представляют собой непосредственное двоичное представление данных в памяти компьютера. Примеры: исполняемый файл (
a.out, .exe), изображение (.jpg, .png), архив (.zip), или даже просто число int, записанное в виде байтов.
Ключевой момент: Один и тот же файл можно попытаться интерпретировать как текст, но если он бинарный, вы увидите "мусор". Например, если открыть JPEG-файл в текстовом редакторе, вы увидите случайные символы.
2. Текстовый и двоичный файловые форматы (Format)
Это соглашение о том, как структурированы данные внутри файла. Формат напрямую связан с содержимым.
- Текстовый формат: Файл, использующий текстовое содержимое для представления информации. Данные организованы согласно правилам, которые можно понять, читая файл как текст. Преимущества: человекочитаемость, переносимость между системами. Недостатки: обычно больший размер и необходимость парсинга.
- Примеры:
.txt, .csv, .xml, .json, .html.
- Двоичный формат: Файл, использующий двоичное содержимое. Данные хранятся в том же виде, в котором они обрабатываются программой, что часто делает файл более компактным и быстрым для чтения/записи. Структура определяется внутренней логикой программы.
- Примеры:
.exe, .dll, .jpg, .png, .docx (это ZIP-архив с XML и бинарными данными).
3. Текстовый и двоичный режимы для файлов (Mode в C)
Это самый важный для программиста на C аспект. Он определяет, как стандартная библиотека C (stdio.h) будет взаимодействовать с файлом при его открытии функцией fopen().
-
Текстовый режим ("r", "w", "a")
При открытии файла в текстовом режиме система выполняет преобразования, чтобы абстрагировать программиста от особенностей платформы.
- Преобразование конца строки: Это главное отличие.
- В Windows конец строки в файле представлен двумя символами:
\r (возврат каретки, CR) и \n (новая строка, LF).
- В Unix/Linux/macOS — одним символом
\n.
- При чтении в текстовом режиме в Windows последовательность
\r\n автоматически преобразуется в один символ \n. При записи символ \n преобразуется обратно в \r\n.
- В Linux это преобразование не происходит.
- Интерпретация символа
Ctrl+Z (^Z): В некоторых системах (старые версии Windows) символ ^Z (26 в ASCII) интерпретируется как конец файла при чтении в текстовом режиме.
-
Двоичный режим ("rb", "wb", "ab")
При открытии файла в двоичном режиме система не производит никаких преобразований. Данные читаются и записываются побайтно, точно в том виде, в котором они находятся в файле.
- Нет преобразования конца строки. Символы
\r и \n передаются в программу как есть.
- Нет специальной интерпретации
Ctrl+Z.
|
|
|
1. Низкоуровневый ввод-вывод предусматривает использование основных служб ввода-вывода, предоставляемых операционной системой.
2. Стандартный высокоуровневый ввод-вывод предполагает применение стандартного пакета из stdio.h
|
|
1. Низкоуровневый ввод-вывод
|
Работа со специальными файлами: когда нужно читать/писать в специальные файлы устройств (например, /dev/ttyS0 для последовательного порта).
- Буферизации нет (или буфер ядра)
- Производительность может быть ниже чем у высокоуровневого ввода-вывода из-за частых системных вызовов
- Переносимость меньше чем у высокоуровневого ввода-вывода (системные вызовы различаются между ОС, хотя POSIX стандартизировал многое)
- Функции open(), read(), write(), close()
- Нет различия между текстовым и двоичным режимом: Все данные — это просто последовательности байтов. Нет никакого автоматического преобразования \n в \r\n. Вы получаете и записываете именно те байты, которые указали.
- Близость к оборудованию: позволяют делать такие вещи, как прямое управление метаданными файла (права, владелец, размер и т.д.)
Стандартные дескрипторы unistd.h:
0 — STDIN_FILENO (стандартный вход, обычно клавиатура)
1 — STDOUT_FILENO (стандартный вывод, обычно терминал)
2 — STDERR_FILENO (стандартный вывод ошибок, обычно терминал)
|
|
1. Низкоуровневый ввод-вывод
Основные функции низкоуровневого I/O (из unistd.h и fcntl.h)
|
-
open() — открывает (или создает) файл.
int open(const char *pathname, int flags, mode_t mode);flags: O_RDONLY, O_WRONLY, O_RDWR, O_CREAT, O_TRUNC, O_APPEND. Ключевой момент: здесь используются флаги, а не строки режима как в fopen.- Возвращает файловый дескриптор или -1 в случае ошибки.
-
close() — закрывает файл, освобождая дескриптор.
-
read() — читает данные из файла.
ssize_t read(int fd, void *buf, size_t count);- Читает до
count байт из fd в буфер buf.
- Возвращает количество реально прочитанных байт. 0 — конец файла, -1 — ошибка.
-
write() — записывает данные в файл.
ssize_t write(int fd, const void *buf, size_t count);- Записывает
count байт из буфера buf в файл fd.
- Возвращает количество реально записанных байт (которое может быть меньше
count) или -1.
-
lseek() — изменяет позицию (смещение) в файле (аналог fseek).
off_t lseek(int fd, off_t offset, int whence);whence: SEEK_SET (начало), SEEK_CUR (текущая позиция), SEEK_END (конец файла).
|
|
1. Низкоуровневый ввод-вывод
Простой пример: копирование файла
|
#include <fcntl.h> // для open, O_RDONLY, O_WRONLY, O_CREAT
#include <unistd.h> // для read, write, close
#include <stdio.h> // для perror
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main() {
int source_fd, dest_fd;
ssize_t bytes_read;
char buffer[4096]; // Буфер размером 4KB
// 1. ОТКРЫТИЕ
// Открываем исходный файл только для чтения
source_fd = open("source.txt", O_RDONLY);
if (source_fd == -1) {
perror("Failed to open source.txt");
return EXIT_FAILURE;
}
// Создаем/перезаписываем целевой файл с правами rw-r--r--
dest_fd = open("dest.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (dest_fd == -1) {
perror("Failed to open dest.txt");
close(source_fd);
return EXIT_FAILURE;
}
// 2. ЧТЕНИЕ и ЗАПИСЬ
// Цикл чтения-записи
while ((bytes_read = read(source_fd, buffer, sizeof(buffer))) > 0) {
ssize_t bytes_written = write(dest_fd, buffer, bytes_read);
if (bytes_written != bytes_read) {
perror("Write error");
close(source_fd);
close(dest_fd);
return EXIT_FAILURE;
}
}
// Проверяем, не завершилось ли чтение с ошибкой
if (bytes_read == -1) {
perror("Read error");
}
// 3. ЗАКРЫТИЕ
close(source_fd);
close(dest_fd);
return EXIT_SUCCESS;
}
|
|
2. Стандартный высокоуровневый ввод-вывод предполагает применение стандартного пакета из stdio.h
Режимы fopen()
Функция fopen() не только открывает файл, но и настраивает буфер (или два буфера для режимов чтения-записи) и устанавливает структуру данных, содержащую сведения о файле и о буфере. Кроме того, fopen() возвращает указатель на эту структуру, так что другие функции знают, где ее искать.
|
Режимы для текстовых файлов
- "r" Read - чтение. Файл должен существовать.
- "w" Write - запись. Создает файл или обрезает существующий до нулевой длины.
- "a" Append - добавление. Создает файл или записывает в конец существующего.
- "r+" Read/Write - чтение и запись. Файл должен существовать.
- "w+" Read/Write - чтение и запись. Создает файл или обрезает существующий.
- "a+" Read/Append - чтение и добавление. Создает файл или открывает для чтения и записи в конец.
- "x" флаг стандарта C11, гарантирует, что файл будет создан эксклюзивно. Если файл уже существует, вызов fopen() завершится с ошибкой. Можно комбинировать "wx","w+x"
Режимы для двоичных файлов
- "rb" Чтение двоичного файла
- "wb" Запись двоичного файла
- "ab" Добавление в двоичный файл
- "r+b" или "rb+" Чтение и запись двоичного файла
- "w+b" или "wb+" Чтение и запись двоичного файла (создает/очищает)
- "a+b" или "ab+" Чтение и добавление в двоичный файл
Стандартные дескрипторы:
#include <stdio.h>
// Это указатели на FILE структуры, которые открывать через fopen не надо, они автоматически открываются
FILE *stdin; // стандартный ввод
FILE *stdout; // стандартный вывод
FILE *stderr; // стандартный вывод ошибок
// Использование:
fprintf(stdout, "Сообщение\n");
fprintf(stderr, "Ошибка\n");
fgets(buffer, size, stdin);
т.е. все (stdout,stderr,stdin) они имеют тип указателя на FILE, поэтому могут использоваться в качестве аргументов для стандартных функций ввода-вывода
|
|
2. Стандартный высокоуровневый ввод-вывод предполагает применение стандартного пакета из stdio.h
Открытие потока данных:
FILE *fopen (const char *filename, const char *mode);
-
fprintf() - форматированная запись в файл
-
fgets() - построчное чтение из файла
-
fputs() - запись строки
-
fputc() - запись символа
-
feof() и ferror() нужны чтобы отличить конец файла от ошибки.
-
feof() - причина завершения чтения файла - файл закончился?
-
ferror() - причина завершения чтения файла - была ошибка?
|
#include <stdio.h> // для printf, fprintf, fopen, fclose
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
#include <errno.h> // perror
int main(void){
FILE *fp=NULL;// указатель на обьект имеющий доступ к файлу
// Открытие файла
fp=fopen("test.txt","wx");
// Проверка открытия файла
if (fp == NULL) {
printf ("Не удалось открыть файл\n");
exit(EXIT_FAILURE);
}
//Запись данных в файл--------------------------------------------------------
fprintf(fp,"Тест записи в файл");
char name[] = "Иван";
int age = 25;
double salary = 50000.50;
// Запись форматированных данных---------------------------------------
fprintf(fp, "Имя: %s\n", name);
fprintf(fp, "Возраст: %d\n", age);
fprintf(fp, "Зарплата: %.2f\n", salary);
// Запись строк----------------------------------------------------------------------
char *lines[] = {"Первая строка", "Вторая строка", "Третья строка"};
int count = sizeof(lines) / sizeof(lines[0]);
for (int i = 0; i < count; i++) {
fputs(lines[i], fp);
fputc('\n', fp); // Добавляем символ новой строки
}
// Чтение построчно----------------------------------------------------------------
char buffer[256];
while (fgets(buffer, sizeof(buffer), fp) != NULL) {
// Убираем символ новой строки
buffer[strcspn(buffer, "\n")] = '\0';
printf("Прочитана строка: %s\n", buffer);
}
if (feof(fp)) {
printf("Достигнут конец файла - всё нормально\n");
}
if (ferror(fp)) {
perror("Произошла ошибка чтения");
}
// Закрытие файла-------------------------------------------------------------------
fclose (fp);
printf ("Файл закрыт\n");
return EXIT_SUCCESS;
}
|
|
|
Смысл в том, что mmap делает копирование практически мгновенным для больших файлов. mmap вообще не читает файл сразу! Он просто говорит ядру: "если программа обратится к этим адресам, подгрузи данные с диска". А когда write читает эту память, ядро уже само разбирается с диском.
По сравнению с обычным копированием (read/write):
- Данные копируются 4 раза: диск → ядро (read) → пользовательский буфер → ядро (write) → диск
- Нужны системные вызовы для каждого блока
- Для файла размером 1 МБ (1,048,576 байт)
- 1,048,576 / 4096 = 256 итераций
- 256 read + 256 write = 512 системных вызовов
- Для файла 1 ГБ (1,073,741,824 байт):
- read/write: ~524,288 системных вызовов
char buf[4096];
while((n = read(fd_in, buf, sizeof(buf))) > 0)
write(fd_out, buf, n);
mmap копирование:
- mmap экономит тысячи/миллионы переключений между пользователем и ядром.
- Данные копируются 1 раз: диск → память процесса (через mmap)
- Ядро и процесс используют одну и ту же физическую память
- Нет копирования между ядром и пользователем
- Для файла 1 ГБ:
addr = mmap(...); // 1 вызов
write(stdout, addr, size); // 1 вызов
munmap(addr, size); // 1 вызов
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Использование: %s <имя_файла>\n", argv[0]);
exit(1);
}
// Открываем файл
int fd = open(argv[1], O_RDONLY);
if (fd == -1) {
perror("open");
exit(1);
}
// Получаем размер файла
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("fstat");
close(fd);
exit(1);
}
// Проверка на пустой файл
if (sb.st_size == 0) {
close(fd);
return 0;
}
// Отображаем файл в память
char *addr = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (addr == MAP_FAILED) {
perror("mmap");
close(fd);
exit(1);
}
// Файловый дескриптор больше не нужен
close(fd);
// Записываем в stdout
if (write(STDOUT_FILENO, addr, sb.st_size) != sb.st_size) {
perror("write");
munmap(addr, sb.st_size);
exit(1);
}
// Освобождаем память
munmap(addr, sb.st_size);
return 0;
}
// gcc -o mmapcopy mmapcopy.c
// ./mmapcopy input.txt # вывод в терминал
// ./mmapcopy input.txt > output.txt # копирование в файл
|
|
fscanf() - функция для чтения форматированных данных из файла
возвращает целое число:
- положительное число - количество успешно прочитанных элементов
- EOF (обычно -1) - конец файла или ошибка чтения
- 0 - не удалось прочитать ни одного элемента
|
Файл data.txt с содержимым:
Иван 25 50000.50
Мария 30 75000.75
Файл main.c:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
FILE *file = fopen("data.txt", "r");
if (!file) {
printf("Ошибка открытия файла\n");
return EXIT_FAILURE;
}
char name[50];
int age;
double salary;
// Чтение первой строки
fscanf(file, "%49s %d %lf", name, &age, &salary);
printf("Прочитано: %s, %d, %.2f\n", name, age, salary);
// Чтение второй строки
fscanf(file, "%49s %d %lf", name, &age, &salary);
printf("Прочитано: %s, %d, %.2f\n", name, age, salary);
fclose(file);
return EXIT_SUCCESS;
}
Чтение неизвестного количества строк
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main() {
FILE *file = fopen("data.txt", "r");
if (!file) return EXIT_FAILURE;
char name[50];
int age;
double salary;
int line_count = 0;
// fscanf возвращает количество успешно прочитанных элементов
while (fscanf(file, "%49s %d %lf", name, &age, &salary) == 3) {
line_count++;
printf("Строка %d: %s, %d лет, зарплата %.2f\n",
line_count, name, age, salary);
}
printf("Всего прочитано строк: %d\n", line_count);
fclose(file);
return EXIT_SUCCESS;
}
|
|
fflush() - заставляет немедленно записать данные из буфера в файл
"сохранить сейчас", а не ждать когда система сама решит записать данные.
|
Для stdout - чтобы сразу увидеть вывод
printf("Подождите...");
fflush(stdout); // Сообщение сразу появится на экране
// долгая операция
Для файлов - чтобы данные не потерялись при аварии
FILE *file = fopen("important.txt", "w");
fprintf(file, "Критичные данные");
fflush(file); // Данные точно записались на диск
// дальше рискованные операции
|
|
Правильная обработка ошибок
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <stddef.h> // NULL
FILE *open_file(const char *filename) {
FILE *fp = fopen(filename, "r");
if (fp == NULL) {
// Ошибка - выводим в stderr
fprintf(stderr, "Ошибка: не могу открыть файл '%s'\n", filename);
perror("fopen"); // perror тоже пишет в stderr
}
return fp;
}
int main(void) {
FILE *fp = open_file("nonexistent.txt");
if (fp == NULL) {
// Эта ошибка будет видна даже при перенаправлении stdout
fprintf(stderr, "Программа не может продолжить работу\n");
return EXIT_FAILURE;
}
printf("Файл открыт успешно\n");
fclose(fp);
return EXIT_SUCCESS;
}
|
|
Символ EOF (End-Of-File т.е. "конец файла")
|
Символ EOF (End-Of-File т.е. "конец файла") в C — это целочисленная константа (macro constant), определенная в заголовочном файле <stdio.h>
#define EOF (-1)
EOF не является символом в том смысле, в каком им является буква 'A' или 'z'
Он гарантированно имеет отрицательное целочисленное значение (обычно -1)
В большинстве систем Unix и Linux нажатие комбинации клавиш <Ctrl+D> в начале строки вызывает передачу сигнала конца файла. Многие системы в качестве сигнала конца файла распознают комбинацию <Ctrl+Z> в начале строки, а некоторые интерпретируют ее как таковую в любом месте строки.
Функции ввода С не обнаруживают конец файла до тех пор, пока они не предпримут попытку чтения за концом файла. Это означает, что проверка на предмет конца файла должна производиться непосредственно после попытки чтения.
Это специальное значение, которое возвращают функции ввода/вывода (такие как getchar(), fgetc(), fscanf()) для обозначения двух важных условий:
- Достигнут фактический конец файла (End of physical file).
- Произошла ошибка ввода/вывода (I/O error) во время чтения.
Если бы EOF был в диапазоне 0 до 255, то он мог бы совпасть с реальным байтом данных из файла, и программа не смогла бы отличить, был ли прочитан этот байт или достигнут конец файла.
int c; // Всегда используйте int для результата getchar()
while ((c = getchar()) != EOF) {
putchar(c);
}
// для файлов
if (feof(file)) {
printf("Достигнут конец файла - всё нормально\n");
}
if (ferror(file)) {
perror("Произошла ошибка чтения");
}
// После выхода из цикла (когда c == EOF), программа знает, что чтение завершено.
|
|
Работа с бинарными данными
fread() - чтение бинарных данных из файла
fwrite() - запись бинарных данных в файл
size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream);
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
int id;
char name[50];
double price;
} Product;
int main(void) {
// Запись структур в бинарный файл
Product products[] = {
{1, "Товар A", 19.99},
{2, "Товар B", 29.99},
{3, "Товар C", 39.99}
};
FILE *file = fopen("products.bin", "wb");
if (!file) return EXIT_FAILURE;
// Запись массива структур
size_t count = sizeof(products) / sizeof(products[0]);
fwrite(products, sizeof(Product), count, file);
fclose(file);
// Чтение структур из бинарного файла
file = fopen("products.bin", "rb");
if (!file) return EXIT_FAILURE;
Product read_products[3];
fread(read_products, sizeof(Product), 3, file);
for (int i = 0; i < 3; i++) {
printf("ID: %d, Name: %s, Price: %.2f\n",
read_products[i].id, read_products[i].name, read_products[i].price);
}
fclose(file);
return EXIT_SUCCESS;
}
|
|
Управление позицией в файле
- SEEK_SET от начала файла
- SEEK_CUR от текущей позиции
- SEEK_END от конца файла
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
FILE *file = fopen("data.bin", "rb+");
if (!file) return EXIT_FAILURE;
int numbers[] = {10, 20, 30, 40, 50};
// Запись массива
fwrite(numbers, sizeof(int), 5, file);
// Перемещение к третьему элементу
fseek(file, 2 * sizeof(int), SEEK_SET);
// Чтение третьего элемента
int third_number;
fread(&third_number, sizeof(int), 1, file);
printf("Третий элемент: %d\n", third_number);
// Изменение третьего элемента
fseek(file, 2 * sizeof(int), SEEK_SET);
int new_value = 35;
fwrite(&new_value, sizeof(int), 1, file);
// Получение текущей позиции
long position = ftell(file);
printf("Текущая позиция: %ld\n", position);
// Перемещение в начало
rewind(file);
fclose(file);
return EXIT_SUCCESS;
}
|
|
Перенаправление ввода/вывода
Предоставляет программе возможность применять для ввода файл вместо клавиатуры, а перенаправление вывода — использовать для вывода файл вместо экрана.
|
Перенаправление ввода stdin
Символ < представляет собой операцию перенаправления ввода, поток stdin ассоциируется теперь с file и программа получает ввод из него:
program < file
Перенаправление вывода stdout
Символ > представляет собой операцию перенаправления вывода, поток stdout предназначенный для вывода на экран теперь выводит данные в new_file:
program > new_file
Комбинированное перенаправление потоков:
program < file > new_file
Перенаправление ошибок:
./program > output.log # stdout в файл, ошибки на экран
./program 2> errors.log # ошибки в файл, обычный вывод на экран
./program > output.log 2>&1 # все в один файл
Также доступна операция >>, которая позволяет добавлять данные в конец существующего файла, и операция конвейера (|), делающая возможным соединение вывода одной программы с вводом другой программы.
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
FILE *file = fopen("buffered.txt", "w");
// Установка размера буфера
char buffer[1024];
setvbuf(file, buffer, _IOFBF, sizeof(buffer));
// Типы буферизации:
// _IOFBF - полная буферизация
// _IOLBF - построчная буферизация
// _IONBF - без буферизации
fprintf(file, "Это буферизированная запись\n");
// Принудительная запись буфера
fflush(file);
fclose(file);
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Оператор if
По правилам C, else всегда привязывается к ближайшему if, у которого его нет !!!
if (условие_1) {
} else if (условие_2) {
} else {
}
|
А почему программы на C используют конструкции без фигурных скобок, например if или for, while это ведь к потенциальным ошибкам
Основная причина, кроется в его исторической цели: минимализм, эффективность и гибкость.
Когда C был создан 1970-х годах, компиляторы были менее мощными, и каждый символ, который нужно было обработать, имел значение.
Дизайнеры C (Деннис Ритчи и Кен Томпсон) стремились создать язык, который был бы как можно более минималистичным и не требовал лишних символов, скобки {} считались бы избыточными символами, которые замедляли бы набор кода и, хотя и незначительно, усложняли работу компилятора.
Пример: Ошибка "Висячий Else" (Dangling Else)
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(){
int x = 0;
if (true)
if (false)
x = 1;
else // <-- К какому if относится этот else?
x = 2;
printf("%i",x);// 2 это ошибка так как первый if должен был отработать, но у нас `else` подстроился к последнему `if`
return EXIT_SUCCESS;
}
Решение:
1. Флаг компиляции -Wall который добавляет флаг -Wdangling-else выводит предупреждение, что нет фигурных скобок
warning: suggest explicit braces to avoid ambiguous ‘else’ [-Wdangling-else]
8 | if (true)
| ^
2. Всегда использовать явную область видимости фигурными скобками
if(a > b){
...
}
Относительно ограничений компилятора следует отметить, что в стандарте С99 от компилятора требуется поддержка не менее 127 уровней вложенности.
if (condition1) { // Уровень 1
if (condition2) { // Уровень 2
if (condition3) { // Уровень 3
// ...
// Может быть до 127 таких вложенных if
}
}
}
|
|
Тернарный оператор (Ternary Operator)
|
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
int a = 10, b = 20;
// Находим максимальное число
int max = (a > b) ? a : b;
printf("Максимум: %d\n", max); // Вывод: 20
// Проверка четности
int number = 7;
char* result = (number % 2 == 0) ? "четное" : "нечетное";
printf("%d - %s\n", number, result); // Вывод: 7 - нечетное
return EXIT_SUCCESS;
}
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
void print_positive() {
printf("Положительное\n");
}
void print_negative() {
printf("Отрицательное\n");
}
int main() {
int num = -5;
// Вызов разных функций
(num >= 0) ? print_positive() : print_negative();
// В аргументах функций
printf("Число %d %s\n", num, (num >= 0) ? "положительное" : "отрицательное");
return EXIT_SUCCESS;
}
|
|
Синтаксис оператора switch
|
Для сопоставления в switch
- нельзя: использовать переменные, строки, float/double и выражения и const
- можно: макрос, литералы
(Почему нельзя переменные и т.д. в switch - потому что компилятор должен знать на этапе компиляции как построить таблицу переходов между состояниями switch, а переменные дают понимание только в момент выполнения в runtime)
Обработка нескольких значений одним case (это наз. проваливание, как вариант реализации диапазона значений):
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
char operation = '+';
int a = 10, b = 5;
switch (operation) {
case '+':
printf("Результат: %d\n", a + b);
break;
case '-':
case '*':
case '/':
printf("Операция %c пока не поддерживается\n", operation);
break;
default:
printf("Неизвестная операция\n");
}
return EXIT_SUCCESS;
}
Использование с enum (как замена переменных и т.д. того чего нельзя использовать)
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
enum Color { RED=49, GREEN, BLUE };
int main() {
// вместо int можно все что угодно использовать, главное сопоставить это с вариантом enum и его уже отдать в switch
int n = getchar();
printf("%d\n",n);// 1=49, 2=50
enum Color color = n == 49? RED: GREEN;
printf("%d\n",color);
switch (color) {
case RED:
printf("Красный\n");
break;
case GREEN:
printf("Зеленый\n");
break;
case BLUE:
printf("Синий\n");
break;
}
return EXIT_SUCCESS;
}
|
|
Оператор goto
Так не нужно с goto:
- Переход вперед через инициализацию переменных
- Создание спагетти-кода
- Переход внутрь блока (внутрь if, for, while)
|
Конечный автомат (state machine):
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
int state = 0;
start:
printf("Состояние: %d\n", state);
switch (state) {
case 0:
printf("Переходим в состояние 1\n");
state = 1;
goto start;
case 1:
printf("Переходим в состояние 2\n");
state = 2;
goto start;
case 2:
printf("Конец автомата\n");
goto end;
}
end:
return EXIT_SUCCESS;
}
Выход из вложенных циклов (главное легальное применение):
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
for (int i = 0; i < 5; i++) {
for (int j = 0; j < 5; j++) {
printf("i=%d, j=%d\n", i, j);
if (i == 2 && j == 2) {
printf("Нашли нужное условие! Выходим из всех циклов\n");
goto exit_all_loops; // Чистый выход из вложенных циклов
}
}
}
exit_all_loops:
printf("Продолжаем работу после циклов\n");
return EXIT_SUCCESS;
}
Обработка ошибок (второе легальное применение):
#include <stdio.h>
#include <stdlib.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <stddef.h> // NULL
int main() {
FILE *file1 = NULL, *file2 = NULL, *file3 = NULL;
file1 = fopen("file1.txt", "r");
if (file1 == NULL) {
goto cleanup; // Ошибка - переходим к очистке
}
file2 = fopen("file2.txt", "r");
if (file2 == NULL) {
goto cleanup; // Ошибка - переходим к очистке
}
file3 = fopen("file3.txt", "r");
if (file3 == NULL) {
goto cleanup; // Ошибка - переходим к очистке
}
printf("Все файлы открыты успешно!\n");
// Работаем с файлами...
cleanup:
// Централизованная очистка ресурсов
if (file1) fclose(file1);
if (file2) fclose(file2);
if (file3) fclose(file3);
printf("Ресурсы освобождены\n");
return EXIT_SUCCESS;
}
|
|
Библиотека setjmp.h в С — предназначенная для прыжков в коде (нелокальное изменение потока выполнения).
|
Только в крайних случаях:
- Имитация исключений в C
- Быстрый выход из глубокой рекурсии
- Реализация co-routines (очень редко)
- Реакция на критические сигналы
- Старые C-проекты, написанные до эпохи safer-C
Пример Мини-механизм TRY / CATCH / THROW в C
#include <stdio.h>
#include <setjmp.h>
jmp_buf __exc_env;
int __exc_value = 0;
#define TRY if ((__exc_value = setjmp(__exc_env)) == 0)
#define CATCH else
#define THROW(x) longjmp(__exc_env, x)
// Функция, которая "кидает исключение"
void do_work(int n) {
if (n == 0) {
THROW(100); // бросили ошибку с кодом 100
}
printf("Работаем нормально: n=%d\n", n);
}
int main(void) {
TRY {
printf("Начинаем TRY...\n");
do_work(0);
printf("ЭТА строка уже не выполнится\n");
}
CATCH {
printf("Поймано исключение! Код = %d\n", __exc_value);
}
printf("Программа продолжила работу после CATCH\n");
return 0;
}
|
|
|
|
|
sizeof — это встроенная операция, работает во время компиляции (если возможно) и возвращает размер объекта или типа в байтах.
Для вывода значений типа size_t в printf(), вы должны использовать спецификатор формата %zu
|
sizeof возвращает целое число без знака (size_t) представляющее размер типа в байтах
- в C89/C90: sizeof возвращает тип unsigned int тогда спецификаторы
%u или %lu
- в C99 и выше: sizeof возвращает тип size_t тогда спецификаторы
%zu
А size_t — это typedef на unsigned long (%lu) или unsigned long long (%llu), в зависимости от платформы, поэтому, вы должны использовать спецификатор формата %zu
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
printf("sizeof(int) = %zu\n", sizeof(int)); // 4
printf("sizeof(long double) = %zu\n", sizeof(long double)); // 16
printf("sizeof(int) = %zu\n", sizeof(int)); // 4
return EXIT_SUCCESS;
}
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define LENGTH_NAME 40
#define MY_TEXT "Hello" // компилятор сам добавит \0
int main(void) {
char name[LENGTH_NAME]={};
int size = sizeof name;
printf("size=%zu\n", size); // 40
printf("size=%zu\n",sizeof MY_TEXT); // 6
return EXIT_SUCCESS;
}
В заголовочной файле limits.h содержатся константы размерности типов
#include <stdio.h>
#include <limits.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
printf("B данной системе один байт = %d бит\n",CHAR_BIT);// B данной системе один байт = 8 бит
printf("SCHAR_MIN=%d\n",SCHAR_MIN);// -128
printf("SCHAR_MAX=%d\n",SCHAR_MAX);// 127
printf("UCHAR_MAX=%d\n",UCHAR_MAX);// 255
printf("SHRT_MIN=%d\n",SHRT_MIN);// -32768
printf("SHRT_MAX=%d\n",SHRT_MAX);// 32767
printf("USHRT_MAX=%d\n",USHRT_MAX);// 65535
printf("INT_MIN=%d\n",INT_MIN);// -2147483648
printf("INT_MAX=%d\n",INT_MAX);// 2147483647
printf("UINT_MAX=%u\n",UINT_MAX);// 4294967295
printf("LONG_MIN=%ld\n",LONG_MIN);// -9223372036854775808
return EXIT_SUCCESS;
}
|
|
Размеры типов данных.
Размеры элементарных типов данных в С и C++ не определены.
Имеются только следующие базовые правила:
sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long)
sizeof(float) <= sizeof(double)
Тип char должен иметь длину как минимум 8 бит, short и int — как минимум 16, a long — не менее 32.
Никакие другие свойства не гарантируются.
Отсутствует даже требование, чтобы значение указателя помещалось в переменную типа int.
|
Обычно int выбирается как размер одного машинного слова — т.е. того, что процессор обрабатывает за одну операцию.
Стандарт C99 требует только, чтобы int был не меньше 16 бит.
На современных 32-битных и 64-битных системах int обычно 4 байта
В 8-разрядных микрокомпьютерах, таких как первые машины Apple, слово состояло из 8 битов. С тех пор персональные компьютеры перешли на 16-битные, 32-битные, а в настоящее время и 64-битные слова.
На 64-битных системах int чаще всего остаётся 4 байта, а не 8, потому что стандарт не требует иначе, и это сохраняет совместимость со старым кодом.
Типичные размеры int для популярных микроконтроллеров
| Архитектура | Пример MCU | Компилятор | Размер int | Комментарий |
|---|
| 8-бит | AVR (Atmega328, Arduino UNO), PIC8 | avr-gcc | 2 байта (16 бит) | хотя MCU 8-битный, int = 16 бит для удобства арифметики |
| 16-бит | MSP430 | msp430-gcc | 2 байта (16 бит) | соответствует размеру слова |
| 32-бит | ARM Cortex-M (STM32, ESP32, nRF52) | arm-none-eabi-gcc | 4 байта (32 бита) | совпадает с размером машинного слова |
| 64-бит | редко в MCU | — | 4 или 8 байт | обычно 4 для совместимости |
| Тип | Размер (байт/бит) | Диапазон | Примечание |
|---|
char | 1 (8) | −128 … 127 | знаковый по умолчанию зависит от компилятора |
signed char | 1 (8) | −128 … 127 | явно знаковый |
unsigned char | 1 (8) | 0 … 255 | беззнаковый |
short int | 2 (16) | −32 768 … 32 767 | также signed short int |
unsigned short int | 2 (16) | 0 … 65 535 | |
int | 4 (32) | −2 147 483 648 … 2 147 483 647 | типичный размер на 32/64-битных системах |
unsigned int | 4 (32) | 0 … 4 294 967 295 | |
long int | 4 (32) | −2 147 483 648 … 2 147 483 647 | 32-бит на большинстве систем, на 64-битных Linux long = 8 байт |
unsigned long int | 4 (32) | 0 … 4 294 967 295 | |
long long int | 8 (64) | −9 223 372 036 854 775 808 … 9 223 372 036 854 775 807 | введён в C99 |
unsigned long long int | 8 (64) | 0 … 18 446 744 073 709 551 615 | |
float | 4 (32) | ±3.4×10⁻³⁸ … ±3.4×10³⁸ | IEEE 754 single precision |
double | 8 (64) | ±1.7×10⁻³⁰⁸ … ±1.7×10³⁰⁸ | IEEE 754 double precision |
long double | 10 (80) | ±3.4×10⁻⁴⁹³² … ±3.4×10⁴⁹³² | IEEE 754 extended precision, может быть 12/16 байт в памяти |
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
printf("sizeof(_Bool) = %zu\n", sizeof(_Bool)); // 1 byte
printf("sizeof(char) = %zu\n", sizeof(char)); // 1 byte
printf("sizeof(signed char) = %zu\n", sizeof(signed char)); // 1 byte
printf("sizeof(unsigned char) = %zu\n", sizeof(unsigned char)); // 1 byte
printf("sizeof(short) = %zu\n", sizeof(short)); // 2 bytes
printf("sizeof(unsigned short) = %zu\n", sizeof(unsigned short)); // 2 bytes
printf("sizeof(int) = %zu\n", sizeof(int)); // 4 bytes
printf("sizeof(unsigned int) = %zu\n", sizeof(unsigned int)); // 4 bytes
printf("sizeof(long) = %zu\n", sizeof(long)); // 8 bytes
printf("sizeof(unsigned long) = %zu\n", sizeof(unsigned long)); // 8 bytes
printf("sizeof(long long) = %zu\n", sizeof(long long)); // 8 bytes
printf("sizeof(unsigned long long) = %zu\n", sizeof(unsigned long long)); // 8 bytes
printf("sizeof(float) = %zu\n", sizeof(float)); // 4 bytes
printf("sizeof(double) = %zu\n", sizeof(double)); // 8 bytes
printf("sizeof(long double) = %zu\n", sizeof(long double)); // 16 bytes
// заначение тоже можно использовать
// sizeof (array[0])
return EXIT_SUCCESS;
}
|
|
Правильный подход для переносимого кода
Целочисленные типы фиксированной ширины начиная с C99 в библиотеке stdint.h
Однако не все системы могут поддерживать все эти типы.
Есть еще типы с минимальной допустимой шириной int_leastt8_t и самые быстрые типы с минимальной шириной int_fast8_t и типы с максимальной шириной int_max_t
|
Для языка C:
- Тип данных long в 32-разрядных программах обычно имеет размер 4 байта, а в 64-разрядных – 8 байт.
- Тип
void* (любой указатель) в 32-разрядных программах 4 байта (32 бита), а в 64-разрядных – 8 байт (64 бита).
- Тип size_t в 32-разрядных программах 4 байта (32 бита), а в 64-разрядных – 8 байт (64 бита)
// Использовать фиксированные типы:
#include <stdint.h> // int8_t, int32_t ...
#include <inttypes.h>
#include <stddef.h>
int8_t - int 8 bit (1 byte) // Всегда 8 бит // тоже самое signed char
int16_t - int 16 bit (2 byte) // Всегда 16 бит
int32_t - int 32 bit (4 byte) // Всегда 32 бита
int64_t - int 64 bit (8 byte) // Всегда 64 бита
uint8_t - unsigned int 8 bit (1 byte)
uint16_t - unsigned int 16 bit (2 byte)
uint32_t - unsigned int 32 bit (4 byte)
uint64_t - unsigned int 64 bit (8 byte)
uintptr_t c; // Беззнаковый тип, вмещающий указатель void*
size_t d; // Для размеров объектов (меняется с разрядностью)
// Раньше в 32-битном коде часто писали:
unsigned long ptr_value = (unsigned long)pointer; // Работало
// В 64-битном (Windows) — потеря данных, т.к. long=32 бита!
Например, многие программисты традиционно полагали, что объект, объявленный с типом int, можно использовать для хранения указателя. Это предположение было справедливо для большинства 32-разрядных программ, но привело к проблемам в 64-разрядных программах.
Проблема в потере данных. Когда 64-битный указатель пытаются записать в 32-битный int:
void* pointer = malloc(1000); // Указатель, например, 0x00007F1234567890 (64 бита)
int stored_ptr = (int)pointer; // ОСТРЕЗАНИЕ! Сохранится только 0x34567890
64-битный указатель (8 байт) был обрезан до 32 бит (4 байта). Потерялись старшие 32 бита.
Обратная проблема: восстановление указателя
// Восстанавливаем указатель из int
void* restored_ptr = (void*)stored_ptr; // Будет 0x0000000034567890
// АДРЕС НЕВЕРНЫЙ! Должно быть 0x00007F1234567890
Результат: программа пытается обратиться к памяти по неверному адресу → segmentation fault.
Но даже для 32-битной системы есть проблема: знаковость int — знаковый тип (-2³¹...2³¹-1)
Указатели (адреса) часто имеют старший бит = 1 в 64-битном режиме.
void* ptr = (void*)0xFFFFFFFF87654321; // Старший бит = 1
int i = (int)ptr; // Преобразование с сохранением знака!
// Может дать отрицательное число
if (i > 0) { // Условие не выполнится для отрицательных!
// код
}
|
|
Типы данных простые
(5 типов от стандарта C89)
- char - символьный;
- int - целый;
- float - вещественный;
- double - вещественный двойной точности;
- void - не имеющий значения.
(3 типа от стандарта C99)
- _Bool (логический)
- _Complex (комплексные числа)
- _Imaginary (мнимые значения типов данных)
Спецификаторы базового типа:
- unsigned (беззнаковый, только положительные)
- signed (знаковый, плюс и минус)
- short (Укороченный целый тип (меньше, чем int)) от −32 768 до 32 767
- long (Расширенный целый тип (больше int)) от −2 147 483 648 до 2 147 483 647 (на 32-битах) или шире
Полная таблица специальных значений:
| Значение | Тип | Заголовок | Описание |
|---|
| NULL | void* | <stddef.h> | Нулевой указатель |
| NAN | float/double | <math.h> | "Not a Number" |
| INFINITY | float/double | <math.h> | Бесконечность |
| HUGE_VAL | double | <math.h> | Очень большое число |
|
Целые числа со знаком (при желании для любого типа со знаком можно указывать ключевое слово signed, делая
явным тот факт, что этот тип поддерживает знак):
- int
- short или short int
- long или long int
- long long или long long int
signed long long int x = -8;
printf("%lld\n" , x);// -8
Целые числа без знака (указывайте ключевое слово unsigned перед
желаемым типом):
- unsigned int или unsigned
- unsigned short
- unsigned long или тоже самое (unsigned long int, long unsigned, long unsigned int)
Тип unsigned int: %u = 10
Тип unsigned short: %hu = 11
Тип unsigned long: %zu = 12
Тип unsigned long long: %llu = 13
Тип size_t: %zu = 4 ( "unsigned long" %lu or "unsigned int" %u )
unsigned x = 8;
printf("%lld\n" , x);// 8
Символы (в одних реализациях применяется тип char со
знаком, в других он без знака. Язык С позволяет использовать ключевые слова signed и
unsigned для указания нужной формы)
- signed char
- unsigned char
Исторически сложилось так, что байт символа чаще всего имеет длину 8 битов, но он может быть длиной 16 битов или больше, если это необходимо для представления базового набора символов.
Тип unsigned char (число): %hhu = 120
Тип unsigned char (символ): %c = x
Тип signed char (число): %hhd = -1
Тип signed char (символ): %c = �
Тип char*: %s = Hello
Булевские значения
Логический тип _Bool или bool (unsigned int). Значения true/false определены в stdbool.h
Для представления true применяется 1, а для представления false — 0
Вещественные числа с плавающей запятой (эти типы могут иметь как положительные, так и отрицательные значения т.е. они signed):
Тип float: %f = -1.000000
Тип double: %lf = 3.140000
Тип long double: %Lf = 3.140000
float a = 8.0f;
float b = -8.0f;
double c = 5.0;
double d = -5.0;
long double ld = 5.5L;
printf("%f %f %lf %lf %Lf", a, b, c, d, ld);
|
|
Переполнение (Overflow) знаковых signed типов
для signed char:
0 00000000
1 00000001
2 00000010
...
125 01111101
126 01111110
127 01111111
-128 10000000 !!!
-127 10000001
-126 10000010
...
-2 11111110
-1 11111111
0 00000000 !!!
|
В языке C нельзя выполнять арифметику напрямую с типами меньше, чем int
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char signed x = 127;
printf("%d\n",x + (char signed)1);// 128 из-за Integer Promotion (целочисленное продвижение). Число 1 это signed int поэтому x приводится к int
printf("%d\n", (char)(x + 1)); // -128 а вот явное приведение 128 к char signed приведет к переполнению
return EXIT_SUCCESS;
}
В дополнительном коде после для int8_t 127 идет -128. Если ты пишешь цикл for (int8_t i = 0; i < 150; i++), он станет вечным, потому что i никогда не дойдет до 150 — оно превратится в минус и пойдет по кругу.
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
//signed char i = 120;// тоже самое int8_t
int8_t i = 120;
while (i <= 127) {
printf("%d\n", i);
i++; // Здесь случится прыжок 127 -> -128
if (i == 5) break;
}
return EXIT_SUCCESS;
}
|
|
Переполнение (Overflow) беззнаковых unsigned типов
|
Невидимый «бесконечный» цикл
Ошибка «Длина массива» strlen(s) - 1 при пустой строке не дает -1. Оно дает гигантское положительное число
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
// так как тип беззнаковый, 0 - 1 превращается в 4 294 967 295. Это число больше нуля, условие снова истинно, и цикл никогда не остановится.
for (unsigned int i = 10; i >= 0; i--) {
printf("%u ", i);
}
return EXIT_SUCCESS;
}
|
|
В языке C спецификатор PRId32, PRIu64 (и им подобные из библиотеки inttypes.h) нужен для того, чтобы твой код был портативным.
При компиляции 64-разрядной программы макрос PRId32 разворачивается в строку "d"
, а PRIu64 – в пару строк "l" "u"
|
На одной системе int32_t — это int 4 byte/32 bit. Нужно писать printf("%d", x)
На другой системе int32_t — это long 4 byte/32 bit. Нужно писать printf("%ld", x)
Макрос PRId32 заменяется на нужную букву ("d" или "ld") прямо перед компиляцией.
#include <stdio.h>
#include <stdint.h>
#include <inttypes.h> // Обязательно для макросов PRI
int main() {
int32_t x = 123;
// мы пишем так:
printf("Число: %" PRId32 "\n", x); // компилятор склеивает разрыв строки
// компилятор превращает это либо в:
// printf("Число: %" "d" "\n", x);
// либо в:
// printf("Число: %" "ld" "\n", x);
}
|
|
Помощник спецификаторов форматирования
all-ht.ru
dfe.petrsu.ru
|
standart C11
Макрос, который возвращает строку (спецификатор) в зависимости от типа
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define get_format_specifier(X) _Generic((X), \
unsigned char: "%hhu", \
unsigned int: "%u", /* or %x for 16 base*/\
unsigned short: "%hu", \
unsigned long: "%lu", /* or %lx for 16 base or %lo for 8 base*/ \
unsigned long long: "%llu", /* or %llx for 16 base or %llo for 8 base*/\
signed char: "%hhd", \
signed int: "%d", /* or %i. Default int. Spec %d for decimal. How work "%i" => If value "0x..." or "0X..." -> 16 base. If value "05.." -> 8 base */\
signed short: "%hd", /* or %hi */ \
signed long: "%ld", /* or %li */\
signed long long: "%lld", /* or %lli */\
float: "%f", /* or %e or %g. Default %.6f but float contains %.6f - %.9f */\
double: "%lf", /* or %lg. Default %.6f but double contains %.15f - %.17f */\
long double: "%Lf",/* or %Lg. Default %.6f but long double contains %.18f - %.19f */\
char*: "%s",\
void*: "%p",\
size_t: "%zu", /* equivalent "unsigned long" %lu or "unsigned int" %u */\
default: "Неизвестный тип" \
)
int main(void) {
unsigned char un0 = 120;
unsigned int un1 = 10; // equivalent size_t
unsigned short un2 = 11;
unsigned long un3 = 12LU; // equivalent size_t
unsigned long long un4 = 13LLU;
printf("Тип unsigned char (число): %s = %hhu\n", get_format_specifier(un0), un0);
printf("Тип unsigned char (символ): %%c = %c\n", un0);
printf("Тип unsigned int: %s = %d\n", get_format_specifier(un1),un1);
printf("Тип unsigned short: %s = %hu\n", get_format_specifier(un2), un2);
printf("Тип unsigned long: %s = %lu\n", get_format_specifier(un3), un3);
printf("Тип unsigned long long: %s = %llu\n", get_format_specifier(un4), un4);
printf("\n-----------------------------------------\n");
signed char sn0 = -1;
signed int sn1 = -10;
signed short sn2 = -11;
signed long sn3 = -12L;
signed long long sn4 = -13LL;
printf("Тип signed char (число): %s = %hhd\n", get_format_specifier(sn0), sn0);
printf("Тип signed char (символ): %%c = %c\n", sn0);
printf("Тип signed int: %s = %d\n", get_format_specifier(sn1),sn1);
printf("Тип signed short: %s = %hd\n", get_format_specifier(sn2), sn2);
printf("Тип signed long: %s = %ld\n", get_format_specifier(sn3), sn3);
printf("Тип signed long long: %s = %lld\n", get_format_specifier(sn4), sn4);
printf("\n-----------------------------------------\n");
float f = -1.0f;
double d = 3.14;
long double ld = 3.14L;
char *s = "Hello";
size_t sz = sizeof(sn1);
printf("Тип float: %s = %.6f\n", get_format_specifier(f), f);
printf("Тип double: %s = %.6lf\n", get_format_specifier(d), d);
printf("Тип long double: %s = %.6Lf\n", get_format_specifier(ld), ld);
printf("Тип char*: %s = %s\n", get_format_specifier(s), s);
printf("Тип size_t: %s = %zu\n", get_format_specifier(sz), sz);
// Use
long double your_type = 0.5487L;
const char *target_fmt = get_format_specifier(your_type);
printf(target_fmt, your_type);
return EXIT_SUCCESS;
}
|
|
|
|
|
Литералы
- вещественных чисел
- натуральных чисел
Стандарт языка С требует, чтобы тип float был способен представлять минимум шесть значащих цифр и охватывал диапазон значений, по меньшей мере, от 10^-37 до 10^+37
Часто для хранения чисел с плавающей запятой системы используют 32 бита. Восемь битов отводятся под значение экспоненты и ее знака, а остальные 24 бита служат для представления экспоненциальной части числа, которая называется мантисса или значащей частью числа, и ее знака.
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
double a = 5.5;
float b = 5.5f; // явное использование суффикса f убирает стандартное поведение компилятора складывать double а после приводить к float
long double c = 5.5L;
printf("%f %f %Lf\n", a, b, c);
printf("%Le", c);// 5.500000e+00
float planck = 6.63e-34;
float n = .8;
printf("%f %f" , planck, n);
// по умолчанию вещественные числа константы имеют тип double. Для явного использования float нужен суффикс f или F
printf("sizeof(float) = %zu\n", sizeof(float)); // 4 bytes
printf("sizeof(double) = %zu\n", sizeof(double)); // 8 bytes
printf("sizeof(5.0) = %zu\n", sizeof(5.0)); // 8 bytes
printf("sizeof(5.0f) = %zu\n", sizeof(5.0f)); // 4 bytes
{
long long int a = 3LL;
unsigned long long int b = 3ULL;
unsigned long long int c = 3LLU;
printf("%lld %llu %llu\n", a, b, c);
}
return EXIT_SUCCESS;
}
Суффиксы натуральных чисел
| Суффикс | Тип литерала |
|---|
L | long int |
LL | long long int |
U | unsigned int |
UL / LU | unsigned long int |
ULL / LLU / LU | unsigned long long int |
Суффиксы вещественных чисел
| Суффикс | Тип |
|---|
| (нет) | double |
f / F | float |
l / L | long double |
|
|
Константы #define и const (символическая константа, литерал)
Вывод вещественных чисел
|
Во время компиляции препроцессор произведет подстановку значения констант в код
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define LENGTH_NAME 9
#define MY_TEXT "Женя" // компилятор сам добавит \0
#define PI_F 3.1415926535897932384626433832795028841971f // float хранит 6–9 знаков после запятой
#define PI_D 3.1415926535897932384626433832795028841971 // double хранит 15–17 знаков после запятой
#define PI_LD 3.1415926535897932384626433832795028841971L // long double хранит 18–19 знаков после запятой
или через const
const float PI_F = 3.141593f;
const double PI_D = 3.141592653589793;
const long double PI_LD = 3.141592653589793239L;
int main(void) {
// по умолчанию printf/scanf выводит только 6 знаков после запятой
printf("%.6f\n", PI_F); // 3.141593
printf("%.15f\n", PI_D); // 3.141592653589793
printf("%.18Lf\n", PI_LD); // 3.141592653589793239
return EXIT_SUCCESS;
}
|
|
О сравнении чисел с плавающей запятой
|
При сравнении чисел с плавающей запятой вы должны использовать только операции < и >.
Это объясняется тем, что из-за ошибок округления два числа могут оказаться неравными, хотя логически они должны быть равны.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
printf("%d",1.12345678f == 1.12345678f);//1
printf("%d",1.123456789f == 1.123456785f);//1 - может сранивать 8 знаков, а 9 знаков уже не может
return EXIT_SUCCESS;
}
|
|
Ошибки округления данных с плавающей запятой
У double мантисса = 52 бита
У float мантисса = 23 бита
У long double (x86 80-bit) ≈ 64 бита
|
Причина получения таких странных результатов состоит в том, что компьютер не следит за тем, чтобы под числа с плавающей запятой было отведено столько десятичных позиций, сколько нужно для правильного выполнения операции.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
{
float x = 2.0E20;
float a = x + 1.0;
float b = a - x;
printf("%f \n", b);// 0.000000
}
{
float a = 2.0E20 + 1.0;
float b = a - 2.0E20;
printf("%f \n", b);// 4008175468544.000000
}
return EXIT_SUCCESS;
}
Число 2.0E20 представлено цифрой 2, за которой следует 20 нулей, и за счет прибавления 1 вы пытаетесь изменить 21-ю цифру. Чтобы эта операция выполнилась корректно, программа должна иметь возможность хранить число, состоящее из 21 цифры. Число типа float — это обычно шесть или семь цифр, масштабированных при помощи показателя степени до большего или меньшего числа, так что такая попытка сложения обречена на неудачу. С другой стороны, если вместо 2.0E20 вы укажете 2.0E4, то получите правильный ответ, поскольку вы пытаетесь изменить пятую цифру, а числа типа float обладают достаточной для этой операции точностью.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
{
long double a = 2.0E18L + 1.0L;
long double b = a - 2.0E18L;
printf("%Lf \n", b);// 1.000000
}
{
double a = 2.0E15 + 1.0;
double b = a - 2.0E15;
printf("%f \n", (double)b);// 1.000000
}
{
float a = 2.0E4f + 1.0f;
float b = a - 2.0E4f;
printf("%f \n", b);// 1.000000
}
return EXIT_SUCCESS;
}
|
|
Константы для float в библиотеке float.h
|
#include <stdio.h>
#include <float.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// Минимальное количество значащих десятичных цифр для типа floa t
printf("FLT_DIG=%d\n",FLT_DIG);// 6
// Количество битов в мантиссе типа float
printf("FLT_MANT_DIG=%d\n",FLT_MANT_DIG);// 24
// Минимальное значение для положительного числа типа float, сохраняющего полную точность
printf("FLT_MIN=%e\n",FLT_MIN);// 1.175494e-38
// Максимальное значение для положительного числа типа float, сохраняющего полную точность
printf("FLT_MAX=%f\n",FLT_MAX);// 340282346638528859811704183484516925440.000000
// Наибольшее значение типа double
printf("DBL_MAX=%e\n",DBL_MAX);// 1.797693e+308
return EXIT_SUCCESS;
}
|
|
Вещественное число в шестнадцатеричной системе
|
Начиная со стандарта С99, в языке С имеется новый формат для выражения констант с плавающей запятой.
В нем применяется шестнадцатеричный префикс (Ох или ОХ) с шестнадцатеричными цифрами, р или Р вместо е или Е и экспонента, которая является степенью 2, а не 10.
0xa.1fp10 = (10 + 1/16 + 15/256)*1024=10364.0 в десятичной форме записи
где:
a это 10 в шестнадцатеричной системеf это 15 в шестнадцатеричной системе.1f значит 1/16 + 15/256p10 это 2^10=1024
Пример:
#include <stdio.h>
int main(void) {
float n = 0xa.1fp10;
printf("%f", n); // 10364.000000
return 0;
}
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// шестнадцатеричный формат вещественных числе
float a = 10364.0;
float b = 0x1.43ep+13;
printf("%a\n", a); // 0x1.43ep+13
printf("%f\n", b); // 10364.000000
return EXIT_SUCCESS;
}
|
|
Переполнение вещественного типа
|
Переполнение типа
Поведение системы в таких случаях обычно не определено, но в рассматриваемой ситуации переменной toobig присваивается специальное значение, которое обозначает бесконечность
#include <stdio.h>
#include <math.h> // для констант NAN и INFINITY и функций isnan, isnanf, isnanl
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
float toobig = 3.4E38 * 100.0f;
printf("%e\n", toobig);// inf
float n = toobig - (toobig - 1);
printf("%e\n", n);//-nan NaN (not-a-number —не число)
return EXIT_SUCCESS;
}
А что можно сказать о делении очень малых чисел? - дает субнормальное значение (значения с плавающей запятой, которые утратили полную точность типа)
|
|
signed overflow (переполнение типа) в C формально неопределённое поведение, компилятор может оптимизировать код непредсказуемо. На практике почти всегда это циклическое переполнение
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
int i = 2147483647;
unsigned int j = 4294967295;
printf("%d %d %d\n", i, i+1, i+2);// 2147483647 -2147483648 -2147483647
printf("%u %u %u\n", j, j+1, j+2);// 4294967295 0 1
return EXIT_SUCCESS;
}
Переполнение знакового int — поведение неопределённое в стандарте C, но на большинстве компиляторов (дополняющий код) происходит «wrap-around»
Решение: Проверять переполнение в ручную перед операцией:
#include <limits.h>
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
int i = INT_MAX;
if (i < INT_MAX) {
i += 1;
} else {
printf("Переполнение! Нельзя прибавлять.\n");
}
return EXIT_SUCCESS;
}
|
|
16-ричная и 8-ричная форма записи
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
int a = 100; // десятичный литерал
int hex = 0x81; // 16-ричная форма
int oct = 011; // 8-ричная форма (любая константа, начинающаяся с 0)
printf("десятичное %d\n", a);// 100
printf("8-ричное %o\n", a); // 144
printf("16-ричное %x\n", a); // 64
long unsigned int b = 100lu;
printf("16-ричное %lx\n", b); // 64
printf("8-ричное %#o\n", a); // 0144
printf("16-ричное %#x\n", a); // 0x64
return EXIT_SUCCESS;
}
Возможность применения разных систем счисления является лишь удобством для программистов.
Поскольку 8 и 16 представляют собой степени числа 2, а 10 - нет, восьмеричная и шестнадцатеричная системы счисления более удобны для представления чисел, связанных с компьютерами.
Например, число 65536, которое часто встречается в 16-разрядных машинах, в шестнадцатеричной форме записывается как 10000. Кроме того, каждая цифра шестнадцатеричного числа соответствует в точности 4 битам.
Например, шестнадцатеричная цифра 3 - это 0011, а шестнадцатеричная цифра 5 - это 0101.
Таким образом, шестнадцатеричному значению 35 соответствует битовая комбинация 0011 0101, а шестнадцатеричному значению 53 - 010 1 0011. Такое соответствие позволяет облегчить переход от шестнадцатеричного представления числа к двоичному представлению (по основанию 2) и обратно.
Восьмеричные и шестнадцатеричные константы трактуются как значения типа int, если их значение не слишком велико. Затем компилятор примеривает к ним тип unsigned int. Если и его не хватает, компилятор последовательно пробует типы long, unsigned long, long long и unsigned long long.
|
|
Логический тип _Bool или bool
значения true/false определены в stdbool.h
|
#include <stdio.h>
#include <stdbool.h> // для true false
#include <math.h> // для NAN INFINITY
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
_Bool is = false;// только 0 является ложью, НО все остальное: отрицательные числа, пустые строки - это все истина true
printf("%d\n", is );// 0
is = 0;
printf("%d\n", is );// 0
// За счет автоматического преобразования типов, строка преобразуется в число-мусор которое подходит под истину true
int count = "";
printf("%d\n", count);// -711057404
_Bool b = count;
printf("%d\n", b);// 1
b = -45;
printf("%d", b);// 1
float f_nan = NAN; // или так = 1.0 / 0.0;
double d_inf = INFINITY; // или так = -1.0 / 0.0;
printf("%f\n", f_nan);// nan
printf("%lf\n", d_inf);// inf
b = f_nan;
printf("%d\n", b);// 1
b = d_inf;
printf("%d\n", b);// 1
return EXIT_SUCCESS;
}
Операции отношений: <, >, <=, >=, ==, !=
Если выражение (1 > 0) истинно, то условное выражение имеет значение 1 что эквивалентно true.
Если отношение ложно (1 == 0), то условное выражения получает значение 0 что эквивалентно false.
Например, программисты часто забывают, что знаки операций & и |имеют более низкий приоритет, чем == и ! =, и пишут так:
if (х & 1 == 0) // ошиблись вместо`&&` использовали `&`
...
Выражение в скобках всегда ложно, поэтому блок никогда не выполняется, а программист этого не осознает.
Так как после 1 == 0 получаем 0 и далее побитовая операция AND х & 0 что всегда равно 0, независимо от значения x
|
|
iso646.h заголовочный файл с альтернативными логическими символами: and, or, not
Язык C разрабатывали в США и их раскладка клавиатуры была не везде, где использовали язык C, следовательно, не везде были логические символы &&,||,! которые заменили на слова
|
#include <stdio.h>
#include <iso646.h>
#include <assert.h> // для assert()
#include <stdlib.h> // для EXIT_SUCCESS и abort(), если assert сработает
int main(void) {
assert(1 and 1); // &&
assert(0 or 1); // ||
assert( not 0); // !=
return EXIT_SUCCESS;
}
|
|
|
#include <stdio.h> // библиотека ввода/вывода
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
int a = 7;
int b = 4;
int res = a%b;
return EXIT_SUCCESS;
}
|
|
Округление до ближайшего целого
round
|
#include <stdio.h>
#include <math.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// Округление до ближайшего целого
printf ("round : %.1f\n", round (2.83) ); // 3.0
nearbyint, nearbyintf, nearbyintl – округление до ближайшего целого
round, roundf, roundl - округление до ближайшего целого
rint, rintf, rintl - округление до ближайшего целого
return EXIT_SUCCESS;
}
|
|
Операция приведения типов
(оно по определению явное, а преобразование это неявное автоматическое)
// -Werror -Wconversion - флаги компиляции для отлова неявных преобразований с потерями
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int a = 5;
int b = 3;
float c = (float) a / (float) b;
float c2 = (float) a / b; // Error происходит автоматическое преобразование, флаг -Wconversion выдаст предупреждение
float d = c / 2.0f;
printf("%f",c);// 1.666667
printf("%f",d);// 0.833333
return EXIT_SUCCESS;
}
Золотое правило: "Тихая" конверсия в Unsigned
Если в выражении (сравнение, сложение, умножение) участвуют типы одинакового размера (например, int и unsigned int), то signed приводится к unsigned.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
unsigned int a = 10;
int b = -20;
if (b > a) {
printf("Математика сломалась: -20 больше чем 10\n");
}
// Число -20 (signed) приводится к unsigned int.
// В памяти -20 в дополнительном коде — это очень большое число (например, 4 294 967 276).
// Естественно, оно больше, чем 10
return EXIT_SUCCESS;
}
Если типы разного размера (например, unsigned char и int), то сначала оба приводятся к int (потому что int может вместить все значения unsigned char).
Смешивание при сравнении (Самое опасное)
Никогда не сравнивайте int i и unsigned j напрямую в циклах, если i может быть отрицательным.
дело в том что тип unsigned при значении 0 и отнимании от него 1 мы не получаем -1 мы получаем переполнение типа и значение становится максимально положительным для данного типа. И по правилам приведения компилятор видя 1 (по умолчанию signed) с операцией unsigned, приведет 1 к типу unsigned, потому что unsigned больше тип чем signed
for (int i = -1; i < (unsigned int)1; i++) {
// Этот цикл НЕ ВЫПОЛНИТСЯ ни разу!
}
// -1 превращается в 4294967295 (максимальный uint32), и условие 4294967295 < 1 сразу становится ложным.
тоже пример операция сравнения signed с unsigned:
// Проблема кроется в выражении length - 1, когда length равен 0.
// В мире беззнаковых чисел 0 - 1 не превращается в -1, а в 4294967295.
// Вместо этого происходит underflow (зацикливание вниз).
float sum_elements(float a[], unsigned length) {
int i;
float result = 0;
for (i = 0; i <= length-1; i++)
result += a[i];
Потеря данных (Truncation)
// Когда принудительно приводим большое число к маленькому типу:
unsigned int x = 300;
unsigned char y = (unsigned char)x;// результат будет 300 % 256 = 44; лишние биты просто отсекаются
|
|
Усечение
В языке С любая дробная часть, полученная при делении двух целых чисел, отбрасывается.
В стандарте С99 определено усечение в направлении нуля -3.8=-3 и 3.8=3 и 3.1=3
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int x = 5;
int y = 3;
int result = x/y; // OK, Усечение не относится к автоматическому преобразованию с потерей, хотя именно это и происходит
printf("%d\n", x/y);// 1
printf("%f\n", x/y);// 0.000000
printf("%f\n", (float)(x/y));// 1.000000
printf("%f\n", (float)(x)/(float)y);// 1.666667
{
float f = (float)(x/y);
printf("%f\n", f);// 1.000000
}
{
float f = (float)x/(float)y;
printf("%f\n", f);// 1.666667
}
return EXIT_SUCCESS;
}
|
|
Типы данных NAN и INFINITY
Стандарт IEEE 754
Эти константы (или их эквиваленты, такие как макросы) используются для представления математически некорректных или выходящих за пределы диапазона результатов.
NAN (или nanf для float) расшифровывается как "Не Число"
Любая арифметическая операция, включающая NAN, всегда приводит к NAN. Кроме того, NAN не равно самому себе (NAN != NAN)
INFINITY (или inf для double, inff для float) представляет математическую бесконечность.
INF не равно максимальному числу, которое может хранить тип; это особое значение, которое находится за пределами этого диапазона.
В большинстве embedded-прошивок NaN, INFINITY, isnan(), isinf() и math.h НЕ используют, и вот почему — не потому что нельзя, а потому что они бесполезны, опасны и дорогие.
|
#include <stdio.h>
#include <math.h> // Для NAN, INFINITY, isnan, isinf, isfinite
#include <stdlib.h> // EXIT_SUCCESS
int main() {
float arg1 = NAN;
double arg2 = INFINITY;
// Проверка NaN
if (isnan(arg1)) {
printf("arg1 - это NaN\n");
}
// Проверка Infinity
if (isinf(arg2)) {
printf("arg2 - это Бесконечность\n");
}
printf("isfinite(1.0): %d\n", isfinite(1.0)); // 1
// Пример генерации NaN
double result_nan = 0.0 / 0.0; // или так = NAN
// Пример генерации Infinity
double result_inf = 1.0 / 0.0; // или так = INFINITY
printf("0.0 / 0.0 = %f\n", result_nan);
printf("1.0 / 0.0 = %lf\n", result_inf);
return EXIT_SUCCESS;
}
|
|
|
|
|
|
Проверка типа символа (ctype.h)
Все функции принимают int c (код символа) и возвращают ненулевое значение (истина), если условие выполняется, или 0 (ложь) — если нет.
int isalnum(int c); - Проверяет, является ли символ алфавитно-цифровым (буквой или цифрой). Эквивалентна (isalpha(c) || isdigit(c)).int isalpha(int c); - Проверяет, является ли символ буквенным. В локали "C" это символы от a до z и от A до Z.int isblank(int c); - Проверяет, является ли символ пробельным символом пустого пространства. В стандартной локали это пробел (' ') и символ горизонтальной табуляции ('\t').int iscntrl(int c); - Проверяет, является ли символ управляющим. Управляющие символы — это символы, которые не выводятся на печать (например, с кодами ASCII от 0 до 31 и 127 (DEL)).int isdigit(int c); - Проверяет, является ли символ цифрой. В локали "C" это символы от 0 до 9.int isgraph(int c); - Проверяет, является ли символ печатаемым (графическим), но не пробелом. Эквивалентна (isprint(c) && c != ' ').int islower(int c); - Проверяет, является ли символ буквой в нижнем регистре. В локали "C" это символы от a до z.int isprint(int c); - Проверяет, является ли символ печатаемым, включая пробел. Печатаемые символы занимают место при выводе на экран.int ispunct(int c); - Проверяет, является ли символ символом пунктуации. Это любой печатаемый символ, который не является пробелом, буквой или цифрой (например, !, . , ,, @, %).int isspace(int c); - Проверяет, является ли символ пробельным. В локали "C" это пробел (' '), перевод страницы ('\f'), новая строка ('\n'), возврат каретки ('\r'), горизонтальная ('\t') и вертикальная ('\v') табуляции.int isupper(int c); - Проверяет, является ли символ буквой в верхнем регистре. В локали "C" это символы от A до Z.int isxdigit(int c); - Проверяет, является ли символ шестнадцатеричной цифрой. В локали "C" это цифры 0-9 и буквы a-f, A-F.
Преобразование символа (ctype.h)
-
int tolower(int c); - Преобразует символ в нижний регистр. Если символ является буквой в верхнем регистре, возвращает соответствующую букву в нижнем регистре. В противном случае возвращает переданный символ без изменений.
-
int toupper(int c); - Преобразует символ в верхний регистр. Если символ является буквой в нижнем регистре, возвращает соответствующую букву в верхнем регистре. В противном случае возвращает переданный символ без изменений.
|
|
Стандартная библиотека ввода-вывода С содержит по меньшей мере четыре разные функции для записи одного символа char с; в поток вывода:
- putc(с, fp) ;
- fputc (с, fp) ;
- fprintf(fp, "%c", с);
- fwrite(&c, sizeof(char), 1, fp) ;
Если поток вывода представляет собой stdout, то есть еще несколько возможностей.
|
|
|
getchar() и putchar() — для работы с отдельными символами
|
getchar() — чтение одного символа из stdin
Возвращает int (не char!) чтобы поместить EOF (-1)
Ждет ввода (буферизованный ввод)
int c = getchar(); // Читает один символ
putchar(c) — вывод одного символа в stdout
putchar('A'); // Выводит символ 'A'
putchar(65); // Выводит 'A' (ASCII 65)
putchar(c); // Выводит символ из переменной
|
|
|
Странно тип char может в зависимости от компилятора быть unsigned 0-255 или signed т.е. -128-127
В этом случае возникают неприятные последствия, если символ должен использоваться в качестве индекса массива или сравниваться с кодом EOF, который обычно определен как -1 в файле stdio. h.
В языках С и C++ не определено, должен ли тип char быть знаковым или беззнаковым. От этого могут возникнуть проблемы — в частности, при сочетании типов char и int, как это происходит при вызове функции getchar () с целым возвращаемым значением.
char с; /* должен иметь тип int */
с = getchar();
В результате значение будет находиться в диапазоне от 0 до 255, если тип char не имеет знака, и от -128 до 127 в противном случае.
Поэтому следует явно использовать тип unsigned char или signed char
#include <stdio.h>
#include <limits.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
if ((char)-1 < 0)
printf("char = signed\n");
else
printf("char = unsigned\n");
printf("CHAR_MIN=%d CHAR_MAX=%d\n", CHAR_MIN, CHAR_MAX);
// а тут переполнение типа случилось
char a = 255;
printf("%d", a); // -1
// но если явно задать тип без знака, то нет переполнения
unsigned char b = 255;
printf("%d", b); // 255
return EXIT_SUCCESS;
}
Мой компилятор имеет char по умолчанию signed:
char = signed
CHAR_MIN=-128 CHAR_MAX=127
|
|
Тип char
C изначально был ASCII-языком
char — это наименьшая адресуемая единица памяти.
Т.е. char* — это указатель на байты.
char полезен в:
- работе с байтами (основная причина), сетевые пакеты, бинарные файлы, буферы, драйверы.
- ASCII - клавиши, протоколы, простые старые тексты.
|
Размер = 1 байт, в байт помещается один код символа, но char — это не обязательно символьный тип. Это маленький целый тип.
Три формы char
| Тип | Подпись? | Для чего используется |
|---|
char | зависит от компилятора: signed или unsigned | символы и байты |
signed char | всегда со знаком | маленькое целое |
unsigned char | всегда без знака | работа с raw-данными, буферы |
char может быть signed или unsigned, и это зависит от платформы:
- На x86 обычно signed char
- На ARM/embedded часто unsigned char
В переменную записывается символьная константа 'A' имеющая обычно код ASCII (65) в Linux, Windows, embedded ARM
char c = 'A';
Обратите внимание, что в примере предполагается использование в системе кодировки ASCII. Указание 'А' вместо 65 дает в результате код, который работает в любой системе. Таким образом, применять символьные константы намного лучше, чем значения числовых кодов.
Форматы для printf (char)
| Тип | Формат | Пример | Комментарий |
|---|
char (как число) | %hhd | printf("%hhd", c); | вывод ASCII-кода |
unsigned char (как число) | %hhu | printf("%hhu", uc); | вывод 0..255 |
char (символ) | %c | printf("%c", c); | вывод символа |
строка (char *) | %s | printf("%s", str); | вывод C-строки |
Форматы для scanf (char)
| Тип | Формат | Пример |
|---|
char | %c | scanf("%c", &c); |
signed char | %hhd | scanf("%hhd", &sc); |
unsigned char | %hhu | scanf("%hhu", &uc); |
Для положительных данных есть смысл использовать unsigned char (без знака), поскольку стандарт С или C++ не гарантирует наличие или отсутствие знака у символьных переменных char.
|
|
|
char может хранить:
- символ ASCII (0..127),
- или один байт из UTF-8-последовательности. Но НЕ сам Unicode-символ.
Как хранить Unicode в C
В UTF-8 в char* (строки в Linux). Каждый байт — unsigned char
char *s = "Привет"; // UTF-8 строка, Linux ok
Пример:
#include <stdio.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char *s = "Привет"; // UTF-8, каждый символ = 2–4 байта
for (size_t i = 0; i < strlen(s); i++) {
printf("%02X ", (unsigned char)s[i]); // выводим байт за байтом
}
printf("\n");
return EXIT_SUCCESS;
}
|
|
Флаги форматирования для строк
% [Флаги] [Ширина] [.Точность] [Тип]
24 минимальная ширина поля
.5 нужно вывести только пять символов
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define BLURB "Authentic imitation !"
int main(void) {
printf("[%2s]\n", BLURB); //[Authentic imitation !]
printf("[%24s]\n", BLURB); //[ Authentic imitation !]
printf("[%24.5s]\n", BLURB); //[ Authe]
printf("[%-24.5s]\n", BLURB);//[Authe ]
return EXIT_SUCCESS;
}
|
|
|
|
|
|
Символьная строка — это массив элементов типа char с завершающим нулевым символом ASCII 0 (\0) конца строки
Присутствие нулевого символа означает, что массив должен иметь, по крайней мере, на одну ячейку больше, чем количество символов, которые требуется сохранить.
Не делайте ничего за спиной пользователя. Библиотечная функция не должна записывать секретных файлов или переменных, а также изменять глобальные данные.
А вот функция strtok нарушает сразу несколько из этих требований. Неприятно удивляет тот факт, что она записывает нулевые байты в середину строки ее исходных данных. То, что функция использует нулевой байт для обозначения места окончания предыдущей операции, подразумевает хранение неких секретных данных между ее вызовами, а это потенциальный источник ошибок и препятствие к параллельной работе нескольких экземпляров функции.
|
|
|
Символьные строковые константы размещаются в статическом классе хранения, т.е. если вы используете строковую константу в функции, то эта строка сохраняется только однажды и существует на протяжении времени выполнения программы, даже если функция вызывается много раз.
Вся фраза, заключенная в кавычки, действует в качестве указателя на место, где хранится строка.
Это аналогично имени массива, которое трактуется как указатель на место смещения массива.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
printf("%s, %p, %c\n", "Мы", " - ", *"космические бродяги"); // Проблема в кодировке: %c работает с одним байтом, а русские буквы в UTF-8 занимают 2 байта, поэтому выводится только половина символа (мусор)
printf("%s, %p, %c\n", "We", " - ", *"are space wanderers" , *((char*)("are space wanderers")+1)); // We, 0x62257953c00a, a, r
// 0x62257953c00a является адресом первого симола строки " - " т.е. пробела
// символ 'a' это первый элемент указателя этой строки *"are space wanderers"
char *ptr = " - ";
printf("%p, %p, %p\n", ptr, ptr+1, ptr+2);// 0x62257953c00a, 0x62257953c00b, 0x62257953c00c
return EXIT_SUCCESS;
}
|
|
Все функции из библиотеки string.h
|
- memset(void *s, int c, size_t n) — заполняет n байт области памяти значением c.
- memcpy(void *dest, const void *src, size_t n) — копирует n байт из src в dest (области не должны пересекаться).
- memmove(void *dest, const void *src, size_t n) — копирует n байт, корректно работает при перекрытии областей.
- memcmp(const void *s1, const void *s2, size_t n) — сравнение первых n байт двух областей памяти.
- memchr(const void *s, int c, size_t n) — ищет первый байт c в первых n байтах области памяти s.
- strlen(const char *s) — возвращает длину строки до символа '\0'.
- strcpy(char *dest, const char *src) — копирует строку src в dest (опасно, без проверки размера).
- strncpy(char *dest, const char *src, size_t n) — копирует максимум n символов, может не поставить '\0'.
- strcat(char *dest, const char *src) — дописывает строку src в конец dest (опасно, нет проверки размера).
- strncat(char *dest, const char *src, size_t n) — дописывает не более n символов.
- strcmp(const char *s1, const char *s2) — лексикографическое сравнение двух строк.
- strncmp(const char *s1, const char *s2, size_t n) — сравнивает первые n символов строк.
- strchr(const char *s, int c) — ищет первый символ c в строке.
- strrchr(const char *s, int c) — ищет последний символ c в строке.
- strstr(const char *haystack, const char *needle) — ищет подстроку needle в haystack.
- strpbrk(const char *s, const char *accept) — ищет первый символ из набора accept.
- strspn(const char *s, const char *accept) — количество начальных символов из accept.
- strcspn(const char *s, const char *reject) — количество начальных символов, НЕ входящих в reject.
- strtok(char *s, const char *delim) — разбивает строку на токены, используя глобальное состояние (опасно).
- strerror(int errnum) — возвращает строку-описание ошибки по номеру.
|
|
Все функции из библиотеки stdlib.h
|
- malloc(size_t size) — выделяет блок памяти размером size байт, возвращает указатель на него или NULL.
- calloc(size_t nmemb, size_t size) — выделяет память для массива из nmemb элементов по size байт и обнуляет её.
- realloc(void *ptr, size_t size) — изменяет размер ранее выделенного блока памяти ptr на size байт.
- free(void *ptr) — освобождает ранее выделенный блок памяти.
- abort(void) — немедленно завершает программу.
- atexit(void (*func)(void)) — регистрирует функцию func, которая будет вызвана при нормальном завершении программы.
- exit(int status) — завершает программу, вызывает функции, зарегистрированные через atexit, и flush стандартных потоков.
- getenv(const char *name) — возвращает значение переменной окружения name или NULL.
- system(const char *command) — выполняет команду shell.
- abs(int n) — возвращает абсолютное значение n.
- labs(long n) — возвращает абсолютное значение long.
- llabs(long long n) — возвращает абсолютное значение long long.
- div(int numer, int denom) — возвращает структуру {quot, rem} с результатом деления и остатком.
- ldiv(long numer, long denom) — то же для long.
- lldiv(long long numer, long long denom) — то же для long long.
- rand(void) — возвращает псевдослучайное число.
- srand(unsigned int seed) — устанавливает начальное значение для rand().
- strtol(const char *nptr, char **endptr, int base) — преобразует строку в long.
- strtoul(const char *nptr, char **endptr, int base) — преобразует строку в unsigned long.
- strtoll(const char *nptr, char **endptr, int base) — преобразует строку в long long.
- strtoull(const char *nptr, char **endptr, int base) — преобразует строку в unsigned long long.
- atof(const char *nptr) — преобразует строку в double.
- atoi(const char *nptr) — преобразует строку в int.
- atol(const char *nptr) — преобразует строку в long.
- atoll(const char *nptr) — преобразует строку в long long.
- mblen(const char *s, size_t n) — возвращает количество байт в многобайтовом символе.
- mbtowc(wchar_t *pwc, const char *s, size_t n) — конвертирует многобайтовую последовательность в wchar_t.
- wctomb(char *s, wchar_t wc) — конвертирует wchar_t в многобайтовую последовательность.
- mbstowcs(wchar_t *pwcs, const char *s, size_t n) — конвертирует строку из многобайтовых символов в массив wchar_t.
- wcstombs(char *s, const wchar_t *pwcs, size_t n) — конвертирует массив wchar_t в строку многобайтовых символов.
|
|
Спецификатор %s в scanf("%s",name); считывает последовательность символов, не являющихся пробелами.
К тому же, если не ограничивать размер ввода, то scanf может записать в чужую память, что создает неопределённое поведение (UB)
Рабочий вариант формата: scanf("%99[^\n]",name);
Рабочий вариант fgets
|
Например, если вводить в scanf("%s",name); предложение разделенное пробелом либо табуляцией то все что идет после не попадет в переменную. И scanf считывает только нужные ему символы, но оставляет символ новой строки (\n) в буфере ввода, поэтому следующий вызов scanf не будет работать так как буфер обмена уже содержит символ новой строки (\n), к тому же если предыдущий ввод содержал пробел то весь текст после пробела перейдет на обработку к следующему scanf.
Если вначале строки есть пробелы, то они будут пропущены и взято первое слово.
Это не рабочий вариант считывания scanf, весь ввод после пробела останется в буфере обмена и мешая следующему scanf
А getchar() только последний символ удаляет из буфера, а не оставшуюся строку
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <stddef.h> // NULL
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME]={};
printf("Полное имя:");
scanf("%s",name);
printf("%s\n", name);// Мария
getchar(); // Считывает и отбрасывает оставшийся '\n' с буфера
return EXIT_SUCCESS;
}
Рабочий вариант считывания всего ввода c ограничением длины и освобождением буфера от переноса строки
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME]={};
char fmt[20];
sprintf(fmt, "%%%d[^\n]", LENGTH_NAME - 1);// Формируем формат строки: "%39[^\n]"
printf("Полное имя:");
scanf(fmt, name); // Считывает до 39 символов, пока не встретит '\n'
printf("%s\n", name);
getchar(); // Считывает и отбрасывает оставшийся '\n' с буфера
return EXIT_SUCCESS;
}
Еще лучше вариант считывания всего ввода c ограничением длины, fgets сам очистит буфер
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <string.h> // для strlen
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME];
printf("Полное имя: ");
// Считывает строку, включая пробелы и '\n', безопасно.
if (fgets(name, LENGTH_NAME, stdin) != NULL) {
// Удаляем '\n', который был добавлен функцией fgets
size_t len = strlen(name);
if (len > 0 && name[len - 1] == '\n') {
name[len - 1] = '\0';
}
printf("%s\n", name);
}
// Буфер ввода stdin уже чист!
return EXIT_SUCCESS;
}
|
|
Для вывода строк в С доступны три стандартных библиотечных функции:
puts(), fputs() и printf()
|
puts(str) — для простого вывода строки + автоматический \n
Принимает адрес строки.
puts("Hello"); // Автоматически добавляет \n
puts(&str[5]);
fputs(str, stream) — для вывода БЕЗ автоматического \n
В роли stream может быть файл или stdout:
Когда использовать:
- Вывод в файлы
- Построчное чтение/запись без лишних \n
- Вывод нескольких строк в одну
fputs("Hello ", stdout); // ✅ НЕ добавляет \n
fputs("World", stdout); // Вывод: Hello World (без \n)
fputs("\n", stdout); // Явный перевод строки
FILE *file = fopen("text.txt", "w");
fputs("Line 1", file); // Записывает без \n
fputs(" continues", file); // Продолжение той же строки
printf(format, ...) — для форматированного вывода
printf("Name: %s, Age: %d\n", "John", 25); // Форматирование
printf("Price: $%.2f\n", 19.99); // Числа, даты, и т.д.
|
|
strlen — это функция стандартной библиотеки C в string.h, которая считает длину C-строки, то есть количество символов до первого нулевого байта '\0' т.е. нулевой байт она не подсчитывает
|
#include <stdio.h>
#include <string.h> // для strlen
#include <stdlib.h> // EXIT_SUCCESS
#define LENGTH_NAME 9 // должны учесть длину ввода + 1 байт для конца строки \0
#define MY_TEXT "Женя" // компилятор сам добавит \0, компилятор превращает это в массив из 9 байт
int main(void) {
char name[LENGTH_NAME]={};
int letters = 0;
printf("Имя:"); // имя можем ввести максимум 8 символов по байту ASCII или 4 символа двойной кодировки например кириллицы
char fmt[20];
sprintf(fmt, "%%%d[^\n]", LENGTH_NAME - 1);// Формируем формат строки: "%8[^\n]"
scanf(fmt, name); // компилятор сам добавит \0
getchar(); // Считывает и отбрасывает оставшийся '\n' с буфера
letters = strlen(name);
printf("letters=%d\n", letters);
printf("MY_TEXT length=%d\n", strlen(MY_TEXT));// 8
return EXIT_SUCCESS;
}
|
|
Создание строк
способ 1 (статический массив)
Размещение: на стеке (если локальная) или в DATA (если глобальная). Можно менять.
Фундаментальное различие между "владеть копией" и "ссылаться на общий оригинал":
Недостаток строк-массивов, инициализация массива приводит к копированию строки из статической памяти в массив, тогда как инициализация указателя просто копирует адрес строки.
Т.е. при запуске функции строка-массив будет копироваться из RODATA в STACK, в результате чего каждая строка сохраняется дважды.
|
#include <stdio.h>
#include <string.h> // для strlen
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// массив char[6], можно менять в пределах выделенной памяти
char s[] = "Hello"; // компилятор сам добавит в конец строки \0
s[0] = 'h';
printf("%zu байт\n",sizeof(s));// 6 - учитывает \0 в конце
printf("%zu байт\n",strlen(s));// 5 - не учитывает \0
// вывод строки
printf("%s", s);
// посимвольный вывод
for(size_t i=0; i<strlen(s); i++){
printf("%c", s[i]);
}
return EXIT_SUCCESS;
}
|
|
Создание строк
способ 2 (статический массив)
Можно менять.
Фундаментальное различие между "владеть копией" и "ссылаться на общий оригинал":
Недостаток строк-массивов, инициализация массива приводит к копированию строки из статической памяти в массив, тогда как инициализация указателя просто копирует адрес строки.
Т.е. при запуске функции строка-массив будет копироваться из RODATA в STACK, в результате чего каждая строка сохраняется дважды.
|
#include <stdio.h>
#include <string.h> // для strlen
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// это просто массив символов, а не C-строка. Попытка использовать его с функциями, ожидающими конец строки \0
// например printf или strlen может привести к Undefined Behavior (UB)
//char s[] = {'H', 'e', 'l', 'l', 'o'}; // компилятор ничего не добавит, надо самому позаботится о конеце строки \0
// Вот правильный вариант
char s[] = {'H', 'e', 'l', 'l', 'o', '\0'};
s[0] = 'w';
printf("%zu байт\n",strlen(s));// 5 - не учитывает \0
printf("%s", s);
for(size_t i=0; i<strlen(s); i++){
printf("%c", s[i]);
}
return EXIT_SUCCESS;
}
|
|
Создание строк
способ 3 (статический массив)
Можно менять.
Фундаментальное различие между "владеть копией" и "ссылаться на общий оригинал":
Недостаток строк-массивов, инициализация массива приводит к копированию строки из статической памяти в массив, тогда как инициализация указателя просто копирует адрес строки.
Т.е. при запуске функции строка-массив будет копироваться из RODATA в STACK, в результате чего каждая строка сохраняется дважды.
|
#include <stdio.h>
#include <string.h> // для strlen
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char s[10] = {}; // массив инициализируется нулями так что добавлять \0 ненужно
s[0] = 'H';
s[1] = 'e';
s[2] = 'l';
s[3] = 'l';
s[4] = 'o';
printf("%zu байт\n",sizeof(s));// 10 - учитывает \0 в конце и все нули после инициализации
printf("%zu байт\n",strlen(s));// 5 - не учитывает \0 т.е. фактическая строка занятая символами, а не нулями
s[2] = '\0';
printf("%zu байт\n",strlen(s));// 2 - осталось 2 символа, а после мы оборвали концом строки \0
return EXIT_SUCCESS;
}
|
|
Создание строк
способ 4 (неизменяемые строки)
Размещение в сегменте RODATA (read-only data)
Нельзя изменять (так как это общие строки для всех и имеет один адрес, компилятор подставляет во все места ее использования один адрес)
// Почему лучше: безопасность + ясность намерений
const char *message = "Hello World";
const char *errors[] = {"Error1", "Error2"};
const char *paths = "/usr/bin/program";
|
#include <stdio.h>
#include <string.h> // для strlen
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
//read-only неизменяемая строка, s указывает на литерал в памяти
char *s = "Hello"; // компилятор сам добавит в конец строки \0
s[0] = 'X'; // Error в Runtime (Segmentation fault)
const char *s2 = "Hello";
s2[0] = 'X'; // Error в момент компиляции (Segmentation fault)
puts(s2);// Hello
size_t size = strlen(s2);// заранее вычислим так как операция `s2++` меняет вычисляемую длину строки функцией strlen
for(size_t i = 0; i < size; i++) {
printf("%c", s2[i]); // Доступ по индексу
}
for(size_t i =0; i < size; i++){
printf("%c", *s2);// Hello
s2++;
}
printf("%s", s2);// --- пусто так как подвинули указатель в конец строки, надо сохранять начало `char *original = s2;` для дальнейшего использования
printf("%zu байт\n",sizeof(s));// 8 - это не размер строки, а размер указателя на 64-битной системе где адрес памяти занимает 64 бита, или 8 байт
printf("%zu байт\n",strlen(s));// 5
return EXIT_SUCCESS;
}
|
|
Создание строк
способ 5 (динамическая память)
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <string.h>
int main(void) {
// 1. Создаём строку начального размера
size_t size = 16; // начальный размер
char *str = malloc(size); // выделяем память
if (!str) {
perror("malloc");
return 1;
}
str[0] = '\0'; // делаем строку пустой
// 2. Записываем что-то внутри
strcpy(str, "Hello");
printf("str = %s\n", str);
// 3. Проверяем — хотим добавить ещё текст, но места мало —
// делаем расширение через realloc
const char *addition = ", world!";
// считаем требуемую длину: текущая длина + длина добавки + '\0'
size_t needed = strlen(str) + strlen(addition) + 1;
if (needed > size) {
// увеличиваем буфер
char *tmp = realloc(str, needed);
if (!tmp) {
perror("realloc");
free(str);
return 1;
}
str = tmp;
size = needed;
}
// 4. Добавляем новый текст
strcat(str, addition);
printf("expanded str = %s\n", str);
// 5. Освобождаем память
free(str);
return EXIT_SUCCESS;
}
|
|
|
#define SLEN 60
#define LIM 5
int main(void){
// Массивы символьных строк
const char *mytalents[LIM] = {
"Мгновенное складывание чисел",
"Точное умножение",
"Накапливание данных",
"Исполнение инструкций с точностью до буквы",
"Знание языка программирования С"
};
// создает двумерный массив символов, а не массив строк
char yourtalents[LIM][SLEN] = {
"Хождение по прямой",
"Здоровый сон",
"Просмотр телепередач",
"Рассылка писем",
"Чтение электронной почты"
};
int i;
for (i = 0; i < LIM; i++){
printf("%-52s %-25s\n", mytalents [i], yourtalents [i]);
}
printf("\npaзмep mytalents: %zd, размер yourtalents: %zd\n",sizeof(mytalents), sizeof(yourtalents));
return 0;
}
|
|
Использование wchar_t и широких строк wchar_t*
тип wchar_t определен в нескольких заголовочных файлах ( stddef.h, stdlib.h, wchar.h, wctype.h)
|
Стандартные функции strlen и printf не знают о многобайтовых символах, используйте wcslen и wprintf
Функции wprintf, wcslen, wcscpy работают с wchar_t
#include <wchar.h>
#include <locale.h>
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main() {
setlocale(LC_ALL, ""); // Настройка локали для корректного вывода
wchar_t s[] = L"Привет, 🌍!";
wprintf(L"%ls\n", s);
wprintf(L"Длина: %zu\n", wcslen(s));
return EXIT_SUCCESS;
}
|
|
Библиотека locale.h — это механизм смены культурных настроек программы: язык, формат чисел, формат дат, сортировка строк, денежные символы и т.д.
setlocale(category, "локаль");
Во многих проектах локали запрещены.
Потому что локали — это глобальное состояние, которое меняет всю программу.
Это делает поведение непредсказуемым, зависимым от окружения, нечистым (не thread-safe)
|
Он позволяет переключать локаль — набор правил для:
- отображения чисел (1,234.56 vs 1.234,56)
- отображения дат
- алфавитного порядка для strcoll
- классификации символов (isdigit, isalpha, toupper, tolower)
- денежных символов (€, $)
- имён месяцев, дней недели (в POSIX)
- широких символов (
<wchar.h> зависит от локали)
| Категория | Что управляет |
|---|
LC_ALL | всё |
LC_NUMERIC | формат чисел |
LC_TIME | названия месяцев/дней, формат дат |
LC_MONETARY | вывод валют |
LC_COLLATE | сортировка строк |
LC_CTYPE | классификация символов (toupper, tolower, isdigit) |
LC_MESSAGES | язык сообщений программ |
Пример
#include <stdio.h>
#include <locale.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// переключение на русскую локаль
setlocale(LC_ALL, "ru_RU.UTF-8");
printf("%'.2f\n", 1234567.89); // 1 234 567,89
// сортировка строк по правилам языка
setlocale(LC_COLLATE, "ru_RU.UTF-8");
printf("%d\n", strcoll("Ёж", "Яблоко"));
// классификация символов
// Без локали:
setlocale(LC_CTYPE, "C"); // дефолт
printf("%d\n", isalpha('ё')); // 0 — не буква
// С русской локалью:
setlocale(LC_CTYPE, "ru_RU.UTF-8");
printf("%d\n", isalpha('ё')); // 1 — буква
// валюты
setlocale(LC_MONETARY, "ru_RU.UTF-8");
struct lconv *lc = localeconv();
printf("Currency symbol: %s\n", lc->currency_symbol); // ₽
return EXIT_SUCCESS;
}
|
|
Преобразование строк в байты (аналог C-функций)
Поскольку для согласованной передачи из одной системы в другую символы приходится конвертировать в байтовые потоки (например, UTF-8), в языке С есть функции для преобразования расширенных символов в байт-коды и наоборот.
|
wchar_t в мультибайтовую строку
#include <wchar.h>
#include <locale.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
setlocale(LC_ALL, "en_US.UTF-8");
wchar_t wide_str[] = L"Привет, мир!";
char mb_str[100];
// wchar_t → multibyte
wcstombs(mb_str, wide_str, sizeof(mb_str));
printf("Multibyte: %s\n", mb_str);
return EXIT_SUCCESS;
}
Мультибайтовой строки в wchar_t
#include <wchar.h>
#include <locale.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
setlocale(LC_ALL, "en_US.UTF-8");
char mb_str[] = "Привет, мир!";
wchar_t wide_str[100];
// multibyte → wchar_t
mbstowcs(wide_str, mb_str, sizeof(wide_str) / sizeof(wchar_t));
wprintf(L"Wide: %ls\n", wide_str);
return EXIT_SUCCESS;
}
С обработкой ошибок
#include <wchar.h>
#include <locale.h>
#include <errno.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
setlocale(LC_ALL, "en_US.UTF-8");
wchar_t wide_str[] = L"Hello 世界";
char mb_str[100];
size_t result;
errno = 0;
result = wcstombs(mb_str, wide_str, sizeof(mb_str));
if (result == (size_t)-1) {
perror("wcstombs failed");
return 1;
}
printf("Converted: %s (%zu bytes)\n", mb_str, result);
return EXIT_SUCCESS;
}
|
|
strtod Преобразование строки в число типа double
|
int main(void){
// Преобразование строки в число типа double
//double strtod (const char *str, char **endstr);
// Преобразуемая строка
char* str = "+123.45e6";
// Указатель, на непреобразованный остаток строки str,
// в начале указывает на начало строки str
char* nstr = str;
// Переменная для сохранения результата преобразования
double d = 0;
d = strtod(str,&nstr);
printf ("%f\n",d);// 123450000.000000
return 0;
}
|
|
В C есть несколько способов преобразования строк в числа
|
atoi() — строка → int
#include <stdlib.h>
int num = atoi("123"); // 123
int negative = atoi("-456"); // -456
int invalid = atoi("12abc"); // 12 (игнорирует хвост)
strtol() — строка → long (рекомендуемый)
#include <stdlib.h>
char *endptr;
long num = strtol("123", &endptr, 10); // 123
// Проверка ошибок:
char str[] = "123abc";
long val = strtol(str, &endptr, 10);
if (*endptr != '\0') {
printf("Нечисловые символы: %s\n", endptr); // "abc"
}
sscanf() — форматированное чтение из строки
int num, count;
char str[] = "123 456";
count = sscanf(str, "%d", &num); // num = 123, count = 1
count = sscanf("abc", "%d", &num); // count = 0 (ошибка)
Для разных типов:
#include <stdlib.h>
int i = atoi("123"); // int
long l = atol("123456"); // long
long long ll = atoll("123"); // long long
double d = atof("3.14"); // double
// Или с проверкой ошибок:
long l = strtol("123", NULL, 10);
double d = strtod("3.14", NULL);
|
|
Преобразование числа в строку
snprintf форматирует данные точно так же, как printf, но записывает их не в поток stdout, а напрямую в массив char[], который вы ей передаете.
|
Вы можете использовать sprintf, чтобы сделать это, или, может быть, snprintf, если он у вас есть:
char str[ENOUGH];
sprintf(str, "%d", 42);
Где количество символов (плюс завершающий символ) в str может быть вычислено с помощью:
(int)((ceil(log10(num))+1)*sizeof(char))
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define MAX_LEN 256
int main(void){
char my_string[MAX_LEN]; // Ваш буфер для результата
i nt answer = 42;
// snprintf записывает результат в my_string
snprintf(my_string, MAX_LEN, "Ответ: %d. Результат: %d", answer, 100);
// my_string теперь содержит строку "Ответ: 42. Результат: 100"
printf("Сформированная строка: %s\n", my_string);
return EXIT_SUCCESS;
}
|
|
Строки методы all-ht.ru/inf/prog/c/func/strchr
длина строки size_t *strlen (const char *str);
копирование строки массива: char *strcpy (char * restrict destination, const char * restrict source);
- strncpy – копирование строк c ограничением длины
дублирование строк с выделением памяти под новую строку: char *strdup(const char *str);
- strndup – дублирование строк с ограничением длины и выделением памяти под новую строку
объединение строк: char *strcat (char *destination, const char *append);
- strncat – объединение строк c ограничением длины добавляемой строки.
поиск первого вхождения строки А в строку В без учета регистра символов: char *strcasestr (const char *strB, const char *strA);
- strpbrk – поиск первого вхождения в строку символа из указанного множества
- strstr – поиск первого вхождения строки А в строку В
поиск первого вхождения символа в строку: char *strchr (const char *str, int ch);
- strrchr – поиск последнего вхождения символа в строку.
сравнение строк (сравнение строк через отношение == не работает!): int strcmp (const char *str1, const char *str2);
- strncmp – сравнение строк с ограничением количества сравниваемых символов
формирование сообщения об ошибке по коду ошибки.: char *strerror (int errcode);
разбиение строки на части по указанному разделителю: char *strtok(char *str, const char *sep);
Печатает строку + автоматически добавляет \n: int puts(const char *str);
|
#include <stdio.h>
#include <locale.h> // для русского языка
#include <string.h> // для функций strcpy( ), strcat( ), strlen( ) и strcmp( )
#include <unistd.h> // для sleep
#include <stdlib.h> // EXIT_SUCCESS
#include <stddef.h> // NULL
// обьявление функций которе будут использоваться из string.h
char *strcasestr (const char *strB, const char *strA);
int main(void){
setlocale(LC_ALL, "Rus"); // для русского языка
// определение длины строки
// size_t *strlen (const char *str);
char *str_point="Строка";
printf("Длина строки=%ld", strlen(str_point));// 12
// копирование строки массива
// char *strcpy (char * restrict destination, const char * restrict source);// указатель destination должен быть предварительно инициализирован!
// restrict указывает на недопустимость копирования строки в саму себя
//char from_str[] = {'t', 'h', 'r', 'e', 'e', '\0'};
const char* from_str = "three";
char to_buff[10];
strcpy(to_buff,from_str);
strncpy(to_buff,from_str, 6); // т.е. +1 байт для нулевого символа
to_buff[0]= 'T';
printf("%s\n",to_buff);// Three
// дублирование строк с выделением памяти под новую строку
// char *strdup(const char *str);
char *to_buff2;
to_buff2 = strdup(from_str);
printf("%s\n",to_buff2);// three
// объединение строк
// char *strcat (char *destination, const char *append);
char to_str2[10] = {'a','b'};// или = "ab"
char from_str2[10] = {'c','d'};// или = "cd"
strcat(to_str2, from_str2); // увеличивает первую строку, добавляя ей в конец начало второй строки
printf("%s\n",to_str2);// abcd
void test(char *argv[]){
char buff[50]={};
strcat(buff,argv);
strcat(buff," world");
printf("%s\n",buff); // hello world
}
char *c="hello";
test(c);
// поиск первого вхождения строки А в строку В без учета регистра символов
// char *strcasestr (const char *strB, const char *strA);
char str_source[50] = "hello woRLD";
char str_search[10]="rld";
char *str_point2 = strcasestr(str_source,str_search);
printf("%s",str_point2);// RLD
// поиск первого вхождения символа в строку
// char *strchr (const char *str, int ch);
char str_source2[50] = "hello woRLD";
char s_search='R';
char *str_point3 = strchr(str_source2,s_search);
if (str_point3!=NULL)
printf("%s",str_point3);// RLD
// сравнение строк
// int strcmp (const char *str1, const char *str2);
char str_source3[50] = "hello woRLD";
char str_source4[50] = "hello woRLD";
if (strcmp (str_source3, str_source4)==0)
puts ("Строки идентичны");
else
puts ("Строки отличаются");
// формирование сообщения об ошибке по коду ошибки.
// char *strerror (int errcode);
printf (“Ошибка 99: %s\n“, strerror (99) );// Ошибка 99: Cannot assign requested address
// разбиение строки на части по указанному разделителю
char str [24]= "test1/test2/test3/test4";
// Набор символов, которые должны входить в искомый сегмент
char sep [10]="/";
// Переменная, в которую будут заноситься начальные адреса частей
// строки str
char *istr;
istr = strtok (str,sep);
// Выделение последующих частей
while (istr != NULL)
{
// Вывод очередной выделенной части
printf ("%s\n",istr);
// Выделение очередной части строки
istr = strtok (NULL,sep);
}
return EXIT_SUCCESS;
}
|
|
В многопоточной программе функция strtok — это настоящее стихийное бедствие, как и все функции из библиотеки С, которые хранят данные во внутренних статических переменных. Если уж так необходимо отдавать переменные в общее пользование, то их необходимо снабдить каким-то механизмом захвата и блокирования, чтобы гарантировать единовременное обращение со стороны только одного потока.
|
|
|
Это классический пример уязвимости переполнения буфера (Buffer Overflow), которая возникает из-за использования небезопасных строковых функций в C.
Ошибка происходит, когда программист рассчитывает, что буфер размером N может безопасно вместить N символов, забывая, что в строках C обязательно требуется дополнительный нулевой байт (\0) для обозначения конца строки.
т.е. надо всегда держать в уме +1 на нулевой байт
|
// Предположим, 'input' содержит 1024 символа данных (не считая \0)
// Длина input_data (strlen(input)) == 1024
// 🛑 Опасная операция: strcpy не проверяет границы буфера!
// Она копирует 1024 символа данных и нулевой байт (\0).
strcpy(buffer, input);
Символы данных: Копируются 1024 символа (от buffer[0] до buffer[1023])
Нулевой байт: strcpy обязательно добавляет нулевой байт (\0) после последнего скопированного символа.
Переполнение: Нулевой байт записывается в позицию buffer[1024]
------------------------------------------------------------------------------------------------------
Объявляем буфер размером 1024 символа. Максимальный индекс — 1023
#define BUFFER_SIZE 1024
char buffer[BUFFER_SIZE]; // Буфер размером 1024 байта
char input[1025]; // Входная строка, содержащая 1024 символа + \0
------------------------------------------------------------------------------------------------------
Как это исправить (Хорошая практика)
Использование snprintf (Предпочтительный безопасный метод) Это самый безопасный способ, поскольку snprintf гарантирует, что нулевой байт будет добавлен, и не запишет данные за пределы указанного размера.
// snprintf гарантирует, что в буфер buffer будет записано не более BUFFER_SIZE байт,
// включая завершающий нулевой байт.
snprintf(buffer, BUFFER_SIZE, "%s", input);
Использование strncpy (с осторожностью)
// size_t total_to_copy = strlen(input);
// Копируем МЕНЬШЕ, чем размер буфера, чтобы гарантировать место для \0.
// strncpy копирует (BUFFER_SIZE - 1) символов.
strncpy(buffer, input, BUFFER_SIZE - 1);
// 💡 Важно: strncpy НЕ ГАРАНТИРУЕТ добавление \0, если исходная строка слишком длинна.
// Это нужно делать вручную.
buffer[BUFFER_SIZE - 1] = '\0';
|
|
проблемы, связанные с управлением памятью и указателями, являются вечным источником ошибок при работе со строками символов в C.
|
Проблема со строками в C
Когда в C говорят о "проблемах со строками символов", они обычно имеют в виду следующие сценарии, возникающие из-за отсутствия автоматического управления памятью и явного использования указателей:
1. Алиасинг (Aliasing) и Неявное разделение (Implicit Sharing)
Проблема, описанная в примере Java (когда ссылка принимается за копию), в C возникает, когда вы работаете с указателями на строки:
char *s1 = malloc(10);
strcpy(s1, "hello");
char *s2 = s1; // НЕ КОПИЯ! s2 указывает на то же место, что и s1 (алиасинг).
// Если вы измените s1, вы измените s2:
s1[0] = 'H';
// s2 теперь тоже "Hello"
В C нет встроенного "метода-клона". Чтобы получить настоящую копию строки, нужно явно выделить новую память и скопировать туда данные (обычно через malloc и strcpy или strdup).
2. Утечки памяти (Memory Leaks)
Если строка была выделена динамически (malloc), и программист забыл ее освободить после создания копии или передачи, происходит утечка памяти.
3. "Висячие" указатели (Dangling Pointers)
Если функция возвращает указатель на локальную строку (которая хранится в стеке и будет уничтожена после выхода из функции), этот указатель становится недействительным, но может быть использован, что приводит к неопределённому поведению.
Вывод: Проблема, которую в Java решают через явное клонирование, в C является более фундаментальной, поскольку строка — это просто указатель на начало массива байтов, и программист должен постоянно вручную следить за выделением, копированием и освобождением памяти, чтобы избежать путаницы между указателем и фактической копией данных.
|
|
|
|
|
|
Логическая Ложь (false): Представлена только значением 0
Логическая Истина (true): Представлена любым ненулевым значением. Это включает все положительные числа, а также все отрицательные числа
т.е. -1 это true
За счет автоматического преобразования типов, строка преобразуется в число-мусор которое подходит под истину true
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int count = "";
printf("%d\n", count);// -711057404
_Bool b = count;
printf("%d\n", b);// 1
b = -45;
printf("%d", b);// 1
return EXIT_SUCCESS;
}
|
|
Управление потоком в циклах break и continue
|
break: Немедленно завершает выполнение ближайшего цикла (for, while, do-while или switch), передавая управление коду, следующему за циклом.
continue: Пропускает оставшуюся часть текущей итерации цикла и немедленно переходит к следующей итерации (проверяет условие и выполняет инкремент/декремент).
continue прерывает выполнение текущей итерации и переходит к третьей части цикла for (выражению инкремента/декремента), а после к проверке условия
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
for (int i = 0; i < 10; i++) {
printf("%d ", i);
}
return EXIT_SUCCESS;
}
|
|
for
Особенности работы
for ( ; ; ) {} бесконечный цикл
|
for (тип переменная = начальное_значение; условие; инкремент) {
// Тело цикла
}
for (заходит первый раз при инициализации; заходит для проверки условия каждую итерацию и после отдает поток управления телу цикла; заходит в эту секцию цикла после каждого выполнения тела цикла) {
// В тело цикла зайдет если условие истинно
}
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int i = 0;// 0 четное число
for (;i < 10 && i%2==0; i++) {
printf("%d ", i);
}
// Вывод: 0
// так как в условии прописано что хотим только четные i и 0 это четное
// то мы попадаем после проверки условий в тело цикла и печатаем 0
// после происходит инкремент i++ и теперь i=3 уже нечетное
// и следующее дейсвие это проверка условия которое мы не проходим
printf("\n");
i = 0;
for (;i < 10 && i%2==0; i+=2) {
printf("%d ", i);
}
// Вывод: 0 2 4 6 8
// первая проверка условия на четность i=0 проходит, далее тело цикла печатаем 0 и далее инкремент на 2 т.е. i=0+2=2
// далее проверка условия на четность i=2 проходит, далее тело цикла печатаем 2 и далее инкремент на еще 2 т.е. i=2+2=4
// далее проверка условия на четность i=4 проходит, далее тело цикла печатаем 4 и далее инкремент на еще 2 т.е. i=4+2=6
// ...
printf("\n");
i = 0;
for (;i < 10 && i%2==0; i++) {
printf("%d ", i);
i++;
}
// Вывод: 0 2 4 6 8
// мы два раза выполняем инкремент i++, первый в теле и второй сразу после этого и таким образом это эквивалентно i+=2
return EXIT_SUCCESS;
}
Да такое чучело тоже возможно:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
void increment(int *x){
*x=*x+1;
}
int main(void) {
for ( int i=0,y=0; i < 10; increment(&i),y=(i,444),"просто строка",printf("%d ",y)) {
// 444 444 444 444 444 444 444 444 444 444
}
return EXIT_SUCCESS;
}
|
|
while
while (true) {} - бесконечный цикл
while (scanf("If", &num) ==1); - бредоцикл
|
while
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int count = 5;
while (count > 0) {
printf("%d ", count);
count--;
}
count = 5;
while (--count);
printf("%d",count);// 0
return EXIT_SUCCESS;
}
do while
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int num = 0;
do {
printf("Выполняется один раз.\n");
num++;
} while (num < 0);
return EXIT_SUCCESS;
}
|
|
префиксный инкремент ++i
постфиксный инкремент i++
|
префиксный инкремент ++i
постфиксный инкремент i++
Разница в том когда переменная i фактически увеличивается и значении, которое возвращает выражение
С декрементом все аналогично.
Кодировать таким способом считается плохим стилем, так как путает
nextnum = (--у + n++)*6;
ans = num/2 + 5*(1 + num++);
Избегайте проблематичных возможностей языка.
Здесь переменная count может вычисляться до или после ее использования в качестве индекса массива ptr.
ptr[count] = name[++count];
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int x = 0;
int a = x++; // постфиксная форма: переменная x меняется после ее присваивания
int b = ++x; // префиксная форма: переменная x меняется до ее присваивания
printf("a=%d,b=%d", a, b);// a=0,b=2
return EXIT_SUCCESS;
}
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
int i = 0;
// сперва происхидит проверка условия, потом i увеличивается на 1
while (i++ < 3){
printf("%d", i);// 123
}
printf("\n");
// i сперва увеливается на 1, потом происходит проверка условия
i = 0;
while (++i < 3){
printf("%d", i);// 12
}
return EXIT_SUCCESS;
}
|
|
|
|
|
|
В C классы хранения (storage classes) определяют где хранятся переменные, сколько они живут (время жизни, lifetime), и какую область видимости (scope) имеют.
|
|
|
auto - по умолчанию все локальные переменные, в явном виде писать нет необходимости
register - игнорируется компиляторами
static (static внутри функции)
- Переменная существует всё время работы программы (lifetime — глобальный).
- Но видимость остаётся локальной для функции.
- Инициализируется один раз
void counter() {
static int x = 0; // один раз
x++;
printf("%d\n", x);
}
static перед глобальной переменной или функцией - Делает её видимой только в данном файле (internal linkage)
Другой файл не может объявить её через extern и использовать, инкапсуляция!
Благодаря чему устраняется возможность конфликта имен.
static int hidden = 42; // видно только в этом файле
static void foo() {...}
extern - Говорит: эта переменная определена где-то в другом месте, т.е. это не создание, а как прототип
- Используется для глобальных переменных, чтобы использовать переменную в нескольких файлах, не создавая её заново
- Для функций extern не нужен, потому что они уже external по умолчанию.
Файл a.c:
int count = 0; // определение
Файл a.h:
extern int count;
Файл main.c:
#include "a.h"
extern int count;
extern int count = 1; // Error, любое объявление с инициализацией — это определение, а оно было ранее в файле a.c
Если бы мы начали использовать переменную count без обьявления ее через extern то получили бы ошибку линковщика multiple definitions.
Но в данном случае, она уже обьявлена в файле "a.h" так что в main.c можно не обьявлять.
Глобальные переменные не видны в других файлах автоматически.
В C каждый .c-файл — это отдельный translation unit, и глобальная переменная существует только внутри того файла, где она определена, если ты не используешь extern
|
|
Выделение памяти malloc
- Всегда проверяйте возвращаемое значение
- Используйте sizeof(*pointer) вместо sizeof(type)
- Инициализируйте память после выделения
- Всегда освобождайте память
- Обнуляйте указатели после free
|
В старом стиле (C89/C90) небыло автопреобразования void* к любому указателю и приходилось явно приводить к типу
double *ptd = (double *)malloc(30 * sizeof(double)); // ❌ Устарело, но требуется в C++
В современном C (C99+) указатель void* автоматически приводится к любому указателю, поэтому просто
double *ptd = malloc(30 * sizeof(double));
┌─────────────────┐
│ Стек │ ← Автоматические переменные
│ (Stack) │ (быстрый, ограниченный)
├─────────────────┤
│ ↓ Растет │
│ │
│ ↑ Растет │
│ │
├─────────────────┤
│ Куча │ ← Динамическая память (malloc/free)
│ (Heap) │ (медленнее, большой размер)
├─────────────────┤
│ BSS │ ← Неинициализированные глобальные
├─────────────────┤
│ Data │ ← Инициализированные глобальные
├─────────────────┤
│ Text/Code │ ← Программный код
└─────────────────┘
|
|
|
Как вы помните, память под статические данные выделяется во время загрузки программы в память, а память под автоматические данные выделяется, когда поток управления программы входит в блок, и освобождается, когда поток управления покидает блок.
Некоторые операции по выделению памяти происходят автоматически.
Например, в результате объявлений резервируется пространство памяти, достаточное для хранения переменной float и
строки.
float х;
char place [] = "Поющие в терновнике";
int plates[100]; // явно запросить определенный объем памяти
Во всех показанных случаях объявление также предоставляет идентификатор выделенной памяти, так что для обращения к данным можно использовать х или place.
Язык С выходит за эти рамки. Во время выполнения программы можно выделять дополнительную память.
функция malloc возвращает адрес первого байта в выделенном блоке памяти, если не удастся выделить память то вернет NULL
#include <stdio.h>
#include <stdlib.h> // malloc, EXIT_SUCCESS
#include <string.h> // для memset
#include <stddef.h> // для NULL, size_t
#include <stdint.h> // для SIZE_MAX максимальное значение типа size_t
// проверка переполнения
size_t calculate_needed_memory(size_t element_count, size_t element_size) {
if (element_count > SIZE_MAX / element_size) {
return 0;
}
return element_count * element_size;
}
int main() {
int *arr = NULL;
size_t array_size = 100;
size_t needed = calculate_needed_memory(array_size, sizeof(*arr));
if (needed == 0) {
fprintf(stderr, "Слишком большой размер запрашиваемой памяти: %ld\n", needed);
return EXIT_FAILURE;
}
// int *arr = malloc(array_size * sizeof(*arr));
// или без проверки переполнения размера
arr = malloc(needed);
if (arr == NULL) {
fprintf(stderr, "Не удалось выделить память для массива\n");
return EXIT_FAILURE;
}
// Указатель на первый адрес последовательности неинициализирован, поэтому перед использованием нужно заполнить данными
// самому либо изначально использовать для выделения памяти `calloc`
// Использование памяти
for (size_t i = 0; i < array_size; i++) {
arr[i] = (int)(i * i);
}
printf("%d",arr[0]);
// Не забываем освободить!
free(arr);
arr = NULL; // Хорошая практика
return EXIT_SUCCESS;
}
|
|
Использование calloc - автоматическое запонение нулями
|
#include <stdio.h>
#include <stdlib.h> // malloc, EXIT_SUCCESS
#include <stddef.h> // NULL
int main() {
// calloc - автоматическое запонение нулями
size_t array_size = 100;
int *arr = calloc(array_size, sizeof(*arr));
// arr уже заполнен нулями
// Не забываем освободить!
free(arr);
arr = NULL; // Хорошая практика
return EXIT_SUCCESS;
}
|
|
Безопасное перевыделение памяти (realloc)
|
#include <stdio.h>
#include <stdlib.h> // malloc, EXIT_SUCCESS
int main() {
size_t current_size = 10;
int *dynamic_array = malloc(current_size * sizeof(*dynamic_array));
// Увеличиваем массив
size_t new_size = current_size * 2;
int *temp = realloc(dynamic_array, new_size * sizeof(*dynamic_array));
if (temp == NULL) {
// realloc失敗 - старый указатель все еще валиден
free(dynamic_array);
fprintf(stderr, "Не удалось увеличить массив\n");
return EXIT_FAILURE;
} else {
dynamic_array = temp; // Используем новый указатель
current_size = new_size;
}
// Не забываем освободить!
free(dynamic_array);
dynamic_array = NULL; // Хорошая практика
return EXIT_SUCCESS;
}
|
|
|
|
|
|
Что хранится: Локальные, автоматические переменные и массивы (объявленные внутри функций без static).
Особенность: Память выделяется и освобождается автоматически (при входе/выходе из функции). Это быстро, но размер ограничен.
Время жизни локальной (без static) пока функция выполняется.
Не возвращайте указатели на локальные переменные
int* bad() {
int x = 10;
return &x; // UB!
}
Пример: int x[10]; внутри main()
|
|
|
Что хранится: Память, выделенная динамически по запросу программиста (malloc, calloc, realloc).
Особенность: Память должна быть явно освобождена (free). Двойное освобождение → UB, авария
Время жизни динамической памяти пока free не вызван.
Пример:
int *p = malloc(10 * sizeof(int));
|
|
3. Секция данных (Data Section) / Статическая память
|
Описывающий одну из основных областей памяти, которую операционная система выделяет для запуска программы на C.
В отличие от Стека и Кучи, которые используются для динамического управления памятью, Секция данных существует для хранения данных, известных на этапе компиляции.
Секция данных (часто называемая также сегментом данных или статической областью памяти) — это часть виртуальной памяти, которая используется для хранения статических и глобальных переменных и массивов.
Что хранится: Глобальные переменные и массивы, а также локальные переменные и массивы, объявленные с ключевым словом static.
Статическая память. Доступна из любой функции (глобально или через static в пределах файла). Инициализируется нулями (BSS) или указанным значением (Data)
Время жизни статической и глобальной памяти на протяжении выполнения программы.
Особенность: Память выделяется при запуске программы и сохраняется до её завершения. Компилятор знает их размер заранее.
Пример: static int arr[10]; внутри main() или int global_arr[10]; вне функций.
|
|
|
|
|
|
- const - переменную нельзя менять
- volatile - переменную нельзя оптимизировать, её значение может изменить внешняя программа, например в микроконтроллерах
- restrict - обещание от программиста, что указатель — единственный, который обращается к объекту
- _Atomic ― это тема из C11, добавленная ради нормальной многопоточности
Комбинации квалификаторов
const volatile int reg;
|
|
const — нельзя менять значение
Отличие от C++, в C обьявленная внешне переменная const считается глобальной с внешним связыванием, т.е. можно обратится из других файлов, а C++ это означает внутреннее связывания только для этого файла, как будто это static const
|
Пример:
const int a = 10;
a = 20; // ошибка
Но можно менять через указатель, если снять const (опасно):
const int a = 10;
int* p = (int*)&a;
*p = 20; // компилируется, но UB
const в указателях:
int * const p; // p — константный указатель (сам адрес менять нельзя но значение можно)
const int * p; // указатель на константный int (значение менять нельзя но адрес указателя можно)
const int * const p; // нельзя ни менять указатель, ни значение
|
|
volatile — говорит компилятору: НЕ оптимизируй доступ
Используется, если значение может меняться:
- аппаратурой (регистры устройств)
- обработчиком прерываний
- другим потоком
- DMA, memory-mapped IO
|
volatile int flag;
while (!flag) {
// цикл ждёт, пока внешний код изменит flag
}
Если убрать volatile, компилятор может оптимизировать цикл в:
while (1) {}
потому что “flag внутри цикла не меняется”.
Например, что есть такой код:
vall = х;
/* код, в котором х не используется */
val2 = х;
Интеллектуальный ( оптимизирующий ) компилятор может заметить, что объект х используется два раза без изменения в промежутке его значения. Он временно может сохранить значение х в регистре.
Затем, когда х понадобится для val2, появляется возможность сэкономить время, прочитав значение из регистра, а не из исходной ячейки памяти. Такая процедура называется кеширование.
Обычно кеширование является полезной оптимизацией, но не в случае, когда значение х изменяется в промежутке между двумя операторами каким-то другим действием.
|
|
restrict — я ОБЕЩАЮ компилятору, что другие указатели НЕ указывают на тот же объект
|
Значит: этот указатель — единственный способ доступа к данным, на которые он указывает.
void copy(int * restrict dest, const int * restrict src, size_t n) {
for (size_t i = 0; i < n; i++) {
dest[i] = src[i];
}
}
Оптимизатор может распараллеливать, vectorize, unroll цикл, потому что уверен:
dest и src не пересекаются.
Без restrict компилятор обязан допускать, что память может быть одна и та же:
copy(a, a, 100); // может быть aliasing
|
|
_Atomic - говорит что доступ к этой переменной должен быть атомарным и безопасным между потоками
Rust'овское аналогичное — AtomicU32, AtomicBool и т.д.
atomic_fetch_add
|
То есть операции читают/пишут целиком, без разрыва посередине, и с нужными гарантиями памяти.
#include <stdatomic.h>
_Atomic int counter = 0;
atomic_int counter; // (atomic_int — typedef из <stdatomic.h>)
Зачем это нужно? Проблема обычной переменной в многопоточности:
int counter = 0;
void thread() {
counter++; // НЕ атомарно! три операции == load → add → store, может прерваться посредине процесса.
}
Но круче — используются функции из библиотеки tdatomic.h
#include <stdatomic.h>
atomic_int counter;
void thread() {
// Загрузка / запись:
int v = atomic_load(&x);
atomic_store(&x, 123);
atomic_fetch_add(&counter, 1);
atomic_fetch_sub(&x, 1);
atomic_compare_exchange_strong(&x, &expected, new_value);// Сравнить-и-поменять (CAS)
}
|
|
|
|
|
|
в C нет единого универсального стандарта обработки ошибок, поэтому в реальных программах встречаются разные стили
Возврат кода ошибки
errno - глобальная переменная для ошибки
errno значение
2 ENOENT (нет файла)
13 EACCES (нет прав)
22 EINVAL (неверный аргумент)
- perror - функции для вывода человеко-читаемого пояснения по errno
- exit(EXIT_FAILURE) - в
<stdlib.h> аварийный выход из программы, завершает весь процесс, вызывает atexit() и очищает буферы
- abort() - немедленно завершает программу, не вызывает функции очистки, может создать дамп памяти — полезно для отладки.
- strerror() — это функция, которая превращает числовой код ошибки (errno) в человеко-читаемую строку.
- stderr - стандартный поток вывода ошибок
- eprintf делает все то же самое, что и fprintf(stderr, . . .), но в случае ошибки выводит сообщение о ней и завершает программу, возвращая в систему код ошибки.
Стандартные коды ошибок (основные):
- ENOENT - файл не найден
- EACCES - нет доступа
- EEXIST - файл уже существует
- EINVAL - неверный аргумент
А в libc/POSIX пишут функции с возвратом кода ошибки и установки его в errno и без вывода на печать
Многие функции из libc в случае ошибки записывают код ошибки в глобальную переменную errno
#include <stdio.h>
#include <errno.h> // perror, errno
#include <string.h> // для strerror
#include <stdlib.h> // EXIT_SUCCESS
int main(void){
FILE *file = fopen("nope.txt", "r");
if (!file) {
printf("Error: %d\n", errno);
// или
perror("fopen failed"); // fopen failed: No such file or directory
// или
printf("Ошибка: %s\n", strerror(errno));
// или
fprintf(stderr, "Ошибка: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
return EXIT_SUCCESS;
}
Избегайте проблематичных возможностей языка. strerror
Здесь значение errno может вычисляться еще до вызова функции log.
printf("%f %s\n", log(-1.23), strerror(errno));
|
|
_Static_assert — compile-time assert (ошибки при компиляции)
|
Зачем нужно
- проверка размеров структур (bin-протоколы)
- проверка ABI-совместимости
- проверка конфигурации compile-time
- проверка платформозависимых предположений
- замена ручных #if
Пример: размер структуры соответствует протоколу ABI
#include <stdint.h> // int8_t, uint16_t
struct Msg {
uint8_t id;
uint16_t len;
};
_Static_assert(sizeof(struct Msg) == 3, "Message size mismatch");
Пример: убедиться, что int = 4 байта
_Static_assert(sizeof(int) == 4, "int must be 4 bytes");
Пример: проверка полей перед отправкой в DMA (embedded)
_Static_assert(__alignof__(DMA_Descriptor) == 4, "DMA descriptor must be 4-byte aligned");
|
|
assert() из библиотеки: assert.h макрос для отладки
Идея состоит в том, чтобы идентифицировать критические места в программе, где должны быть истинным и определенные условия, и с помощью оператора assert() завершать программу, если одно из указанных условий нарушается.
|
Если выражение оценивается как ложное (=== нулевое), макрос assert() выводит в стандартный поток ошибок (stderr) сообщение об ошибке и вызывает функцию abort(), которая прекращает выполнение программы.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE и для abort(), если assert сработает
#include <stddef.h> // NULL
//#define NDEBUG // отключение проверок assert (должен быть определен до импорта assert.h)
#include <assert.h> // для assert()
void test(int *ptr){
assert(ptr != NULL);
printf("OK:\naddress:%p\ndata:%d\n", (void*)ptr, *ptr);
}
int main() {
int *ptr = NULL;
//int x=4;
//ptr = &x;
test(ptr);
return EXIT_SUCCESS;
}
- Компиляция и запуск с включеной проверкой assert:
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 error.c -o main && ./main
my_program.out: error.c:10: test: Assertion ptr != NULL' failed.
- Компиляция и запуск с выключеной проверкой assert т.е. RELEASE:
Макрос DNDEBUG отключающий assert можно передать при компиляции, это и есть режим release в языке C
gcc -std=c99 -DNDEBUG -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 error.c -o main && ./main
как видно assert не проверялся и ошибка пошла дальше!!!
</div></td>
<td id="base_c_ab22682f97cfec30_other"><div class="cell-content" contenteditable="true"></div></td>
</tr>
<tr id="base_c_f731c6690cd6da36">
<td id="base_c_f731c6690cd6da36_topic"><div class="cell-content" contenteditable="true">
**exit(EXIT_FAILURE)** - в `<stdlib.h>` аварийный выход из программы, завершает весь процесс.
Функция неявно вызывается при завершении main()
**int atexit(void (\*func)(void))** - регистрирует функции которые должны быть вызваны после exit() (или просто в конце программы) и эти функции должны иметь тип void и не принимать аргументов.
</div></td>
<td id="base_c_f731c6690cd6da36_content"><div class="cell-content" contenteditable="true">
**exit**() - Завершает программу глобально, вызывая:
* все функции, зарегистрированные через atexit
* закрытие stdout, stderr, файлов
* Не подходит для embedded / микроконтроллеров (без ОС).
**atexit**() - Регистрирует функцию, вызываемую при завершении exit():
в embedded чаще всего не работает, потому что нет настоящей программы завершения
```c
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void cleanup(void) { printf("bye!\n"); }
int main() {
atexit(cleanup);
exit(EXIT_FAILURE);
}
|
|
В embedded ошибки обрабатывают по другому
|
NaN/INF — это маркеры ошибок, но в embedded ошибки ловят по-другому
На PC:
x = 1.0 / 0.0 → INF
y = 0.0 / 0.0 → NAN
В embedded ошибки обрабатывают так:
- через return-коды
- через
Result<T,E>
- через флаги
- через errno-like схемы
- через assert в debug-прошивке
- через watchdog reset
Использовать NaN как сигнал ошибки — небезопасно и непредсказуемо.
А когда всё-таки используют NaN/Inf в embedded?
|
|
|
Когда в системных функциях Unix возникают ошибки, они обычно возвращают -1 и записывают в глобальную целочисленную переменную errno номер ошибки, сообщающий причину.
Например, вот как можно проверить наличие ошибки при обращении к системному вызову fork:
#include <sys/types.h> // pid_t
#include <unistd.h> // fork
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
// Реализация функции ошибки
void unix_error(char *msg) {
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
exit(1);
}
pid_t Fork(void) {
pid_t pid;
if ((pid = fork()) < 0)
unix_error("Fork error");
return pid;
}
int main() {
pid_t pid = Fork();
if (pid == 0) {
printf("Я — процесс-потомок!\n");
} else {
printf("Я — родитель, мой потомок имеет PID: %d\n", pid);
}
return 0;
}
|
|
Макросы для логирования, ошибок и ассершнов
|
#define LOG(msg) \
printf("[%s:%d] %s\n", __FILE__, __LINE__, msg)
#define ASSERT(x) \
if (!(x)) { printf("ASSERT FAIL: %s:%d\n", __FILE__, __LINE__); while(1); }
|
|
Директива #error
заставляет препроцессор выдать сообщение об ошибке, которое включает любой текст, указанный в директиве.
|
#if __STDC_VERSION__ != 1999012
#error Несоответствие C99
#endif
|
|
Полный пример преобразования строки в число с обработкой ошибок
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <errno.h>
int main() {
char *str = "123abc";
char *endptr;
errno = 0; // Сбрасываем ошибки
long num = strtol(str, &endptr, 10);
// Проверяем все возможные ошибки:
if (errno != 0) {
perror("Ошибка strtol");
} else if (endptr == str) {
printf("Нечисловая строка\n");
} else if (*endptr != '\0') {
printf("Частично преобразовано: %ld, хвост: '%s'\n", num, endptr);
} else {
printf("Успех: %ld\n", num);
}
return EXIT_SUCCESS;
}
|
|
Что должна делать функция в такой библиотеке, если случается непоправимая ошибка?
|
Что должна делать функция в такой библиотеке, если случается непоправимая ошибка? Функции, приведенные ранее в этой главе, выводили на экран сообщение об ошибке и завершали программу аварийно. Это вполне подходит для многих программ, особенно небольших утилит и автономных приложений. Но во многих случаях такой образ действий окажется неправильным, поскольку не даст другим модулям программы шанса исправить положение. Например, текстовый редактор должен попытаться не потерять информацию из редактируемого документа. В некоторых ситуациях библиотечная функция не должна даже выводить сообщение, потому что программа вполне может выполняться в среде, где такое сообщение исказило бы выходные данные или просто пропало без следа. Разумный вариант — это выводить диагностические сообщения в файл-протокол, который можно читать независимо от других данных.
Перехватывайте ошибки на низком уровне, обрабатывайте их на высоком. Общий принцип гласит, что ошибки следует перехватывать на как можно более низком системном уровне, а вот обрабатывать их — на высоком. В большинстве случаев решать, что делать в связи с ошибкой, должен вызывающий, а не вызываемый модуль. Библиотечные функции могут помочь в этом, завершая ошибочную операцию корректно и не аварийно. Рассуждая таким образом, в случае несуществующего поля данных лучше возвращать NULL, чем завершать программу аварийно.
Сообщения об ошибках должны содержать всю имеющуюся информацию о них и быть как можно более понятными
без контекста.
Например, следующее сообщение невразумительно:
"estrdup failed"
На самом деле ему положено выглядеть так:
"markov: estrdup("Derrida") failed: Memory limit reached"
В программах на С с помощью пары функций setjmp и longjmp можно организовать низкоуровневую системную базу для построения механизма исключительных ситуаций.
|
|
|
/* check: проверка условия, контрольный вывод, завершение */
void check(char *s){
if (varl > var2) {
printf("%s: varl %d var2 %d\n", s, varl, var2);
fflush(stdout); /* завершаем операции вывода */
abort(); /* сигнализируем аварийное завершение */
}
}
Вызывать функцию abort из стандартной библиотеки С, которая вызывает аварийное завершение выполнения
программы для последующего анализа при помощи отладчика.
Нашу функцию check или ей подобную следует вставлять в код всякий раз, когда она может оказаться уместной для проверки кода с ошибкой:
check("before suspect");
/* ... подозрительный код ... */
check("after suspect");
|
|
Демонстрация использования переполнения буффера
|
Демонстрация использования переполнения буфера
Пример
// main.c -- программа входа
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h> // Для низкоуровневого чтения (read)
#define BUFFER_SIZE 1 // Размер нашего уязвимого буфера
int main(void) {
// 1. Флаг, который мы хотим затереть (4 байта)
// Размещается на стеке
int32_t security_flag = 0xDEADBEEF;
// 2. Уязвимый буфер (1 байт)
// Размещается на стеке
char query[BUFFER_SIZE];
// Внимание: GCC может переупорядочить эти переменные на стеке!
// Для 64-битных систем они могут быть расположены как [query] [padding] [security_flag]
int qsize;
char *content_length_str;
// --- Имитация CGI: Чтение CONTENT_LENGTH ---
content_length_str = getenv("CONTENT_LENGTH");
if (content_length_str == NULL) {
fprintf(stderr, "Ошибка: Не установлена переменная CONTENT_LENGTH.\n");
return 1;
}
qsize = atoi(content_length_str);
printf("--- Демонстрация переполнения (Стек) ---\n");
printf("1. CONTENT_LENGTH: %d\n", qsize);
printf("2. Исходное значение security_flag: %x\n", security_flag);
// 3. Вычисляем точный размер padding (выравнивания)
// На стеке переменные могут идти в обратном порядке от порядка объявления (query, затем security_flag).
// Мы берем разницу между адресом query и адресом security_flag.
// Используем uintptr_t для безопасной арифметики с указателями.
uintptr_t query_addr = (uintptr_t)query;
uintptr_t flag_addr = (uintptr_t)&security_flag;
// Расстояние (включая флаг)
size_t offset_bytes = (flag_addr > query_addr) ?
(flag_addr - query_addr) + sizeof(security_flag) :
(query_addr - flag_addr) + sizeof(query); // В случае обратного порядка
printf("3. Разница в адресах: %zu байт\n", (size_t)abs((long)query_addr - (long)flag_addr));
// --- ОПАСНАЯ ОПЕРАЦИЯ: read() ---
// Используем read() для низкоуровневого чтения из stdin.
// Мы читаем из stdin qsize байтов, которые переполняют query.
ssize_t bytes_read = read(STDIN_FILENO, query, qsize);
printf("4. Прочитано байтов: %zd\n", bytes_read);
// --- Проверка результата ---
if (security_flag != 0xDEADBEEF) {
printf("🚨 УСПЕХ: Флаг был изменен! Переполнение достигнуто.\n");
printf("5. Фактическое значение security_flag: %#x\n", security_flag);
// 💡 Вывод содержимого памяти по байтам (помогает понять порядок)
printf("6. Флаг побайтно (в обратном порядке чтения):\n");
// Указатель на 4-байтный флаг
unsigned char *p = (unsigned char *)&security_flag;
// Итерация по 4 байтам флага
for (int i = 0; i < sizeof(security_flag); i++) {
// В little-endian архитектуре p[0] - младший байт (CC), p[3] - старший байт (BB)
printf(" Байт %d: 0x%02x (%c)\n", i, p[i], p[i]);
}
} else {
printf("❌ НЕУДАЧА: Необходимо увеличить CONTENT_LENGTH.\n");
}
return 0;
}
/*
gcc main.c -o stack_exploit -O0 -fno-stack-protector
env CONTENT_LENGTH=4 ./stack_exploit <<< $(python3 -c 'import sys; sys.stdout.buffer.write(b"0ABCD")')
--- Демонстрация переполнения (Стек) ---
1. CONTENT_LENGTH: 4
2. Исходное значение security_flag: deadbeef
3. Разница в адресах: 1 байт
4. Прочитано байтов: 4
🚨 УСПЕХ: Флаг был изменен! Переполнение достигнуто.
5. Фактическое значение security_flag: 0xde434241
6. Флаг побайтно (в обратном порядке чтения):
Байт 0: 0x41 (A)
Байт 1: 0x42 (B)
Байт 2: 0x43 (C)
Байт 3: 0xde (�)
*/
|
|
Измерение времени и профилирование
|
Измерение времени и профилирование
В Unix команда time для измерения времени, затрачиваемого на выполнение программы:
$ time ./my_program.out
real 0m0,005s // "реальное" время, в течение которого работала программа;
user 0m0,001s // "пользовательское" время, затраченное процессором на выполнение программы;
sys 0m0,004s // "системное" время, затраченное операционной системой на программу
В любом случае выдаваемые ею данные будут более информативными, надежными и простыми в получении, чем при измерении времени вручную секундомером.
|
|
Замер времени работы участка кода
|
#include <time.h>
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
clock_t before;
double elapsed;
before = clock ();
//------------------------
int c = 0;
for(int i =0; i<1000000;i++){
c = i * c;
}
//------------------------
elapsed = clock() - before;
printf("function used %.3f seconds\n", elapsed/CLOCKS_PER_SEC);
return EXIT_SUCCESS;
}
|
|
Компиляция с оптимизацией
Что конкретно делает оптимизатор:
- Удаление мертвого кода - неиспользуемые переменные/функции
- Встраивание функций - замена вызова телом функции
- Развертывание циклов - уменьшение накладных расходов
- Свертка констант - вычисление выражений на этапе компиляции
- Оптимизация хвостовой рекурсии - превращение в цикл
|
# Без оптимизации (по умолчанию)
gcc -O0 program.c -o program
# Базовая оптимизация
gcc -O1 program.c -o program
# Полная оптимизация (рекомендуется)
gcc -O2 program.c -o program
# Агрессивная оптимизация (может увеличить размер кода)
gcc -O3 program.c -o program
# Оптимизация по размеру
gcc -Os program.c -o program
# Оптимизация для отладки (сохраняет отладочную информацию)
gcc -Og program.c -o program
|
|
|
#include <time.h>
#include <stdio.h>
int sum_1(int n){
int c = 0;
for(int i =0; i<n; i++){
c = i + 1 - 5 + 4 + 1;
}
return c;
}
int sum_2(int n){
int c = 0;
for(int i =0; i<n; i++){
c = i * 3 + 8;
}
return c;
}
int sum_3(int n){
int c = 0;
for(int i =0; i<n; i++){
c = i + 100 - 50 - 50;
}
return c;
}
int main(void) {
int r_1 = sum_1(100);
int r_2 = sum_2(100000);
int r_3 = sum_3(10000000);
printf("%d %d %d",r_1,r_2,r_3);
return 0;
}
// gcc -std=c99 -pg clock.c -o my_program.out
// ./my_program.out
// gprof my_program.out gmon.out > analysis.txt
// cat analysis.txt
/*
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ms/call ms/call name
100.00 0.03 0.03 1 30.00 30.00 sum_3
0.00 0.03 0.00 1 0.00 0.00 sum_1
0.00 0.03 0.00 1 0.00 0.00 sum_2
...
*/
|
|
profile kcachegrind
KCachegrind — это мощный GUI-анализатор профилировщика.
sudo apt install kcachegrind
valgrind --tool=callgrind ./my_program.out // создаст файл callgrind.out.*
kcachegrind callgrind.out.*
Компиляция Rust с отладочной информацией
В Cargo.toml добавить:
[profile.release]
debug = true # ← важно для профилирования!
Или компилируй так:
cargo build --release
# debuginfo будет включен из Cargo.toml
|
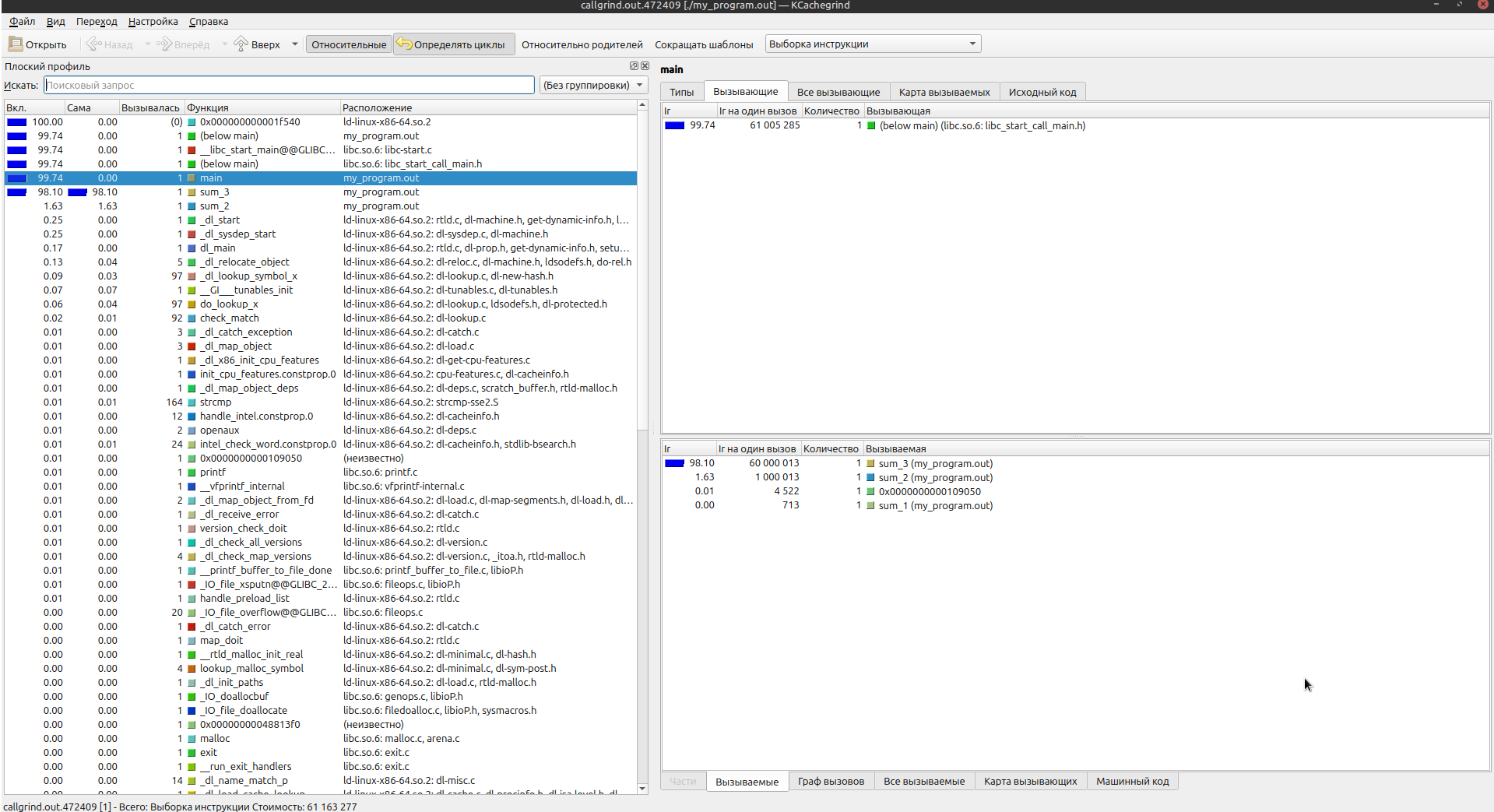
KCachegrind
KCachegrind — это мощный GUI-анализатор профилировщика. Вот что можно делать:
main()
→ process_data() [45% времени]
→ parse_file() [30%]
→ calculate_stats() [15%]
→ save_results() [10%]
- Видишь какие функции съедают больше всего времени
- Сколько раз вызывалась каждая функция
- Время на вызов в абсолютных и относительных величинах
// Можешь кликнуть на функцию и увидеть:
void slow_function() { // ← 65% общего времени
for (int i = 0; i < 1000000; i++) { // ← эта строка - 60%
expensive_operation(); // ← 5%
}
}
valgrind --tool=callgrind ./my_program.out
kcachegrind callgrind.out.*
1. Сортировать функции по времени:
Функция | Время | Вызовы | Время/вызов
slow_function | 65% | 1 | 650ms
expensive_operation| 25% | 1000000| 0.00025ms
main | 10% | 1 | 100ms
2. Смотреть граф вызовов:
- Толщина стрелок = сколько времени ушло на вызов
- Цвета = разные метрики (время, вызовы, и т.д.)
3. Анализировать конкретную функцию:
- Callers - кто вызывает эту функцию
- Callees - кого вызывает эта функция
- Source code - построчная разметка времени
4. Фильтровать результаты:
- Показывать только твой код (исключать системные библиотеки)
- Группировать по модулям/файлам
// Находишь вот такие места:
void process_data() {
for (int i = 0; i < data_size; i++) { // ← 80% времени тут!
// Оказывается этот цикл вызывается 10M раз
// а должен вызываться 1000 раз
}
}
- "Flat Profile" - список функций по убыванию времени
- "Call Graph" - визуальный граф вызовов
- "Caller Map" - кто кого вызывает
- "Source Code" - просмотр с аннотацией времени по строкам
По сути: Видишь всю иерархию вызовов и точно определяешь, где программа тормозит.
...
|
|
перенаправление потока вывода ошибок
|
Перенаправление ошибок:
./program > output.log # stdout в файл, а ошибки на экран
./program 2> errors.log # stderr (ошибки) в файл, а обычный вывод stdout на экран
./program > output.log 2>&1 # stdout и stderr в один файл
|
|
Логирование с разделением потоков
Поток stderr
|
#include <stdio.h>
#include <time.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void log_message(const char *msg) {
printf("[INFO] %s\n", msg); // Обычные логи - буферизуются
}
void log_error(const char *err) {
fprintf(stderr, "[ERROR] %s\n", err); // Ошибки - сразу
}
int main() {
log_message("Программа запущена");
for (int i = 0; i < 5; i++) {
log_message("Выполняется итерация...");
sleep(1);
if (i == 2) {
log_error("Обнаружена проблема!");
}
}
log_message("Программа завершена");
return EXIT_SUCCESS;
}
|
|
|
|
|
Все функции из библиотеки time.h
|
- time_t time(time_t *tloc) — возвращает текущее время в секундах с 1 января 1970 года. Если tloc не NULL, записывает туда результат.
- clock_t clock(void) — возвращает процессорное время, затраченное программой, в тактах процессора.
- double difftime(time_t time1, time_t time0) — разница между двумя time_t в секундах (time1 - time0).
- struct tm *localtime(const time_t *timep) — преобразует time_t в локальное календарное время (struct tm).
- struct tm *gmtime(const time_t *timep) — преобразует time_t в UTC (GMT) календарное время.
- time_t mktime(struct tm *timeptr) — преобразует struct tm в time_t (обратная операция localtime/gmtime).
- char *asctime(const struct tm *timeptr) — преобразует struct tm в читаемую строку "Wed Jun 30 21:49:08 1993\n".
- char *ctime(const time_t *timep) — преобразует time_t в строку, эквивалент asctime(localtime(timep)).
- size_t strftime(char *s, size_t max, const char *format, const struct tm *tm) — форматирует struct tm в строку по шаблону.
- void tzset(void) — устанавливает глобальные переменные timezone и daylight на основе текущей TZ среды.
- int clock_getres(clockid_t clk_id, struct timespec *res) — (POSIX) определяет разрешение часов.
- int clock_gettime(clockid_t clk_id, struct timespec *tp) — (POSIX) возвращает текущее время указанного clock.
- int clock_settime(clockid_t clk_id, const struct timespec *tp) — (POSIX) задает текущее время указанного clock.
- struct tm *localtime_r(const time_t *timep, struct tm *result) — потокобезопасная версия localtime.
- struct tm *gmtime_r(const time_t *timep, struct tm *result) — потокобезопасная версия gmtime.
|
|
strftime перевод даты и времени в текстовую строку заданного формата.
|
size_t **strftime** (char *str, size_t maxsize, const char *str_form, const struct tm * t_time);
Спецификаторы формата для strftime():
%a — сокращённое название дня недели (Mon)%A — полное название дня недели (Monday)%b — сокращённое название месяца (Jan)%B — полное название месяца (January)%c — дата и время в локальном формате%C — век (год / 100, например 20 для 2023)%d — день месяца (01..31)%D — дата в формате MM/DD/YY%e — день месяца (1..31, с пробелом перед однозначными числами)%F — дата в формате YYYY-MM-DD (ISO 8601)%H — часы в 24-часовом формате (00..23)%I — часы в 12-часовом формате (01..12)%j — день года (001..366)%m — месяц (01..12)%M — минуты (00..59)%p — AM или PM%S — секунды (00..60)%T — время в формате HH:MM:SS%u — день недели (1 = понедельник … 7 = воскресенье)%w — день недели (0 = воскресенье … 6 = суббота)%U — номер недели года, неделя с воскресенья (00..53)%W — номер недели года, неделя с понедельника (00..53)%x — дата в локальном формате%X — время в локальном формате%y — год без века (00..99)%Y — год с 4 цифрами (например, 2023)%Z — имя часового пояса%% — символ %
#include <stdio.h> // Для printf
#include <time.h> // Для time, localtime, strftime
#include <stdlib.h> // EXIT_SUCCESS
int main (void){
//Переменная для системного времени
long int s_time;
//Указатель на структуру с локальным временем
struct tm *m_time;
//Строка для сохранения преобразованного времени
char str_t[128]=””;
//Считываем системное время
s_time = time (NULL);
//Преобразуем системное время в локальное
m_time = localtime (&s_time);
//Преобразуем локальное время в текстовую строку
strftime (str_t, 128, ”Дата: %x %A %X %Z”, m_time);
//Выводим строку в консоль
printf (“%s\n”,str_t);
return EXIT_SUCCESS;
}
|
|
Структура работы с датой struct tm
|
#include <stdio.h>
#include <time.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
// Получаем текущее время
time_t now = time(NULL);
if (now == (time_t)(-1)) {
perror("time");
return 1;
}
// Преобразуем time_t в локальное время
struct tm local_tm;
if (localtime_r(&now, &local_tm) == NULL) { // потокобезопасная версия
perror("localtime_r");
return 1;
}
// Выводим поля структуры
printf("Год: %d\n", local_tm.tm_year + 1900); // tm_year — количество лет с 1900
printf("Месяц: %d\n", local_tm.tm_mon + 1); // tm_mon: 0..11
printf("День месяца: %d\n", local_tm.tm_mday);
printf("Часы: %d\n", local_tm.tm_hour);
printf("Минуты: %d\n", local_tm.tm_min);
printf("Секунды: %d\n", local_tm.tm_sec);
printf("День недели: %d\n", local_tm.tm_wday); // 0 = воскресенье
printf("День года: %d\n", local_tm.tm_yday); // 0..365
printf("Летнее время: %d\n", local_tm.tm_isdst); // >0 = DST
// Преобразуем обратно в time_t
time_t reconstructed = mktime(&local_tm);
printf("Обратно в time_t: %ld\n", (long)reconstructed);
// Форматированный вывод через strftime
char buf[64];
strftime(buf, sizeof(buf), "%Y-%m-%d %H:%M:%S", &local_tm);
printf("Форматированное время: %s\n", buf);
return EXIT_SUCCESS;
}
|
|
Замер времени работы участка кода
|
- Холодный старт: Первый запуск всегда медленнее (данные еще не в кэше, страницы памяти не подгружены).
- Оптимизации компилятора: Если замерять пустой цикл типа
for(i=0; i<1000; i++);, компилятор с флагом -O2 или -O3 просто удалит его, так как он ничего не делает. Время будет равно 0.0000.
Замер процессорного времени работы участка кода
Эта функция из time.h возвращает количество «тиков», которые потребила именно твоя программа. Она не учитывает время, когда процессор переключался на другие задачи.
#include <stdio.h>
#include <time.h>
int main() {
clock_t start = clock();
// Код...
clock_t end = clock();
double cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("Процессорное время: %f секунд\n", cpu_time_used);
}
Это современный стандарт для Linux/Unix. Он позволяет мерить время с точностью до наносекунд.
#include <stdio.h>
#include <time.h>
int main() {
struct timespec start, end;
// Засекаем время начала (MONOTONIC — время, которое только растет)
clock_gettime(CLOCK_MONOTONIC, &start);
// --- ТВОЙ КОД ТУТ ---
for (long i = 0; i < 100000000; i++);
// --------------------
// Засекаем время окончания
clock_gettime(CLOCK_MONOTONIC, &end);
// Считаем разницу в секундах
double time_taken = (end.tv_sec - start.tv_sec) +
(end.tv_nsec - start.tv_nsec) / 1e9;
printf("Время выполнения: %f секунд\n", time_taken);
return 0;
}
Самый ленивый способ (без кода)
time ./my_prog
|
|
|
|
|
Массив — это совокупность значений одного и того же типа, которые хранятся в памяти последовательно
|
|
|
|
Приоритет операций разыменование * и инкремента ++ одинаковый, и порядок справа налево
А тут приоритет присваивания += над инкрементом ++:
total += (*arr_ptr)++;
=> будет такой порядок:
total = total + (*arr_ptr); // Сначала: значение в total
(*arr_ptr)++; // Потом: инкремент значения по указателю
Пример:
int sum(int *arr_ptr_local, size_t n){
int total = 0;
for (size_t i = 0; i < n; i++){
// эквивалент *(arr_ptr_local++) т.е. мы не данные инкриминируем, а адрес, шагаем по адресам указателя и берем значения
total += *arr_ptr_local++;
// Error, тут сперва инкремент адреса потом взятие значения, но при этом мы пропускаем нулевой адрес и вылазим за пределы размера массива
// total += *++arr_ptr;
// изменение самого массива, при чем только первого элемента, эквивалентно arr[0] = arr[0]+1; При чем сперва будет операция разыменование и это значение пойдет в total, а потом инкремент меняющий массив
// total += (*arr_ptr_local)++;
}
return total;
}
|
|
Составные литералы (compound literals)
Позволяют создавать временные объекты прямо в выражении
|
int *p = (int[]){1, 2, 3}; // массив на стеке
struct Point *pt = &(struct Point){.x = 5, .y = 10};
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
void foo(const int arr[], int n){
for (int i=0; i<n; i++){
printf("%d\n", arr[i]);
}
}
int main() {
// инициализация указателя составным литералом массива
int *arr = (int [5]){1,2,3,4,5};
for (int i=0; i<5; i++){
printf("%d\n", arr[i]);
}
// передача в функцию
foo((int [5]){1,2,3,4,5}, 5);
return EXIT_SUCCESS;
}
|
|
|
Создание массива
-
автоматические переменные (обычные локальные) → хранятся в стеке (STACK), у которого есть жёсткое ограничение по размеру
-
static и глобальные переменные → хранятся в статическом сегменте памяти (data/bss) (Секция данных, HEAP) и не ограничены стеком
Размер для стека зависит от системы: Linux типичный размер стека на поток 8 MB. Windows 1 MB. macOS 512 KB. Микроконтроллеры иногда 1–16 KB.
Превышение размера стека приведёт к stack overflow.
Сегмент .bss на диске не занимает места в бинарнике (в ELF-файле), а при запуске OS просто выделяет нули в RAM.
А секция .data занимает размер в бинарнике
#include <stdio.h>
#include <stdlib.h>
// массивы не имеют явной инициализации, поэтому компилятор кладёт их в .bss
// OS при запуске программы выделяет память под эти переменные и обнуляет её автоматически.
static int bss_static_arr[10]; // статический, неинициализирован → .bss
int bss_global_arr[10]; // глобальный, неинициализирован → .bss
// Если массив инициализирован не нулями, он попадёт в .data
static int data_static_data[5] = {1,2,3,4,5}; // .data
int data_global_data[5] = {10,20,30,40,50}; // .data
int main(void) {
printf("%d\n", bss_static_arr[0]);// 0
printf("%d\n", bss_global_arr[0]);// 0
printf("%d\n", data_static_data[0]);// 1
printf("%d\n", data_global_data[0]);// 10
return EXIT_SUCCESS;
}
|
|
|
#include <stdio.h>
#include <stdlib.h> // malloc, calloc, realloc, free, EXIT_SUCCESS
#include <stddef.h> // NULL
#define NELEMS(array) (sizeof(array) / sizeof(array[0]))
#define MONTHS 12
// 1. (Секция данных .bss) Глобальный массив (инициализируется нулями)
// Хранится в статической память, размер ограничен только RAM
double arr_1[100];
// (Секция данных .data) Значения нельзя изменить
const int days [MONTHS] = {31, 28, 31,30, 31, 30, 31, 31,30, 31,30, 31};
int main() {
// перебор
size_t array_length = NELEMS(arr_1);
for (size_t i=0; i < array_length; i++) {
printf("%lf",arr_1[i]);
}
// 2. (STACK) Размер (5) определяется количеством элементов при компиляции
int arr_2[] = {10, 20, 30, 40, 50};
char arr_21[] = {'H', 'e', 'l', 'l', 'o', '\0'}; // последним должен быть нуль-терминатор, если хотим использовать как строку через указатель
// 3. (Секция данных .bss) Статический локальный массив (инициализируется нулями, а массив char завершающими нуль-терминаторами '\0')
// Сохраняется между вызовами функции
// Этот массив НЕ хранится в стеке.
// Он хранится в сегменте .bss (если нулевой) или .data (если инициализирован).
static double arr_3[10];
// 4. (STACK) Объявление с явным размером (НЕ инициализируется нулями, т.е. содержит мусор)
double arr_4[10];
// 5. (STACK) Инициализация части элементов, остальные равны 0.0
double arr_5[5] = {1.5, 2.5};
char arr_51[6] = {'H', 'e'}; // остальные едементы массива заполнится '\0'
char arr_52[2] = {'H', 'e'}; // В роли массива char можно использовать. В роли строки это ОШИБКА UB, так как нет места для завершающего нуль-терминатора '\0'
double arr_53[5] = {[4] = 3.3};// инициализация не нулем определенного индекса, остальные нулями
int arr_54[5] = { [0 ... 4] = 1 }; // короткий способ
// 6. (VLA) (STACK) Массивы переменной длины (VLA, variable-length arrays). Размер массива определяется значением переменной N во время выполнения (Runtime)
// (НЕ инициализируется нулями, т.е. содержит мусор)
// Это позволяет откладывать установку размера массива перем енной длины до времени выполнения программы.
int n = 20;
char arr_6[n];
// VLAs размещаются в стеке. Они не поддерживаются в C11+ как обязательная функция,
// и их следует избегать на многих встраиваемых системах из-за риска переполнения стека так так пользователь может превысить доступную память стека, что приводит к переполнению стека (Stack Overflow) и аварийному завершению программы..
{
// 7. (HEAP) Динамическое выделение памяти (Куча). Использование malloc
int size = 50;
// Выделение памяти для 50 целых чисел
int *arr_7 = (int*)malloc(size * sizeof(int));
// float *arr_7 = (float*)malloc(size * sizeof(float)); // так для float
if (arr_7 == NULL) {
// Обработка ошибки выделения памяти (память закончилась)
}
// ... Использование arr_7 ...
// ОБЯЗАТЕЛЬНОЕ освобождение памяти
free(arr_7);
}
{
// 8. (HEAP) Динамическое выделение памяти (Куча). Использование calloc
// Выделение и инициализация нулями для 50 целых чисел
int *arr_8 = (int*)calloc(50, sizeof(int));
// float *arr_8 = (float*)calloc(size, sizeof(float)); // так для float
if (arr_8 == NULL) {
// Обработка ошибки выделения памяти (память закончилась)
}
// ... Использование arr_8 ...
// ОБЯЗАТЕЛЬНОЕ освобождение памяти
free(arr_8);
}
return EXIT_SUCCESS;
}
|
|
(VLA, variable-length arrays) (STACK) Массив переменной длины.
Это позволяет откладывать установку размера массива переменной длины до времени выполнения программы.
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
int sum(int n, int arr[n]);// прототип
int sum(int n, int arr[n]){
int total = 0;
for (int i=0;i<5; i++){
total+=arr[i];
}
return total;
}
int main() {
int n = 5;
int arr[n];
for (int i=0;i<5; i++){
arr[i]=1;
}
printf("sum=%d\n", sum(n, arr));// 5
return EXIT_SUCCESS;
}
|
|
Основные операции для работы с массивами
|
#include <stdio.h>
#include <stdlib.h> // malloc, calloc, realloc, free, EXIT_SUCCESS
#define SIZE_ARR 10
int main() {
int arr[SIZE_ARR] = {10, 20, 30, 40, 50};
// 1. Прямой доступ к элементам
arr[0] = 5; // Запись значения
int x = arr[1]; // Чтение значения
// 2. Указатели и адресная арифметика (Имя массива (arr) эквивалентно адресу первого элемента arr[0])
int first = *arr; // разыменование указателя на первый элемент
printf("%d",first); // 5
int *ptr = arr; // или &arr[0] о можно и &arr[2] ... // ptr это переменная указатель на начало массива и как имя массива тоже имеет значение первого элемента т.е. это теперь тоже самое, просто их теперь два на одни и тежи данные !
printf("%d==%d",*ptr, ptr[0]); // 5==5 (разыменование указателя на первый элемент)
*(ptr + 3) = 10; // Запись в arr[3] тут происходит адресная арифметика согласно типу указателя шагаем вправо на 3 размера типа указателя т.е. 4 байта для int это 1 слово. И операция `*` разыменования имеет более высокий приоритет чем `+` поэтому `*ptr + 3 => (*ptr) + 3 => arr[0]+3` это не адресная арифметика, это просто арифметика со значениями
for (size_t i=0; i < SIZE_ARR; i++) {
printf("%d==%d", *(ptr + i), *(arr + i)); // если изначально ptr указывал на arr[0], тогда значения равны будут
}
printf("%d",arr[3]); // 10
int y = ptr[5]; // То же самое, что arr[5]
for (size_t i=0; i < SIZE_ARR; i++) {
printf("%d", ptr[i]);
}
return EXIT_SUCCESS;
}
|
|
Многомерный массив (матрица)
void func(int arr[][5]) // 5 столбцов (колонок)
Компилятору критично знать размер колонок, так как он хранит данные в памяти линейно, то для расчета адреса в двумерном массиве ему нужно знать через сколько колонок перепрыгивать.
|
#include <stdio.h>
#include <stdlib.h> // malloc, calloc, realloc, freem EXIT_SUCCESS
#define NELEMS(array) (sizeof(array) / sizeof(array[0]))
int main() {
// Вариант 1. Статический (Непрерывный) Двумерный Массив (Стек/Глобальная память)
// Размеры всех измерений, кроме первого, должны быть константами (известны на этапе компиляции)
// (Stack) (НЕ инициализируется нулями, т.е. содержит мусор)
int matrix_1[3][4];// из 3 строк и 4 столбцов (колонок)
// (Stack) Размерность можно не указывать, компилятор поймет по данным
int matrix_2[][3] = {
{1, 2, 3},
{4, 5, 6}
};
// ------------------------------------------------------------------------------------------------------------
// Вариант 2. Динамический Двумерный Массив (Куча)
{
int rows = 3;
int cols = 4;
// 1. Выделяем массив указателей на int (rows штук)
int **matrix_ptr = (int**)malloc(rows * sizeof(int*));
// 2. Для каждой строки выделяем память под столбцы
for (int i = 0; i < rows; i++) {
matrix_ptr[i] = (int*)malloc(cols * sizeof(int));
}
// Доступ: matrix_ptr[r][c] = 42;
// 3. ОСВОБОЖДЕНИЕ (в обратном порядке!)
for (int i = 0; i < rows; i++) {
free(matrix_ptr[i]); // Освобождаем каждую строку
}
free(matrix_ptr); // Освобождаем массив указателей
}
// "Псевдо-двумерный" массив (Единый блок)
// Массив создается как единый, непрерывный блок памяти, а затем доступ к нему имитируется с помощью арифметики указателей.
// Этот способ очень эффективен для встраиваемых систем.
// Этот метод требует только один вызов malloc() и один вызов free()
{
int rows = 3;
int cols = 4;
// 1. Выделяем единый блок для всех элементов
int *flat_matrix = (int*)malloc(rows * cols * sizeof(int));
// 2. Доступ к элементу [r][c]
int r = 1, c = 2;
// Формула: flat_matrix[r * cols + c]
flat_matrix[r * cols + c] = 99;
// 3. ОСВОБОЖДЕНИЕ
free(flat_matrix);
}
return EXIT_SUCCESS;
}
|
|
Типы указателей для многомерных массивов
приоритет операции [] выше чем * поэтому при разыменовывании вначале следует получить адрес ячейки массива а потом обращаться по индексы
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define COLS 3
void foo(int ptr[][COLS]); // прототипы вариантов типов параметров
void foo_2(int (*ptr)[COLS]);
void print_matrix(int (*matrix)[COLS], size_t rows) {
for (size_t i = 0; i < rows; i++) {
for (size_t j = 0; j < COLS; j++) {
printf("%d ", matrix[i][j]);
}
printf("\n");
}
}
// Если размер неизвестен на этапе компиляции
void print_dynamic_matrix(int *matrix, size_t rows, size_t cols) {
for (size_t i = 0; i < rows; i++) {
for (size_t j = 0; j < cols; j++) {
printf("%d ", matrix[i * cols + j]); // Рассчитываем индекс
}
printf("\n");
}
}
int main() {
int matrix[][COLS] = {
{1, 2, 3},
{4, 5, 6}
};
int (*ptr_3)[COLS] = matrix; // указательна на весь массив
print_matrix(ptr_3, 2);
print_dynamic_matrix((int*)matrix, 2, COLS);
int (*ptr)[COLS] = &matrix[0]; // указательна на подмассив
// приоритет `[]` выше чем `*`
printf("%d\n", (*ptr)[0]);// 1
printf("%d\n", (*ptr)[1]);// 2
printf("%d\n", (*ptr)[2]);// 3
int (*ptr_2)[COLS] = &matrix[1]; // указательна на подмассив
printf("%d\n", (*ptr_2)[0]);// 4
printf("%d\n", (*ptr_2)[1]);// 5
printf("%d\n", (*ptr_2)[2]);// 6
foo(ptr_2);
foo_2(ptr_2);
return EXIT_SUCCESS;
}
void foo(int ptr[][COLS]){
printf("%d\n", (*ptr)[0]);
printf("%d\n", (*ptr)[1]);
printf("%d\n", (*ptr)[2]);
}
void foo_2(int (*ptr)[COLS]){
printf("%d\n", (*ptr)[0]);
printf("%d\n", (*ptr)[1]);
printf("%d\n", (*ptr)[2]);
}
|
|
Многомерный массив
variant_a:
Ряд 0: 0 0 0 0 0 0 0 0 0
Ряд 1: 1 0 0 0 0 0 0 0 0
Ряд 2: 1 1 0 0 0 0 0 0 0
Ряд 3: 1 1 1 0 0 0 0 0 0
Ряд 4: 1 1 1 1 0 0 0 0 0
Ряд 5: 1 1 1 1 1 0 0 0 0
Ряд 6: 1 1 1 1 1 1 0 0 0
Ряд 7: 1 1 1 1 1 1 1 0 0
Ряд 8: 1 1 1 1 1 1 1 1 0
variant_b:
Ряд 0: 0 1 1 1 1 1 1 1 1
Ряд 1: 0 0 1 1 1 1 1 1 1
Ряд 2: 0 0 0 1 1 1 1 1 1
Ряд 3: 0 0 0 0 1 1 1 1 1
Ряд 4: 0 0 0 0 0 1 1 1 1
Ряд 5: 0 0 0 0 0 0 1 1 1
Ряд 6: 0 0 0 0 0 0 0 1 1
Ряд 7: 0 0 0 0 0 0 0 0 1
Ряд 8: 0 0 0 0 0 0 0 0 0
variant_c:
Ряд 0: 0 0 0 0 0 0 0 0 0
Ряд 1: 1 0 0 0 0 0 0 0 1
Ряд 2: 1 1 0 0 0 0 0 1 1
Ряд 3: 1 1 1 0 0 0 1 1 1
Ряд 4: 1 1 1 1 0 1 1 1 1
Ряд 5: 1 1 1 1 1 1 1 1 1
Ряд 6: 1 1 1 1 1 1 1 1 1
Ряд 7: 1 1 1 1 1 1 1 1 1
Ряд 8: 1 1 1 1 1 1 1 1 1
variant_d:
Ряд 0: 1 1 1 1 1 1 1 1 1
Ряд 1: 1 1 1 1 1 1 1 1 1
Ряд 2: 1 1 1 1 1 1 1 1 1
Ряд 3: 1 1 1 1 1 1 1 1 1
Ряд 4: 1 1 1 1 0 1 1 1 1
Ряд 5: 1 1 1 0 0 0 1 1 1
Ряд 6: 1 1 0 0 0 0 0 1 1
Ряд 7: 1 0 0 0 0 0 0 0 1
Ряд 8: 0 0 0 0 0 0 0 0 0
variant_e:
Ряд 0: 0 0 0 0 0 0 0 0 0
Ряд 1: 1 0 0 0 0 0 0 0 1
Ряд 2: 1 1 0 0 0 0 0 1 1
Ряд 3: 1 1 1 0 0 0 1 1 1
Ряд 4: 1 1 1 1 0 1 1 1 1
Ряд 5: 1 1 1 0 0 0 1 1 1
Ряд 6: 1 1 0 0 0 0 0 1 1
Ряд 7: 1 0 0 0 0 0 0 0 1
Ряд 8: 0 0 0 0 0 0 0 0 0
variant_e:
Ряд 0: 0 1 1 1 1 1 1 1 0
Ряд 1: 0 0 1 1 1 1 1 0 0
Ряд 2: 0 0 0 1 1 1 0 0 0
Ряд 3: 0 0 0 0 1 0 0 0 0
Ряд 4: 0 0 0 0 0 0 0 0 0
Ряд 5: 0 0 0 0 1 0 0 0 0
Ряд 6: 0 0 0 1 1 1 0 0 0
Ряд 7: 0 0 1 1 1 1 1 0 0
Ряд 8: 0 1 1 1 1 1 1 1 0
variant_g:
Ряд 0: 0 1 1 1 1 1 1 1 1
Ряд 1: 0 0 1 1 1 1 1 1 1
Ряд 2: 0 0 0 1 1 1 1 1 1
Ряд 3: 0 0 0 0 1 1 1 1 1
Ряд 4: 0 0 0 0 0 1 1 1 1
Ряд 5: 0 0 0 0 1 1 1 1 1
Ряд 6: 0 0 0 1 1 1 1 1 1
Ряд 7: 0 0 1 1 1 1 1 1 1
Ряд 8: 0 1 1 1 1 1 1 1 1
variant_h:
Ряд 0: 1 1 1 1 1 1 1 1 0
Ряд 1: 1 1 1 1 1 1 1 0 0
Ряд 2: 1 1 1 1 1 1 0 0 0
Ряд 3: 1 1 1 1 1 0 0 0 0
Ряд 4: 1 1 1 1 0 0 0 0 0
Ряд 5: 1 1 1 1 1 0 0 0 0
Ряд 6: 1 1 1 1 1 1 0 0 0
Ряд 7: 1 1 1 1 1 1 1 0 0
Ряд 8: 1 1 1 1 1 1 1 1 0
variant_i:
Ряд 0: 0 0 0 0 0 0 0 0 0
Ряд 1: 0 0 0 0 0 0 0 0 1
Ряд 2: 0 0 0 0 0 0 0 1 1
Ряд 3: 0 0 0 0 0 0 1 1 1
Ряд 4: 0 0 0 0 0 1 1 1 1
Ряд 5: 0 0 0 0 1 1 1 1 1
Ряд 6: 0 0 0 1 1 1 1 1 1
Ряд 7: 0 0 1 1 1 1 1 1 1
Ряд 8: 0 1 1 1 1 1 1 1 1
variant_j:
Ряд 0: 1 1 1 1 1 1 1 1 1
Ряд 1: 1 1 1 1 1 1 1 1 0
Ряд 2: 1 1 1 1 1 1 1 0 0
Ряд 3: 1 1 1 1 1 1 0 0 0
Ряд 4: 1 1 1 1 1 0 0 0 0
Ряд 5: 1 1 1 1 0 0 0 0 0
Ряд 6: 1 1 1 0 0 0 0 0 0
Ряд 7: 1 1 0 0 0 0 0 0 0
Ряд 8: 1 0 0 0 0 0 0 0 0
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define COLS 9
void variant_a(int (*arr)[COLS], size_t n ){
printf("variant_a:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j>=i) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_b(int (*arr)[COLS], size_t n ){
printf("variant_b:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j<=i) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_c(int (*arr)[COLS], size_t n ){
printf("variant_c:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j>=i && j<n-i && i<=n/2) printf("0 ");
else printf("%d ", arr[i][j]);
//или так
//if(j>=i && j<n-i) printf("0 ");
//else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_d(int (*arr)[COLS], size_t n ){
printf("variant_d:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j<=i && j>=n-i-1 && i>=n/2) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_e(int (*arr)[COLS], size_t n ){
printf("variant_e:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if((j>=i && j<n-i && i<=n/2 )||( j<=i && j>=n-i-1 && i>=n/2)) printf("0 ");
else printf("%d ", arr[i][j]);
//или так
//if((j>=i && j<n-i)||( j<=i && j>=n-i-1)) printf("0 ");
//else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_f(int (*arr)[COLS], size_t n ){
printf("variant_e:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(((j<n-i && i>=n/2) || (j<=i && i<=n/2)) || ((j>=i && i>=n/2) || (j>=n-i-1 && i<=n/2)) ) printf("0 ");
else printf("%d ", arr[i][j]);
//или так
//if((j<=i && j<n-i) ||( j>=i && j>=n-i-1)) printf("0 ");
//else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_g(int (*arr)[COLS], size_t n ){
printf("variant_g:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if((j<n-i && i>=n/2) || (j<=i && i<=n/2)) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_h(int (*arr)[COLS], size_t n ){
printf("variant_h:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if((j>=i && i>=n/2) || (j>=n-i-1 && i<=n/2)) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_i(int (*arr)[COLS], size_t n ){
printf("variant_i:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j<n-i ) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void variant_j(int (*arr)[COLS], size_t n ){
printf("variant_j:\n");
for (size_t i=0; i < n; i++){
printf("Ряд %ld: ",i);
for (size_t j=0; j < COLS; j++){
if(j>=n-i ) printf("0 ");
else printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
}
void fill_out(int (*arr)[COLS], size_t n, int fill){
for (size_t i=0; i < n; i++){
for (size_t j=0; j < COLS; j++){
arr[i][j]=fill;//rand()%10-5;// от -5 до +5
}
}
}
int main(void) {
// Задача из 7 урока по С на массивы
const size_t n=9;
int arr[n][COLS];
fill_out(arr, n, 1);
variant_a(arr, n);
variant_b(arr, n);
variant_c(arr, n);
variant_d(arr, n);
variant_e(arr, n);
variant_f(arr, n);
variant_g(arr, n);
variant_h(arr, n);
variant_i(arr, n);
variant_j(arr, n);
return EXIT_SUCCESS;
}
|
|
Двойной указатель int **ptr — указатель на указатели, для массивов указателей
|
Например, если вводить в scanf("%s",name); предложение разделенное пробелом либо табуляцией то все что идет после не попадет в переменную. И scanf считывает только нужные ему символы, но оставляет символ новой строки (\n) в буфере ввода, поэтому следующий вызов scanf не будет работать так как буфер обмена уже содержит символ новой строки (\n), к тому же если предыдущий ввод содержал пробел то весь текст после пробела перейдет на обработку к следующему scanf.
Если вначале строки есть пробелы, то они будут пропущены и взято первое слово.
Это не рабочий вариант считывания scanf, весь ввод после пробела останется в буфере обмена и мешая следующему scanf
А getchar() только последний символ удаляет из буфера, а не оставшуюся строку
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <stddef.h> // NULL
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME]={};
printf("Полное имя:");
scanf("%s",name);
printf("%s\n", name);// Мария
getchar(); // Считывает и отбрасывает оставшийся '\n' с буфера
return EXIT_SUCCESS;
}
Рабочий вариант считывания всего ввода c ограничением длины и освобождением буфера от переноса строки
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME]={};
char fmt[20];
sprintf(fmt, "%%%d[^\n]", LENGTH_NAME - 1);// Формируем формат строки: "%39[^\n]"
printf("Полное имя:");
scanf(fmt, name); // Считывает до 39 символов, пока не встретит '\n'
printf("%s\n", name);
getchar(); // Считывает и отбрасывает оставшийся '\n' с буфера
return EXIT_SUCCESS;
}
Еще лучше вариант считывания всего ввода c ограничением длины, fgets сам очистит буфер
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <string.h> // для strlen
#define LENGTH_NAME 40
int main(void) {
// Ввод:Мария Иванова
char name[LENGTH_NAME];
printf("Полное имя: ");
// Считывает строку, включая пробелы и '\n', безопасно.
if (fgets(name, LENGTH_NAME, stdin) != NULL) {
// Удаляем '\n', который был добавлен функцией fgets
size_t len = strlen(name);
if (len > 0 && name[len - 1] == '\n') {
name[len - 1] = '\0';
}
printf("%s\n", name);
}
// Буфер ввода stdin уже чист!
return EXIT_SUCCESS;
}
|
|
Использование gdb и анализ памяти исполняемого файла
Дебаггинг (отладка)
-
quit - выйти из отладчика GDB
-
run - запуск отладчика GDB
-
kill - остановить программу
-
break main - установить контрольную точку на входе в функцию main
-
break *0x400540 - установить контрольную точку на инструкцию с адресом
-
delete 1 - удалить контрольную точку
-
delete - удалить все контрольные точки
-
stepi - выполнить одну инструкцию
-
stepi 4 - выполнить 4 инструкции
-
nexti - действует подобно stepi, но не входит в функцию
-
continue - возобновить выполнение
-
finish - продолжить выполнение инструкций до конца текущей функции
-
disas - дизассемблировать текущую функцию
-
disas main - дизассемблировать main функцию
-
disas 0x400540 - дизассемблировать функцию включающую адрес
-
disas 0x400540, 0x40054d - дизассемблировать код между адресами
-
print /x $rip - вывести значение счетчика инструкции в шестнадцатеричном виде
-
print $rax - Вывести содержимое %rax в десятичном виде
-
print /x $rax - Вывести содержимое %rax в шестнадцатеричном виде
-
print /t $rax - Вывести содержимое %rax в двоичном виде
-
print 0x100 - Вывести 0x100 в десятичном представлении
-
print /x 555 - Вывести 555 в шестнадцатеричном представлении
-
print /x ($rsp+8) - Вывести содержимое ячейки памяти с адресом (%rsp+8)
-
print *(long *) 0x7fffffffe818 - Вывести длинное целое, хранящееся в памяти с адресом 0x7fffffffe818
-
print *(long *) ($rsp+8) - Вывести длинное целое, хранящееся в памяти с адресом (%rsp+8)
-
x/2g 0x7fffffffe818 - Вывести два (8-байтных) слова, хранящихся в памяти, начиная с адреса 0x7fffffffe818
-
x/20b main - Вывести первые 20 байт функции main
-
info frame - Вывести информацию о текущем кадре стека
-
info registers - Вывести значения всех регистров
-
help - Вывести справочную информацию о GDB
|
Как найти точку/адрес/строку для установки breakpoint:
1. Самый простой
(gdb) break main
2. Сразу на строку в файле struct.c
(gdb) break struct.c:49
3. Найти адрес функции и перейти по нему
(gdb) info line main
Line 46 of "struct.c" starts at address 0x555555555189 <main> and ends at 0x555555555195 <main+12>.
(gdb) break *0x555555555189
4. Найти адрес строки:
(gdb) info line file.c:123
Line 123 of "file.c" starts at address 0x4006a7 and ends at 0x4006b2
(gdb) break *0x4006a7
5. Можно сразу узнать адресс нужной инструкции чтобы потом установить на нее точку останова
# начнем с адреса 0x7c00
(gdb) b *0x7c00
Breakpoint 1 at 0x7c00
(gdb) c
Continuing.
Breakpoint 1, 0x00007c00 in ?? ()
# посмотрим нужный нам адрес инструкции
(gdb) x /50i $pc
(gdb)
Пример
#include <stdio.h>
#include <stdlib.h> // malloc, calloc, realloc, free
#define NELEMS(array) (sizeof(array) / sizeof(array[0]))
// 1. (Секция данных) Глобальный массив (инициализируется нулями)
double arr_1[256];
int main(void) {
printf("%lf",arr_1[0]);
// 4. (STACK) Объявление с явным размером (НЕ инициализируется нулями)
double arr_4[1024];
printf("%lf",arr_4[0]);
{
// 7. (HEAP) Динамическое выделение памяти (Куча). Использование malloc
int size = 50;
// Выделение памяти для 50 целых чисел
int *arr_7 = (int*)malloc(size * sizeof(int));
// float *arr_7 = (float*)malloc(size * sizeof(float)); // так для float
if (arr_7 == NULL) {
// Обработка ошибки выделения памяти (память закончилась)
}
// ... Использование arr_7 ...
// ОБЯЗАТЕЛЬНОЕ освобождение памяти
printf("%d\n",arr_7[0]);
int n = 0;
scanf("%d",&n);
free(arr_7);
}
// gcc -g array.c -o my_program_g.out <---------------- компиляция с информацией для дебаггинга
// gdb ./my_program_g.out
// (gdb) b main <------------------------------------- установить точку останова в main
// Breakpoint 1 at 0x11ed: file array.c, line 8.
// r <------------------------------------- запускаем программу
// Starting program: /home/jeka/Projects/C/HelloWorld/my_program_g.out
// [Thread debugging using libthread_db enabled]
// Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
//
// Breakpoint 1, main () at array.c:8
// warning: Source file is more recent than executable.
// 8 int main(void) {
//
// (gdb) p &arr_4 <--------------------------------------- это инф. про данные на Stack, команда p - print
// $1 = (double (*)[1024]) 0x7fffffffbac0
//
// (gdb) p &arr_1 <--------------------------------------- это инф. про данные секции Data/Static
// $2 = (double (*)[256]) 0x555555558040 <arr_1>
//
// ((gdb) x/5fg arr_1 <----------------------------------- просмотреть первые 5 элементов в вещественном (а) формате, размером 8 байта (g)
// 0x555555558040 <arr_1>: 0 0
// 0x555555558050 <arr_1+16>: 0 0
// 0x555555558060 <arr_1+32>: 0
//
// (gdb) p arr_1[3] <----------------------------------- просмотреть значение
// $5 = 0
//
// (gdb) b 20 <--------------------------------------- установил еще точку останова в строке 26 (почему не 20?)
// Breakpoint 2 at 0x555555555261: file array.c, line 26.
//
// c <--------------------------------------- continue продолжить до следующей точки останова (или много раз n - next)
// Continuing.
//
// Breakpoint 2, main () at array.c:26
// 26 printf("%d\n",arr_7[0]);
//
// (gdb) p arr_7 <--------------------------------------- это инф. про данные в HEAP. Без амперсанда так как arr_7 и так указатель (адрес)
// $3 = (int *) 0x5555555596b0
//
// (gdb) x/10dw arr_7 <----------------------------------- просмотреть первые 10 элементов в десятичном (d) формате, размером 4 байта (w)
// 0x5555555596b0: 0 0 0 0
// 0x5555555596c0: 0 0 0 0
// 0x5555555596d0: 0 0
//
// (gdb) p size <----------------------------------- просмотреть значение переменной size
// $4 = 50
//
/*
(gdb) info proc mappings <----------------------------------- просмотр карты памяти текущего процесса my_program_g.out
process 188654
Mapped address spaces:
Start Addr End Addr Size Offset Perms objfile
0x555555554000 0x555555555000 0x1000 0x0 r--p /home/jeka/Projects/C/HelloWorld/my_program_g.out
0x555555555000 0x555555556000 0x1000 0x1000 r-xp /home/jeka/Projects/C/HelloWorld/my_program_g.out
0x555555556000 0x555555557000 0x1000 0x2000 r--p /home/jeka/Projects/C/HelloWorld/my_program_g.out
0x555555557000 0x555555558000 0x1000 0x2000 r--p /home/jeka/Projects/C/HelloWorld/my_program_g.out
0x555555558000 0x555555559000 0x1000 0x3000 rw-p /home/jeka/Projects/C/HelloWorld/my_program_g.out
0x555555559000 0x55555557a000 0x21000 0x0 rw-p [heap]
0x7ffff7c00000 0x7ffff7c28000 0x28000 0x0 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7c28000 0x7ffff7db0000 0x188000 0x28000 r-xp /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7db0000 0x7ffff7dff000 0x4f000 0x1b0000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7dff000 0x7ffff7e03000 0x4000 0x1fe000 r--p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e03000 0x7ffff7e05000 0x2000 0x202000 rw-p /usr/lib/x86_64-linux-gnu/libc.so.6
0x7ffff7e05000 0x7ffff7e12000 0xd000 0x0 rw-p
0x7ffff7fa2000 0x7ffff7fa5000 0x3000 0x0 rw-p
0x7ffff7fbd000 0x7ffff7fbf000 0x2000 0x0 rw-p
0x7ffff7fbf000 0x7ffff7fc1000 0x2000 0x0 r--p [vvar]
0x7ffff7fc1000 0x7ffff7fc3000 0x2000 0x0 r--p [vvar_vclock]
0x7ffff7fc3000 0x7ffff7fc5000 0x2000 0x0 r-xp [vdso]
0x7ffff7fc5000 0x7ffff7fc6000 0x1000 0x0 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7fc6000 0x7ffff7ff1000 0x2b000 0x1000 r-xp /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ff1000 0x7ffff7ffb000 0xa000 0x2c000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
--Type <RET> for more, q to quit, c to continue without paging--c
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 0x36000 r--p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffff7ffd000 0x7ffff7fff000 0x2000 0x38000 rw-p /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
0x7ffffffdd000 0x7ffffffff000 0x22000 0x0 rw-p [stack]
0xffffffffff600000 0xffffffffff601000 0x1000 0x0 --xp [vsyscall]
q <----------------------------------- Exit
*/
/*
Анализ памяти:
Куча (Heap)
(0x555555559000 0x55555557a000 0x21000 0x0 rw-p [heap])
Диапазон: 0x555555559000 до 0x55555557a000
Размер: 0x21000 (в шестнадцатеричной системе). Это 21*4096 байт = 136 КБ
Смысл: Это память, которую ваша программа выделила динамически (через malloc, calloc и т.д.) или которую зарезервировал загрузчик.
Секция данных (Data Section)
(0x555555558000 0x555555559000 0x1000 0x3000 rw-p /home/jeka/Projects/C/HelloWorld/my_program_g.out)
(как найти) Принадлежность: Должна ссылаться на ваш исполняемый файл: /home/jeka/Projects/C/HelloWorld/my_program_g.out
(как найти) Находится среди других сегментов вашего исполняемого файла (в нижних адресах т.е. от смещения где то рядом и точно до heap и уж точно до stack)
(как найти) Разрешение (rw-p): Должна иметь разрешение на запись ($\mathbf{w}$), поскольку данные в ней изменяются во время выполнения.
Диапазон: 0x555555558000 до 0x555555559000
Размер: 0x1000 (4 КБ)
Perms (rw-p): Разрешения на чтение и запись (R/W), что типично для данных, которые могут изменяться (глобальные переменные, статические массивы, как ваш arr_1 и arr_3).
Стек (Stack)
(как найти) Находится в высоких адресах т.е. внизу далеко от начала смещения (0x7ffffffdd000 0x7ffffffff000 0x22000 0x0 rw-p [stack])
Диапазон: 0x7ffffffdd000 до 0x7ffffffff000
Размер: 0x22000 (136 КБ)
Смысл: Это память, выделенная для локальных переменных, автоматических массивов (как ваш arr_4 или arr_6) и информации о вызовах функций. Адреса в стеке всегда очень высокие.
Код Программы и Библиотеки
Код (r-xp): Строка 0x555555555000 с разрешением r-xp (чтение, выполнение, нет записи) содержит исполняемый код вашей программы.
Библиотеки (libc.so.6): Большинство остальных строк относятся к разделяемым библиотекам (например, стандартной библиотеке C, libc), которые также отображаются в адресном пространстве вашего процесса.
*/
/*
Использования инструмента анализа памяти /proc/PID/maps (Linux)
Шаг 1: Запуск программы в фоновом режиме
./my_program_g.out & <----------------------------------------- запуск программы в фоновом режиме
[1] 199197 <----------------------------------------- это PID
0.0000000.0000000
[1]+ Stopped ./my_program_g.out
Шаг 2: Просмотр файла Maps
cat /proc/199197/maps
6451161f3000-6451161f4000 r--p 00000000 103:02 25561662 /home/jeka/Projects/C/HelloWorld/my_program_g.out
6451161f4000-6451161f5000 r-xp 00001000 103:02 25561662 /home/jeka/Projects/C/HelloWorld/my_program_g.out
6451161f5000-6451161f6000 r--p 00002000 103:02 25561662 /home/jeka/Projects/C/HelloWorld/my_program_g.out
6451161f6000-6451161f7000 r--p 00002000 103:02 25561662 /home/jeka/Projects/C/HelloWorld/my_program_g.out
6451161f7000-6451161f8000 rw-p 00003000 103:02 25561662 /home/jeka/Projects/C/HelloWorld/my_program_g.out
645126c4b000-645126c6c000 rw-p 00000000 00:00 0 [heap]
72677a000000-72677a028000 r--p 00000000 103:02 1838838 /usr/lib/x86_64-linux-gnu/libc.so.6
72677a028000-72677a1b0000 r-xp 00028000 103:02 1838838 /usr/lib/x86_64-linux-gnu/libc.so.6
72677a1b0000-72677a1ff000 r--p 001b0000 103:02 1838838 /usr/lib/x86_64-linux-gnu/libc.so.6
72677a1ff000-72677a203000 r--p 001fe000 103:02 1838838 /usr/lib/x86_64-linux-gnu/libc.so.6
72677a203000-72677a205000 rw-p 00202000 103:02 1838838 /usr/lib/x86_64-linux-gnu/libc.so.6
72677a205000-72677a212000 rw-p 00000000 00:00 0
72677a287000-72677a28a000 rw-p 00000000 00:00 0
72677a2a2000-72677a2a4000 rw-p 00000000 00:00 0
72677a2a4000-72677a2a6000 r--p 00000000 00:00 0 [vvar]
72677a2a6000-72677a2a8000 r--p 00000000 00:00 0 [vvar_vclock]
72677a2a8000-72677a2aa000 r-xp 00000000 00:00 0 [vdso]
72677a2aa000-72677a2ab000 r--p 00000000 103:02 1838835 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
72677a2ab000-72677a2d6000 r-xp 00001000 103:02 1838835 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
72677a2d6000-72677a2e0000 r--p 0002c000 103:02 1838835 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
72677a2e0000-72677a2e2000 r--p 00036000 103:02 1838835 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
72677a2e2000-72677a2e4000 rw-p 00038000 103:02 1838835 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffed3625000-7ffed3646000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
Шаг 3: Анализ вывода
Все адреса в таблице указаны в шестнадцатеричной системе. Размер сегмента (в колонке Size) также указан в шестнадцатеричной системе, где 0x1000 равно 4096 байт или 4 КБ.
Куча (Heap)
Идентификатор: Строка, помеченная как [heap]
Диапазон: 645126c4b000 до $645126c6c000
Размер (Size): 0x21000
0x21000 в десятичной системе равно 135168 байт (132 КБ)
Стек (Stack)
Идентификатор: Строка, помеченная как [stack]
Диапазон: 7ffed3625000 до 7ffed3646000
Размер (Size): 0x21000
0x21000 в десятичной системе равно 135168 байт (132 КБ)
Секция данных (Data Section / Статическая память)
Статические/глобальные данные хранятся в сегментах вашего исполняемого файла, которые имеют разрешения на запись (rw-p)
Идентификатор: Строка, связанная с my_program_g.out с разрешением rw-p
Диапазон: 6451161f7000 до 6451161f8000
Размер (Size): 0x1000 (4 КБ)
Код (Text) и Только для Чтения (Read-Only)
Код (Text): Строка 6451161f4000 с разрешением r-xp (чтение/выполнение). Это исполняемый код вашей программы. Размер: 4 КБ
Только для чтения (Read-Only Data): Строки с r--p (например, 6451161f3000 и 6451161f5000), которые содержат константы и метаданные.
Ваша программа использует:
Куча: 132 КБ
Стек: 132 КБ
Секция данных (R/W): 4 КБ
*/
/*
Проверка программы в фоне:
ps -p 199197 <------------------------------------ запуск сканирования PID
PID TTY TIME CMD <------------------------------------ есть инф. значит работает
199197 pts/3 00:00:00 my_program_g.ou
kill -9 199197 <------------------------------------ принудительно завершить PID
[1]+ Killed ./my_program_g.out
*/
/*
Как вычислить размер области, например для метки [stack]:
"7ffed3625000-7ffed3646000 rw-p 00000000 00:00 0 [stack]"
Разница между начальным адресом 7ffed3646000 и конечным 7ffed3625000, это число 0x21000 в 16-ричном виде, переводим в 10-ое = 135168 Байт = 135168/1024 = 132 КБ
Если можем 16-ричные числа отнимать:
7ffed3646000 - 7ffed3625000 = 0x21000
Но можно сразу 16-ричные перевести в 10-ричные и их отнять
7ffed3646000=140732444991488
7ffed3625000=140732444856320
140732444991488−140732444856320=135168 Байт = 135168/1024 = 132 КБ
*/
return 0;
}
|
|
Размер статического массива
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define NELEMS(array) (sizeof(array) / sizeof(array[0]))
int main(){
char arr[5];// 0,0,0,0,0
size_t array_length = NELEMS(arr);
printf("Length=%ld\n", array_length); // 5
for (size_t i=0; i < array_length; i++) {
printf("%d",arr[i]);
}
return EXIT_SUCCESS;
}
|
|
Передача массива в функцию
|
Массив всегда передается в функцию как указатель на первый элемент, по значению передать нет возможности
хотя язык позволяет так int sum(int arr[SIZE_ARR], size_t size){... но компилятор преобразует int arr[SIZE_ARR] в указатель int *ptr а по указателю узнать размер массива не получится поэтому надо передавать еще и размер массива, и тогда это бессмысленная конструкция
По умолчанию указатель может мутировать данные, для запрета изменения применяют const * ptr
Вместо размера массива можно передать указатель на начало и конец, и в каждой итерации сравнивать не превысили ли мы адрес конечного элемента while (start < end){....
Стандарт C разрешает указатель на элемент после конца int *end = start + 5; для выполнения сравнений для простоты
Арифметика с указателями позволяет вычитать указатели если они указывают на один массив, чтобы
определить, насколько далеко они отстоят друг от друга, результат того же типа что и данные т.е. это не указатель.
Если вычесть/прибавить из указателя int то результат будет указатель.
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#define SIZE_ARR 12
int sum(int arr[], size_t n); // так можно обьявить прототип, явно указывая что указатель указывает на массив
int sum(int [], size_t);// или так, можно не указывать имена
int sum(int *, size_t);// или так
int sum(int *arr, size_t n){
// тут arr это указатель при чем локалтный указатель с другим адресом но ссылается на тот же массив
// изменение локального указателя не влияет на оригинальный, т.е. то что мы `arr++` не изменит позицию оригинала, массив изменит
int total = 0;
for (size_t i = 0; i < n; i++)
total += arr[i];
return total;
}
int main() {
int days [SIZE_ARR] = {31, 28, 31,30, 31, 30, 31, 31,30, 31,30, 31};
printf("total=%d\n", sum(days, SIZE_ARR));
int *ptr = days;// &days[0];
printf("total=%d\n", sum(ptr, SIZE_ARR));
return EXIT_SUCCESS;
}
|
|
Методы для работы с массивом
- memset - заполнения массива указанными символами
- memmove - копирование массивов (в том числе пересекающихся)
- memcpy - копирование непересекающихся массивов
- strcpy - копирование символьных массивов
- strncpy - копирование символьных массивов огр. длины
- memccpy - Копирование непересекающихся массивов до символа
- memcmp - сравнение массивов
- memchr - поиск первого вхождения указанного символа в массиве
- qsort - сортирует масси
- bsearch - бинарный поиск
|
В языке C, включая стандарт C99, массивы, по сути, не имеют "методов" в том смысле, как это понимается в объектно-ориентированных языках (вроде C++ или Java).
Массивы в C — это статическая структура данных с очень простым набором операций.
Вместо методов, работа с массивами сводится к доступу через индексы, использованию указателей и стандартным функциям из библиотеки string.h и stdlib.h
Методы:
memset - Заполнения массива указанными символами
void *memset (void *destination, int c, size_t n);
memmove и memcpy
Копирует произвольные блоки памяти, не заботясь о содержимом.
Используется для любых данных: массивы, структуры, бинарные буферы.
- memmove - копирование массивов (в том числе пересекающихся)
- void *memmove (void *destination, const void *source, size_t n);
- где n — количество байт, а не элементов!
- memcpy - копирование непересекающихся массивов
- void *memcpy(void * restrict s1, const void * restrict s2, size_t n)
- где n — количество байт, а не элементов!
strcpy() и strncpy() - Копирование символьных массивов (memcpy и memmove не добавляют '\0' автоматически в строку)
memccpy - Копирование непересекающихся массивов до символа
void *memccpy (void *destination, const void *source, int c, size_t n);
memcmp - Сравнение массивов
memcmp (const void *arr1, const void *arr2, size_t n);
memchr - Поиск первого вхождения указанного символа в массиве
void *memchr (const void *arr, int c, size_t n);
qsort - Сортирует массив, используя алгоритм быстрой сортировки (quicksort). Требует функции сравнения, которую вы определяете сами. Из библиотеки stdlib.h
bsearch - Бинарный поиск: Эффективный поиск элемента в уже отсортированном массиве.
Пример:
#include <stdio.h> //Для printf
#include <string.h> //Для memset, memcpy, memmove
#include <stdlib.h> // EXIT_SUCCESS, qsort, bsearch
int main (){
//заполнения массива указанными символами
unsigned char src_char[15]="1234567890";
// Заполняем массив символом '1'
memset (src_char, '1', 10);// '1' или 49 код
// Вывод массива src на консоль
printf ("src_char: %s\n",src_char);
//сравнение массивов
unsigned char src[15]="123456789W";
unsigned char dst[5]="6789R";
// сравним участок от &src[5] с участком dst размером в 4 байта т.е. 6789==6789
if (memcmp (&src[5], dst, 4) == 0)
puts ("Области памяти идентичные.");
else
puts ("Области памяти отличаются.");
//поиск первого вхождения указанного символа в массиве
unsigned char src[15]="123456789W";
char *sym = (char*)memchr (src, '4', 10);
printf ("sym: %s\n",sym);// 456789W
return EXIT_SUCCESS;
}
|
|
Примитивная реализцация memset
|
/* memset: заполняет n байт по адресу s равными c */
void *memset(void *s, int с, size_t n)
{
size_t i;
char *p;
p = (char *) s;
for (i = 0; i < n; i++)
p[i] = C;
return s;
}
Но если соображения быстродействия играют решающую роль, то используются такие приемы, как запись целых 32- или 64-разрядных слов.
|
|
memmove и memcpy
Копирует произвольные блоки памяти, не заботясь о содержимом.
Используется для любых данных: массивы, структуры, бинарные буферы.
- memmove - копирование массивов (в том числе пересекающихся)
- void *memmove (void *destination, const void *source, size_t n);
- где n — количество байт, а не элементов!
- memcpy - копирование непересекающихся массивов
- void *memcpy(void * restrict s1, const void * restrict s2, size_t n)
- где n — количество байт, а не элементов!
|
#include <stdio.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
unsigned char source[10] = {1,2,3,4,5,6,7,8,9,10};
unsigned char dest[10];
// memcpy — копируем весь массив (не пересекается)
memcpy(dest, source, sizeof(source)); // или memcpy(dest, source, 10 * sizeof(unsigned char));
// memmove — безопасно при пересечении
memmove(&source[2], &source[0], 5); // сдвигаем первые 5 байт на 2 позиции
// выводим массив для проверки
for (int i = 0; i < 10; i++)
printf("%d ", source[i]);
printf("\n");
return EXIT_SUCCESS;
}
|
|
strcpy() и strncpy()
Копирование символьных массивов (memcpy и memmove не добавляют '\0' автоматически в строку)
|
#include <stdio.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char source[15] = "1234567890";
char buff[5]; // буфер на 4 символа + '\0'
// копируем 4 символа из source[3..6] в buff
strncpy(buff, &source[3], 4);
buff[4] = '\0'; // обязательно добавляем конец строки
printf("buff: %s\n", buff); // 4567
// копирование последних 3 символов source[7..9] в начало source
// используем временный буфер для безопасности
char tmp[4];
strncpy(tmp, &source[7], 3);
tmp[3] = '\0';
strncpy(&source[0], tmp, 3);
source[3] = '\0'; // обрезаем исходную строку для корректного вывода
printf("source: %s\n", source); // 890
return EXIT_SUCCESS;
}
Вариант с memmove и memcpy должен учитывать '\0'
#include <stdio.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS
int main(void) {
char source[15] = "1234567890";
char buff[5]; // буфер на 4 символа + '\0'
// копируем 4 символа из source[3..6] в buff
memmove(buff, &source[3], 4);
buff[4] = '\0'; // ОБЯЗАТЕЛЬНО добавляем нуль
printf("buff: %s\n", buff); // 4567
// сдвигаем последние 3 символа source[7..9] в начало source
memmove(&source[0], &source[7], 3);
source[3] = '\0'; // нуль для корректной строки
printf("source: %s\n", source); // 890
return EXIT_SUCCESS;
}
|
|
qsort Сортирует массив, используя алгоритм быстрой сортировки (quicksort). Требует функции сравнения, которую вы определяете сами. Из библиотеки stdlib.h
bsearch Бинарный поиск: Эффективный поиск элемента в уже отсортированном массиве.
|
qsort
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, qsort, bsearch
int cmp_int(const void *a, const void *b) {
int x = *(const int*)a;
int y = *(const int*)b;
return (x > y) - (x < y);
}
int main(void) {
int arr[] = {5, 1, 9, 3, 2};
size_t n = sizeof(arr) / sizeof(arr[0]);
qsort(arr, n, sizeof(int), cmp_int);
for (size_t i = 0; i < n; i++)
printf("%d ", arr[i]);
return EXIT_SUCCESS;
}
bsearch
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, qsort, bsearch
int cmp_int(const void *a, const void *b) {
int x = *(const int*)a;
int y = *(const int*)b;
return (x > y) - (x < y);
}
int main(void) {
int arr[] = {1, 2, 3, 5, 9};
size_t n = sizeof(arr) / sizeof(arr[0]);
int key = 3;
int *found = bsearch(&key, arr, n, sizeof(int), cmp_int);
if (found) {
printf("Found %d at index %ld\n", key, found - arr);
} else {
printf("%d not found\n", key);
}
return EXIT_SUCCESS;
}
|
|
|
// test.с
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
typedef struct {
int *data;
size_t size;
size_t capacity;
} DynArray;
void init_array(DynArray *arr) {
arr->data = NULL;
arr->size = 0;
arr->capacity = 0;
}
void push_back(DynArray *arr, int value) {
if (arr->size >= arr->capacity) {
size_t new_capacity = arr->capacity ? arr->capacity * 2 : 2;
int *new_data = realloc(arr->data, new_capacity * sizeof(int));
if (!new_data) {
perror("realloc failed");
exit(EXIT_FAILURE);
}
arr->data = new_data;
arr->capacity = new_capacity;
}
arr->data[arr->size++] = value;
}
void free_array(DynArray *arr) {
free(arr->data);
arr->data = NULL;
arr->size = arr->capacity = 0;
}
int main(void) {
DynArray arr;
init_array(&arr);
for (int i = 0; i < 10; i++) {
push_back(&arr, i * 10);
printf("Добавлено %d (size=%zu, capacity=%zu)\n",
arr.data[arr.size - 1], arr.size, arr.capacity);
}
printf("\nВсе элементы:\n");
for (size_t i = 0; i < arr.size; i++) {
printf("%d ", arr.data[i]);
}
printf("\n");
free_array(&arr);
return EXIT_SUCCESS;
}
|
|
Динамический массив расположен в HEAP пока его память не освободят
т.е. он будет жить и дальше до конца программы если потерять указатель на него
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
// Функция создает массив и возвращает указатель
int* create_array(int size) {
int *arr = malloc(size * sizeof(int));
for (int i = 0; i < size; i++) {
arr[i] = i * 10; // Заполняем данными
}
return arr; // Возвращаем указатель на память в куче
}
// Другая функция работает с массивом
void print_array(int *arr, int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main() {
// Создаем массив в функции
int *my_array = create_array(5);
// Используем в разных местах
print_array(my_array, 5); // 0 10 20 30 40
// Модифицируем
my_array[2] = 999;
print_array(my_array, 5); // 0 10 999 30 40
// Когда больше не нужен - освобождаем
free(my_array); // ✅ Память освобождена
return EXIT_SUCCESS;
}
|
|
|
|
|
|
Указатель — это переменная (или в общем случае объект данных), значением которой является адрес в памяти.
Программисты на С создают массивы указателей, указатели на функции, массивы указателей на указатели, массивы указателей на функции и т.п.
|
|
Не разыменовывайте неинициализированный указатель
|
Создание указателя приводит к выделению памяти только под сам указатель; для хранения данных память не выделяется.
Таким образом, перед использованием указателю должен быть присвоен адрес ячейки памяти, которая уже была выделена заранее.
#include <stdio.h>
int main() {
int * ptr; // неинициализированный указатель
*ptr = 5 ; // катастрофическая ошибка! ptr, будучи неинициализированным, имеет случайное значение, поэтому неизвестно, куда будет помещено 5. Это может не причинить вреда, перезаписать данные или код либо вызвать аварийное завершение программы
return 0;
}
Например, указателю можно присвоить адрес существующей переменной либо же можно воспользоваться функцией malloc()
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Висячие указатели:
int *dangling() {
int x = 5;
return &x; // ❌ Указатель на умершую переменную стека
// Error: function returns address of local variable [-Werror=return-local-addr]
}
int main(void) {
int *x = dangling();
printf("x = %d \n", *x); // 10
return EXIT_SUCCESS;
}
|
|
Мутация (изменение) данных
Сам указатель передается по значению, он содержит просто адрес, его можно поменять на другой адрес и это ни как на данные не влияет.
Правило "чтения справа налево"
- Звездочка * относится к имени переменной, а не к типу! т.е.
int *ptr;, а не int* ptr
- Самый надежный способ — читать объявление справа налево от имени переменной.
Например:
int* const n;
Читаем справа налево:
n — переменная
const — константная
* — указатель
int — на целое число
Итог: n — это константный указатель на int (указатель зафиксирован, но данные можно менять)
Можно менять и данные и указатель:
Можно менять данные, но не указатель:
Можно менять указатель, но не данные:
Не можем менять ни указатель ни данные:
void foo(int const *const n);
|
Для мутации данных передавайте их по указателю
static хранит память между вызовами
Для запрета мутации (imutable) используйте const указатель
void foo(const int *n){... может принять как обычный так и константный указатель, а вот обычный указатель не может принять константный
int x = 1;
const int *ptr = &x;
*ptr = 2; // Error read-only
Пример:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void foo(int *n){
static int total = 0;
total+=*n;
*n = total;
}
int global_value = 123;
void foo_const_value(int const *n){
n=&global_value;// поменять значение самого указателя на новый адрес мы можем, но это ни как не влияет на его первоначальные данные
//*n=8; Error менять значение по адресу на который указывает указатель мы не можем
printf("foo_const_value:%d\n",*n);// 123
}
void foo_const_ptr(int *const n){
// n=&global_value; Error менять адрес указатель мы не можем
*n=8; // менять значение по адресу на который указывает указатель мы можем
printf("foo_const_ptr:%d\n",*n);// 8
}
void foo_const_ptr_and_value(int const *const n){
//n=&global_value; Error менять адрес указатель мы не можем
//*n=8; Error менять значение по адресу на который указывает указатель мы не можем
printf("foo_const_ptr_and_value:%d\n",*n);// 8
}
int main(void) {
int x = 1;
foo(&x);
printf("%d\n", x);// 1
foo(&x);
printf("%d\n", x);// 2
printf("%d\n", x);// 2
foo_const_value(&x);// 123
printf("%d\n", x);// 2
foo_const_ptr(&x);// 8
printf("%d\n", x);// 8
foo_const_ptr_and_value(&x);// 8
return EXIT_SUCCESS;
}
int x = 10, y = 20;
const int *ptr1 = &x; // Указатель на константу
// *ptr1 = 15; // ОШИБКА: нельзя менять значение
ptr1 = &y; // МОЖНО: менять адрес
int *const ptr2 = &x; // Константный указатель
*ptr2 = 15; // МОЖНО: менять значение
// ptr2 = &y; // ОШИБКА: нельзя менять адрес
const int *const ptr3 = &x; // Константный указатель на константу
// *ptr3 = 15; // ОШИБКА
// ptr3 = &y; // ОШИБКА
|
|
Изменение указателя в функции
Адрес на указатель критически важен когда нужно:
- Изменить сам указатель в функции
- Работать с многоуровневыми структурами данных
- Динамически управлять памятью на нескольких уровнях
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void redirect_pointer(int **pptr, int *new_target) {
*pptr = new_target; // Меняем куда указывает оригинальный указатель
}
int main(void) {
int x = 10, y = 20;
int *ptr = &x;
printf("Before: ptr points to %d\n", *ptr); // 10
redirect_pointer(&ptr, &y); // Передаем адрес указателя
printf("After: ptr points to %d\n", *ptr); // 20
return EXIT_SUCCESS;
}
|
|
Указатель и ссылка
В C99 ссылок нет - это фича C++
Указатели - единственный способ "ссылочной" семантики
& - взятие адреса* - разыменование- проверяйте на
NULL перед использованием
malloc/free для динамической памяти
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <stddef.h> // NULL
int main() {
int x = 10;
int *ptr = &x; // или = NULL; Инициализация
//ptr = &x; // Инициализация позже
*ptr = 20; // Разыменование
//ptr = NULL; // Может быть NULL
int x_clone = *ptr;
printf("*&x = %d\n", *&x); // 20 (тут берем адрес и сразу его разыменовываем)
printf("x = %d = %d\n", x_clone, x); // 20 = 20
printf("*ptr = %d\n", *ptr); // 20 (разыменование указателя) т.е. `*ptr == x`
printf("&ptr = %p\n", &ptr); // &ptr это адрес самого ptr в памяти `0x7ffd1ebe48e0`
printf("ptr = &x = %p = %p\n", ptr, &x); // ptr и &x это адрес x `0x7ffd1ebe48dc = 0x7ffd1ebe48dc`
// Учитывая, что каждая шестнадцатеричная цифра соответствует четырем битам, показанные адреса, состоящие из 12 цифр, соответствуют 40-битным адресам.
return EXIT_SUCCESS;
}
Значение (*ptr), на которое указывает указатель ptr, имеет тип int. А что собой представляет собственно ptr?
Мы описываем его как имеющий тип "указатель на int" или новый тип.
Значение ptr — это адрес, и в большинстве систем он внутренне представлен как целое число без знака.
Однако вы не должны считать, что указатель относится к целочисленному типу.
Есть действия, которые можно выполнять над целыми числами, но нельзя над указателями, и наоборот.
int *result_ptr = ptr + 100;
printf("result_ptr = %p\n", result_ptr);
printf("*result_ptr = %d\n", *result_ptr);// мусор
|
|
Указатели на функции (сильная сторона C)
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int add(int a, int b) { return a + b; }
int multiply(int a, int b) { return a * b; }
int main(void) {
// Указатель на функцию
int (*operation)(int, int);
operation = add;
printf("5 + 3 = %d\n", operation(5, 3)); // 8
operation = multiply;
printf("5 * 3 = %d\n", operation(5, 3)); // 15
return EXIT_SUCCESS;
}
|
|
|
int arr[5] = {1, 2, 3, 4, 5};
int *ptr = arr; // ptr указывает на первый элемент
for (int i = 0; i < 5; i++) {
printf("%d ", *(ptr + i)); // Арифметика указателей
}
|
|
|
#include <stddef.h> // NULL
#include <stdlib.h> // malloc
int *dynamic_arr = malloc(10 * sizeof(int));
if (dynamic_arr != NULL) {
for (int i = 0; i < 10; i++) {
dynamic_arr[i] = i * 2;
}
free(dynamic_arr); // Не забываем освободить!
}
|
|
Указатели и операции с ними (тип для указателя int* , char*)
|
#include <stdio.h>
#include <locale.h> // для русского языка
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void){
int *link;// создание указателя для int данных
int origin = 10;
link = &origin;// взятие адреса.Указатель link теперь содержит адрес значения переменной origin
int new_value = *link;// разыменование адреса. Присваивание/копирование значения в new_value данных по адресу link
(*link)++;
printf("Указатели: %d %d адрес:%p данные:%d \n",origin,new_value,link,*link);
return EXIT_SUCCESS;
}
|
|
|
В языке C NULL — это 0
#define NULL ((void*)0) // В C (обычно)
#define NULL 0 // В C++ или иногда в C
#include <stdio.h>
#include <stddef.h> // NULL
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
// NULL для указателей
int *ptr = NULL;
if (ptr == NULL) {
printf("ptr is NULL\n");
}
if(!ptr){
printf("ptr is false\n");
}
//------------------------------------------------------------
int *ptr2; // НЕ инициализирован!
if (!ptr2) { // UB НЕПРЕДЕЛЕННОЕ ПОВЕДЕНИЕ!
printf("ptr appears to be NULL\n"); // МОЖЕТ выполниться случайно
} else {
printf("ptr is not NULL: %p\n", (void*)ptr2); // МОЖЕТ показать случайный адрес
}
// ЕЩЕ ХУЖЕ - если попытаться разыменовать:
// *ptr = 42; // (Segmentation fault, segfault) или порча чужой памяти!
//------------------------------------------------------------
// Статические и глобальные переменные автоматически инициализируются нулями (т.е. NULL для указателей)
static int *ptr3; // Автоматически инициализируется NULL!
if (!ptr3) { // Безопасно, ptr == NULL
ptr3 = malloc(sizeof(int));
}
return EXIT_SUCCESS;
}
|
|
void* — универсальный указатель, и он нужен именно для тех случаев, когда:
- тип данных ещё не известен,
- тип данных должен быть абстрагирован,
- нужен общий интерфейс, работающий с памятью без знания конкретного типа
По стандарту C, любой указатель на объект может быть преобразован в void* и обратно без потерь.
Используется как универсальный контейнер указателей.
void* хранит только адрес, но не хранит, какой там объект.
Если ты приводишь обратно не к тому типу — всё ломается.
|
Разные типы занимают разный объём памяти, и некоторые операции с указателями требуют знания этих размеров.
Например, при p + 1 нужно знать, сколько байт прибавлять:
int* +4, double* +8, char* +1
void* — это указатель на неизвестный тип. И из-за этого у него особые ограничения:
void* p;
*p = 10; // ошибка — неизвестно, сколько байт писать
p++; // ошибка — неизвестно, на сколько байт двигать
В C можно присвоить адрес любого объекта в void* А обратно только в исходного типа:
int x = 10;
void *p = &x; // ОК
// И можно потом вернуть обратно:
int *px = p; // в C это ОК (в C++ нет)
// Но ЭТО работает только если ты возвращаешь в тот же тип.
int x = 0x11223344;
void *p = &x;
short *ps = p; // <-- ОШИБКА типа. То есть информация о типе потеряна и это UB
printf("%x\n", *ps);
Есть ситуации, где тип не нужен или будет известен позже
1. Универсальная память (malloc, calloc, realloc)
malloc возвращает void*, а вы уже приводите указатель к нужному типу
int* a = malloc(10 * sizeof(int));
double* b = malloc(20 * sizeof(double));
2. Универсальные контейнеры, структуры, API
qsort работает с void*, потому что тип элемента неизвестен
void qsort(
void* base,
size_t nmemb,
size_t size,
int (*compar)(const void*, const void*)
);
3. Низкоуровневая работа с памятью
В драйверах, ОС, сетевом коде — когда вам не нужен тип, а просто адрес байтов.
|
|
Указатели на указатели (двойные указатели)
Адрес на указатель критически важен когда нужно:
- Изменить сам указатель в функции
- Работать с многоуровневыми структурами данных
- Динамически управлять памятью на нескольких уровнях
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <stddef.h> // NULL
void allocate_memory(int **pptr) {
*pptr = malloc(sizeof(int)); // Меняем оригинальный указатель
**pptr = 42;
}
int main(void) {
int *ptr = NULL;
allocate_memory(&ptr); // Передаем адрес указателя!
printf("Value: %d\n", *ptr); // 42
free(ptr);
return EXIT_SUCCESS;
}
|
|
Массивы указателей
Адрес на указатель критически важен когда нужно:
- Изменить сам указатель в функции
- Работать с многоуровневыми структурами данных
- Динамически управлять памятью на нескольких уровнях
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
int a = 1, b = 2, c = 3;
int *arr[3] = {&a, &b, &c}; // Массив указателей
for (int i = 0; i < 3; i++) {
printf("arr[%d] = %p, *arr[%d] = %d\n",
i, arr[i], i, *arr[i]);
}
return EXIT_SUCCESS;
}
|
|
Динамические массивы указателей
Адрес на указатель критически важен когда нужно:
- Изменить сам указатель в функции
- Работать с многоуровневыми структурами данных
- Динамически управлять памятью на нескольких уровнях
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
int count = 5;
int **array_of_pointers = malloc(count * sizeof(int*));
// Создаем массив указателей на разные переменные
for (int i = 0; i < count; i++) {
array_of_pointers[i] = malloc(sizeof(int));
*array_of_pointers[i] = i * 10;
}
// Используем
for (int i = 0; i < count; i++) {
printf("array[%d] = %p -> %d\n",
i, array_of_pointers[i], *array_of_pointers[i]);
}
// Чистка
for (int i = 0; i < count; i++) {
free(array_of_pointers[i]);
}
free(array_of_pointers);
return EXIT_SUCCESS;
}
|
|
Связные списки, деревья
Адрес на указатель критически важен когда нужно:
- Изменить сам указатель в функции
- Работать с многоуровневыми структурами данных
- Динамически управлять памятью на нескольких уровнях
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct Node Node;
struct Node {
int data;
struct Node *next;
};
void add_node(struct Node **head, int value) {
struct Node *new_node = malloc(sizeof(struct Node));
new_node->data = value;
new_node->next = *head; // Используем двойной указатель
*head = new_node;
}
int main(void) {
struct Node *list = NULL;
add_node(&list, 10); // Передаем адрес указателя head
add_node(&list, 20);
add_node(&list, 30);
// Обход списка
struct Node *current = list;
while (current != NULL) {
printf("%d -> ", current->data);
current = current->next;
}
printf("NULL\n");
return EXIT_SUCCESS;
}
|
|
В C нет встроенных умных указателей как в Rust/C++, но можно реализовать оба подхода!
|
В C нет встроенных умных указателей как в Rust/C++, но можно реализовать оба подхода!
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
void* data;
} UniquePtr;
UniquePtr unique_create(size_t size) {
UniquePtr ptr;
ptr.data = malloc(size);
return ptr; // Владение передается
}
void unique_destroy(UniquePtr* ptr) {
free(ptr->data);
ptr->data = NULL;
}
// НЕТ функции копирования - только перемещение
UniquePtr unique_move(UniquePtr* source) {
UniquePtr new_ptr = *source;
source->data = NULL; // Источник теряет владение
return new_ptr;
}
int main(void) {
UniquePtr ptr1 = unique_create(100);
// Передача владения
UniquePtr ptr2 = unique_move(&ptr1);
// ptr1.data теперь NULL - безопасно
if (ptr1.data == NULL) {
printf("ptr1 потерял владение\n");
}
unique_destroy(&ptr2);
return EXIT_SUCCESS;
}
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
void* data;
int* ref_count; // Счетчик ссылок
} SharedPtr;
SharedPtr shared_create(size_t size) {
SharedPtr ptr;
ptr.data = malloc(size);
ptr.ref_count = malloc(sizeof(int));
*ptr.ref_count = 1; // Первая ссылка
return ptr;
}
SharedPtr shared_copy(const SharedPtr* other) {
SharedPtr new_ptr = *other;
(*new_ptr.ref_count)++; // Увеличиваем счетчик
return new_ptr;
}
void shared_destroy(SharedPtr* ptr) {
if (ptr->ref_count && ptr->data) {
(*ptr->ref_count)--;
if (*ptr->ref_count == 0) {
free(ptr->data);
free(ptr->ref_count);
ptr->data = NULL;
ptr->ref_count = NULL;
}
}
}
int main(void) {
SharedPtr ptr1 = shared_create(100);
SharedPtr ptr2 = shared_copy(&ptr1); // Две ссылки
printf("Ref count: %d\n", *ptr1.ref_count); // 2
shared_destroy(&ptr2); // Уменьшаем счетчик
printf("Ref count: %d\n", *ptr1.ref_count); // 1
shared_destroy(&ptr1); // Освобождаем память
return EXIT_SUCCESS;
}
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Unique указатель
typedef struct {
int* data;
} UniqueInt;
UniqueInt unique_int_create(int value) {
UniqueInt ptr;
ptr.data = malloc(sizeof(int));
*ptr.data = value;
return ptr;
}
void unique_int_destroy(UniqueInt* ptr) {
free(ptr->data);
ptr->data = NULL;
}
// Shared указатель
typedef struct {
UniqueInt* unique_data;
int* ref_count;
} SharedUniquePtr;
SharedUniquePtr shared_unique_create(int value) {
SharedUniquePtr ptr;
ptr.unique_data = malloc(sizeof(UniqueInt));
*ptr.unique_data = unique_int_create(value);
ptr.ref_count = malloc(sizeof(int));
*ptr.ref_count = 1;
return ptr;
}
void shared_unique_destroy(SharedUniquePtr* ptr) {
if (ptr->ref_count && ptr->unique_data) {
(*ptr->ref_count)--;
if (*ptr->ref_count == 0) {
unique_int_destroy(ptr->unique_data);
free(ptr->unique_data);
free(ptr->ref_count);
ptr->unique_data = NULL;
ptr->ref_count = NULL;
}
}
}
int main(void) {
// Unique указатель - эксклюзивное владение
UniqueInt unique = unique_int_create(42);
printf("Unique value: %d\n", *unique.data);
// Shared указатель - разделяемое владение
SharedUniquePtr shared1 = shared_unique_create(100);
SharedUniquePtr shared2 = shared1; // "Копирование"
(*shared1.ref_count)++; // Вручную увеличиваем счетчик
printf("Shared value: %d, refs: %d\n",
*shared1.unique_data->data, *shared1.ref_count);
unique_int_destroy(&unique);
shared_unique_destroy(&shared1);
shared_unique_destroy(&shared2);
return EXIT_SUCCESS;
}
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define DECLARE_UNIQUE(type) \
typedef struct { \
type* data; \
} Unique##type; \
Unique##type unique_##type##_create(type value); \
void unique_##type##_destroy(Unique##type* ptr);
#define IMPLEMENT_UNIQUE(type) \
Unique##type unique_##type##_create(type value) { \
Unique##type ptr; \
ptr.data = malloc(sizeof(type)); \
*ptr.data = value; \
return ptr; \
} \
void unique_##type##_destroy(Unique##type* ptr) { \
free(ptr->data); \
ptr->data = NULL; \
}
// Использование
DECLARE_UNIQUE(int)
DECLARE_UNIQUE(float)
int main(void) {
Uniqueint unique_int = unique_int_create(42);
Uniquefloat unique_float = unique_float_create(3.14f);
unique_int_destroy(&unique_int);
unique_float_destroy(&unique_float);
return EXIT_SUCCESS;
}
IMPLEMENT_UNIQUE(int)
IMPLEMENT_UNIQUE(float)
- ❌ Нет проверки на этапе компиляции
- ❌ Нет borrow checker
- ✅ Можно иметь оба типа одновременно
- ✅ Гибкая ручная управление памятью
- ✅ Меньшие накладные расходы
В C можно реализовать оба подхода, но вся ответственность за безопасность лежит на программисте!
|
|
|
|
|
|
|
|
|
Например, скрыть подробности реализации в языке С трудно, но хороший программист постарается их не афишировать, чтобы закрытая информация не стала частью интерфейса и не нарушила принцип сокрытия данных. Комментарии в заголовочных файлах, имена особого формата (например, "__iob") и т.д. — все это помогает поощрять хороший стиль программирования там, где не удается заставить пользователя следовать ему.
Хэнсон ("C Interfaces and Implementations" Дэвида Хэнсона) подчеркивает, что интерфейс (заголовочный файл) должен содержать только публичную информацию, необходимую для использования модуля. Все внутренние детали реализации (приватные структуры, статические функции) должны быть скрыты. Это достигается использованием неполных типов (struct T;) или непрозрачных указателей (void *).
|
|
Основные способы объявления и инициализации структур
|
Опасность хранения указателя в структуре (Если вы дурачок который присваивает структуры с указателями):
typedef struct{
int age;
char *name;
} User_2;
Структура не содержит саму строку, а только указатель.
И при копировании:
- копируется указатель,
- но строка остаётся там, где была (часто в динамической памяти или в текстовом сегменте).
Это приводит к:
- двойному освобождению,
- висячим указателям,
- зависимостям между копиями.
Проблема двойного освобождения (double free)
Проблема висячих указателей (dangling pointers)
User u1;
u1.name = malloc(20);
strcpy(u1.name, "Kolya");
User u2 = u1; // !!! По ошибке вы можете скопировать структуры! Но на самом деле копируется только указатель, и теперь у вас два указателя на один адрес
free(u1.name);
u2.name — теперь указывает на уже освобождённую память т.е. получили висячий указатель
free(u2.name); // ← здесь double free
|
|
Основные способы объявления и инициализации структур
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <string.h>
// Декларация типа с дескриптором User и с глобальной переменной global_guest
#define LEN_NAME 60
struct User{
int age;
char name[LEN_NAME];
} global_guest, *global_ptr_guest;
#define AGE 9
#define NAME "Kolya"
struct User global_guest_2 = { AGE, NAME }; // инициализация глобальных и статичных данных только константными выражениеми
// Псевдоним типа через typedef
typedef struct{
int age;
char *name;
} User_2;
typedef struct{
struct User *user1;
User_2 *user2; // Удобное обьявление полей через typedef
} WhoIs;
void print_point(const struct User u) {// const запрещает изменять структуру
printf("%s %d\n", u.name, u.age);
}
void print_point_ptr(const struct User *u) {
printf("%s %d\n", u->name, u->age);
}
int main(void) {
char *name = "Kolya";
int age = 9;
global_guest.age = age;
//strcpy(global_guest.name, name);
snprintf(global_guest.name, sizeof( global_guest.name), "%s", name);
printf("Guest name:%s age:%d",global_guest.name, global_guest.age);
// ститическая переменная
//static struct User static_guest = {.age=age, .name=name}; // Error, глобальные/статические переменные должны быть инициализированы константными выражениеми это происходит во время компиляции, а не во время выполнения используя переменные пусть даже с ключевым словом const.
static struct User static_guest = {.age=9, .name="Kolya"};
print_point(static_guest);
// локальная переменная типа User
struct User local_guest_1 = {};
local_guest_1.age = age;
snprintf(local_guest_1.name, sizeof( local_guest_1.name), "%s", name);
print_point(local_guest_1);
struct User local_guest_2 = {.age=age, .name="Kolya"};
print_point(local_guest_2);
struct User local_guest_3 = {9, "Kolya"};
print_point(local_guest_3);
struct User local_guest_4 = local_guest_3; // инициализация структуры другой структурой, происходит полная копия
print_point(local_guest_4);
// Указатель локальный
struct User *local_guest = NULL;
local_guest = &local_guest_2;
printf("%s", local_guest->name); // то же самое что (*local_guest).name
// Указатель глобальный (он уже обьявлен но нуждается в инициализации)
global_ptr_guest = &local_guest_2;
// Проверка перед доступом к полям
if (global_ptr_guest != NULL) {
printf("%s\n", global_ptr_guest->name);
} else {
fprintf(stderr, "Ошибка: указатель не инициализирован!\n");
}
// Псевдоним типа позволяет опустить слово struct
User_2 local_guest_5 = {};
local_guest_5.age = 9;
local_guest_5.name = "Kolya";
printf("%s", local_guest_4.name);
// Динамически выделить память и освободить ее
struct User *u = malloc(sizeof(struct User));
u->age=9;
snprintf(u->name, sizeof(u->name), "%s", name);
print_point_ptr(u);
free(u);
WhoIs who_is ={.user1=&local_guest_1, .user2=&local_guest_5};
print_point_ptr(who_is.user1);
// Вариант для хранения указателя на строку в структуре
// выделим память через malloc и не забудим освободить память
User_2 local_guest_6 = {};
local_guest_6.age = age;
size_t len = strlen(name) + 1;
local_guest_6.name = (char *) malloc(len);
if (local_guest_6.name == NULL) {
// обработка ошибки
}
//strcpy(local_guest_6.name, name);
snprintf(local_guest_6.name, len, "%s", name);
printf("%s", local_guest_6.name);
free(local_guest_6.name); // освободить heap
return EXIT_SUCCESS;
}
|
|
Как объявить структуру со ссылкой на саму себя
forward declaration + typedef
|
// Говорим компилятору: «Есть структура struct Nameval, и давай дадим ей короткое имя Nameval».
typedef struct Nameval Nameval;
// На этом этапе структура ещё не определена полностью, но уже можно использовать указатели на неё.
struct Nameval {
char *name;
int value;
Nameval *next; // тут можем использовать псевдоним typedef
};
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define LEN 40
typedef struct {
char first[LEN];
char last[LEN];
} Names;
typedef struct {
Names handle;
float income;
char job[LEN];
} Guy;
int main(void){
// присвоение без проверки длин строк
Guy fellow = {
{"Билли", "Боне"},
68112.00f,
"персональный тренер"
};
printf("Name: %s %s",fellow.handle.first, fellow.handle.last); // p.s. плохой код, Guy знает об устройстве Names
return EXIT_SUCCESS;
}
|
|
Выравнивание памяти (struct alignment)
Выравнивание — это количество байт, к которому должен быть кратен адрес переменной.
alignof(T) — это расширение GCC/Clang, которое показывает какое выравнивание (alignment) нужно типу T
Статическая проверка ABI (на лету)
_Static_assert(__alignof__(double) == 8, "double must be 8-byte aligned");
Через правильный порядок полей мы можем уменьшить размер структуры.
Порядок полей влияет на sizeof, но НЕ на alignof.
|
Процессор умеет читать память быстрее, когда данные лежат по «удобным» адресам кратным 4-м для 32 битной (4 байтной) арифметики.
Например, int обычно требует адрес кратный 4, double — кратный 8.
Поэтому компилятор, когда кладёт поля в структуру, добавляет пэддинги (padding) — лишние байты между полями, чтобы каждое поле начиналось с “правильного” адреса.
struct S_1 {
char a; // 1 байт
int b; // 4 байт
char c; // 1 байт
};
offset 0: a (1 байт)
offset 1-3: padding (3 байта, чтобы b лег по адресу кратному 4)
offset 4-7: b (4 байта)
offset 8: c (1 байт)
offset 9-11: padding (3 байта, чтобы размер был кратен 4)
Итоговый размер = 12 байт, хотя данных всего 6
Почему это важно?
- Размер структуры изменится при перестановке полей
- Отличие между CPU архитектурами
- Работа с бинарными протоколами
- Сетевые пакеты, UART, CAN → важно точное расположение
- Сериализация/десериализация
- Очень влияет на производительность в embedded
Выравнивание структуры = максимальное выравнивание всех её полей.
Выравнивание структуры не зависит от порядка полей.
Но через правильный порядок полей мы можем уменьшить размер структуры. Порядок полей влияет на sizeof, но НЕ на alignof.
Как уменьшить размер структуры (правильный порядок полей, а плохой через уплотнение (#pragma pack))
// Не важно, где внутри структуры стоит int — в начале, в конце или посередине —
// структура всё равно должна быть выровнена так, чтобы внутренний int всегда был по адресу кратному 4.
struct S_2 {
int b;
char a;
char c;
};
b: 4 байта
a: 1 байт
c: 1 байт
padding: 2 байта (для кратности 4)
Итоговый размер = 8 байт, а не 12.
printf("alignof(struct S_1) = %zu\n", __alignof__(struct S_1));// 4
printf("sizeof(S_1) = %zu\n", sizeof(struct S_1)); // 12
printf("alignof(struct S_2) = %zu\n", __alignof__(struct S_2));// 4
printf("sizeof(S_2) = %zu\n", sizeof(struct S_2)); // 8
|
|
Зачем нужно выравнивание структур
Адресная арифметика AGU — Address Generation Unit
|
Как x86-64 за один такт вычисляет адрес в памяти.
Должно соблюдаться условие:
- адрес начала массива должен быть кратен размеру данных. Если массив из int (4 байта), то адрес начала должен делиться на 4
- размер данных элементов массива должен быть степенью двойки т.е. строго (1, 2, 4 и 8), если размер больше даже если 16, 32 все равно в один такт не получится.
- размер структуры должен быть выровнен и поля структуры должны быть уложены в чанки по 8 байт.
В железе (в блоке AGU) умножение на произвольное число (например, на 7 или 13) — это медленная операция, требующая полноценного умножителя. А умножение на 1, 2, 4 и 8 делается простым битовым сдвигом влево (на 0, 1, 2 или 3 бита).
Вот формула того, как процессор вычисляет адреса элементов массива и структур. Процессор x86-64 выполняет эту формулу аппаратно внутри одного блока (AGU — Address Generation Unit). Это значит, что сложение и умножение в этой формуле происходят бесплатно с точки зрения времени. Он вычисляет весь адрес целиком за один такт.
Addr = D + Reg[Rb] + Reg[Ri] * S
- D (Displacement): Смещение. Удобно для доступа к полям в структурах (struct)
- Rb (Base): Базовый регистр. Начало массива или объекта
- Ri (Index): Индексный регистр. Номер элемента в массиве
- S (Scale): Множитель (только 1, 2, 4 или 8). Размер типа данных (int — 4 байта, double или указатель — 8 байт)
Пример:
int arr[6] = {1,2,3,4,5,6};
int x = arr[5];// Компилятор превратит вычисление адреса элемента массива в одну инструкцию: (%rdx, %rcx, 4)
- %rdx — адрес начала массива
- %rcx — твой индекс
- 4 — потому что int занимает 4 байта
Допустим:
- D (Displacement) смещение равно 0
- Rb (Base) адрес начала массива %rdx равен 1000
- Ri (Index) равен 5
- S (Scale) размер типа данных для int 4
Addr = D + Reg[Rb] + Reg[Ri] * S = 0 + 1000 + 5 * 4 = 1020
Процессор мгновенно вычисляет адрес 1020 за один такт в AGU, обращается к памяти и забирает оттуда число 6.
Почему индексы массивов начинаются с нуля, если индекс Ri = 0, то: Addr = Base + 0 * Scale = Base т.е. адрес самого массива.
Если у нас массив содержит тип данных размер которых не кратен степени двойки, например, не выровненная структура с двумя полями double и int = 12 байт, процессор уже не сможет вычислить адрес за один такт в AGU с помощью формулы D(Rb, Ri, S)
Выравнивание (Alignment) — это вторая часть проблемы
Даже если мы вычислили адрес правильно, в дело вступает шина данных. Процессор тянет данные из памяти кусками по 8 байт (64 бита). Эти куски «нарезаны» в памяти строго по адресам, кратным 8.
Если наш double лежит по адресу 0x08, он идеально попадает в один «заход» процессора.
Если наш double из-за кривого размера структуры оказался на адресе 0x05, он «размазан» между двумя блоками памяти. Процессору нужно два раза сходить в память, достать два куска, отрезать лишнее и склеить остаток.
|
|
Зачем нужен массив, выровненный по 16 байт
|
Зачем нужен массив, выровненный по 16 байт:
char data[64] __attribute__((aligned(16)));
printf("alignof(data) = %zu\n", __alignof__(data)); // 16
это жесткое требование для некоторых видов быстрого кода, особенно в низкоуровневом, системном, embedded и высокопроизводительном ПО.
Современные процессоры имеют векторные инструкции:
- SSE (__m128) — требует 16-байтового выравнивания
- AVX (__m256) — 32-байтового
- AVX-512 — 64-байтового
Некоторые инструкции CPU, DMA, периферия и криптографические ускорители работают ТОЛЬКО с выровненными на 16/32/64 байт блоками памяти. Это ускоряет доступ и часто является обязательным требованием.
|
|
Выравнивание и паддинг структур
Структура = сумма полей + выравнивание (alignment)
Структуры в памяти — непрерывные
Поэтому можно:
- ✔ копировать память
- ✔ передавать массив структур
- ✔ читать бинарные файлы прямо в struct
На x86-64:
- sizeof(int*) = 8 байт
- alignment = 8 байт (т.е. адрес указателя должен делиться на 8)
На x86-32:
- sizeof(int*) = 4 байта
- alignment = 4 байта
|
Но:
- Разные компиляторы/архитектуры могут по-разному выравнивать → плохо переносимо между платформами
- Для переносимых бинарных форматов используют #pragma pack или читают поля по отдельности
struct Example {
char a; // 1 byte
int b; // 4 bytes
};
Размер будет не 5, а скорее 8 (x86-64), из-за padding.
Но на x86-64 компилятор добавляет padding после char a, чтобы int b начинался с адреса, кратного 4 (alignment requirement).
a занимает 1 байт- 3 байта паддинга
b занимает 4 байта
Итоговый размер структуры = 8 байт
Это нужно для производительности: CPU быстрее обращается к данным, выровненным по своей границе.
Почему это важно на практике:
1. Копирование памяти
Если структура непрерывна в памяти (без вложенных динамических указателей), её можно копировать побайтно:
struct Example e1 = {'x', 42};
struct Example e2;
memcpy(&e2, &e1, sizeof(e1)); // полностью скопировали
// Для структур содержащих указатель нужен другой подход
struct Node {
int id;
char *name; // динамическая память
};
struct Node n1={4,"Jack"};
struct Node n2;
n2.id = n1.id;
n2.name = malloc(strlen(n1.name) + 1);
strcpy(n2.name, n1.name);
// такой способ не скопирует содержимое по указателям!
// memcpy(&n2, &n1, sizeof(n1));
2. Массивы структур
Структуры в памяти непрерывны → массив структур — это просто непрерывный блок памяти:
struct Example arr[3] = {
{'a', 1},
{'b', 2},
{'c', 3}
};
// arr[1] находится через sizeof(struct Example) байт после arr[0]
// Так можно передавать массив структур в функции или читать/записывать его как один кусок памяти:
void process(struct Example *arr, size_t n);
process(arr, 3);
3. Чтение/запись бинарных файлов
Если файл структурирован ровно как наша структура, можно читать сразу в struct:
struct Example e;
FILE *f = fopen("data.bin", "rb");
fread(&e, sizeof(e), 1, f);
|
|
Передача структуры по значению в функцию
Копирование поля структуры типа массив при передаче структуры по значению в функцию
Перемещение локально созданной структуры из функции
|
В C массив нельзя передать по значению, он не может быть параметром функции в чистом виде.
При передаче массива в функцию он неявно преобразуется в указатель на первый элемент.
Структуру можно передавать по значению и она копируется целиком.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
int x;
int arr[5];
} T;
void foo(T s) {
// s — полная копия объекта T
}
// --------------------------------------------------------------
// функция создания структуры типа T
T make_t(int x, const int arr[5]) {
T t;
t.x = x;
// Копируем массив
for (int i = 0; i < 5; i++) {
t.arr[i] = arr[i];
}
return t; // ← безопасно, t копируется
}
int main(void){
int values[5] = {1, 2, 3, 4, 5};
T obj = make_t(42, values);
printf("obj.x = %d\n", obj.x);
printf("obj.arr[2] = %d\n", obj.arr[2]);
return EXIT_SUCCESS;
}
|
|
flexible array member (FAM) - последний элемент структуры может быть массивом неизвестного размера
Ограничение:
- FAM нельзя включать в массив или в другую структуру, потому что размер структуры становится неопределённым.
- Любое использование sizeof или обращение к полю FAM через массив приводит к неопределённому поведению.
(и передача по значению структуры в функцию приведет к копированию массива)
Иначе можно хранить указатель в структуре и ему выделить память
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
struct Buffer {
size_t size;
int data[]; // (FAM) По стандарту C массив должен быть последним полем структуры
};
int main(){
// выделение памяти под саму струтуру `sizeof(struct Buffer)` и плюс для массива `100`
size_t count = 100;
size_t total = sizeof(struct Buffer) + count * sizeof(int);
struct Buffer *b = malloc(total);
if (!b) {
/* обработка ошибки */
return 1;
}
b->size = 100;
memcpy(b->data, some_data, b->size * sizeof(b->data[0]));
free(b);
return EXIT_SUCCESS;
}
Иначе можно хранить указатель в структуре и ему выделить память
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <string.h>
struct Buffer {
size_t size;
int *data;
};
int main(void) {
//int arr_init[5] = { [0 ... 4] = 1 }; // короткий способ
size_t size = 5;
int arr_init[size];
memset(arr_init, 0, sizeof arr_init);// заполнить нулями
/*
// для заполнения массива не нулями
for (size_t i=0; i < size; i++) {
arr_init[i] = 1;
}*/
struct Buffer buff = {.size=size, .data=arr_init};
printf("%d",buff.data[0]);
return EXIT_SUCCESS;
}
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
int id;
char name[50];
} Employee;
int main(void){
Employee emps[3];
emps[0].id=0;
snprintf(emps[0].name, sizeof( emps[0].name), "%s", "John");
emps[1].id=1;
snprintf(emps[1].name, sizeof( emps[1].name), "%s", "Vins");
emps[2].id=2;
snprintf(emps[2].name, sizeof( emps[2].name), "%s", "Tom");
Employee *ptr = &emps[2]; // так берется указатель, в отличии от массива, имя структуры не есть указатель
printf("name: %s",ptr->name);
return EXIT_SUCCESS;
}
|
|
void*
Преобразование указателя void* к структуре
|
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
const char *type;
} Msg;
void test(void *param){
Msg *new_t = (Msg*)param; // или просто: Msg *new_t = param;
printf("%s\n", new_t->type);
}
int main(void){
const char *c = "fff";
Msg msg = {0}; // C-style zero-initialization
msg.type = c;
test(&msg);
return EXIT_SUCCESS;
}
|
|
Выделение памяти для структур
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
typedef struct {
int id;
char name[50];
double salary;
} Employee;
Employee *create_employee(void) {
Employee *emp = malloc(sizeof(*emp));
if (emp == NULL) {
return NULL;
}
// Инициализация полей
emp->id = 0;
emp->name[0] = '\0';
emp->salary = 0.0;
// или так
*emp = (Employee){0}; // полностью обнуляем структуру
return emp;
}
int main(void){
Employee *emp = create_employee();
// Хорошая практика — проверка выхода из диапазона при копировании строк
snprintf(emp->name, sizeof(emp->name), "%s", "John");
// не забыть освободить память
free(emp);
return EXIT_SUCCESS;
}
Массивы структур с инициализацией
size_t team_size = 5;
Employee *team = malloc(team_size * sizeof(*team));
if (team != NULL) {
for (size_t i = 0; i < team_size; i++) {
// team[i] = (Employee){0}; // удобно: и id, и name, и salary установить в 0, а для id потом отдельно
team[i].id = (int)(i + 1);
team[i].name[0] = '\0';
team[i].salary = 0.0;
}
// Хорошая практика — проверка выхода из диапазона при копировании строк
snprintf(team[i].name, sizeof(team[i].name), "%s", "John");
}
free(team);
|
|
Инкапсуляция (полная инкапсуляция через интерфейс)
В C нет настоящей инкапсуляции на уровне языка.
Есть только организационная (или "модульная") инкапсуляция — она работает ровно настолько, насколько мы сами ограничим доступ.
static у функции делает её видимой только в текущем .c-файле (internal linkage).
Без static функция экспортируется, и любой другой объектный файл/модуль может вызвать её.
Правильная практика: всё, что не нужно экспортировать — объявлять static.
И запрещаем/прячем доступ к полям структуры с помощью opaque type (непрозрачный тип)
За счет объявления (forward declaration) typedef struct Stack Stack; в файле stack.h мы прячем от пользователя в main.c реализацию деталей структуры.
Пользователь видит только название типа и что он используется через указатель.
Ограничение, публичный интерфейс НЕ может иметь inline-функций, обращающихся к приватным полям, потому что структура скрыта.
|
Файл stack.h:
typedef struct Stack Stack; // opaque type (непрозрачный тип)
Stack* stack_create(void);
void stack_destroy(Stack* stack);
void stack_push(Stack* stack, int value);
int stack_pop(Stack* stack);
int stack_peek(const Stack* stack);
int stack_is_empty(const Stack* stack);
Файл stack.c:
#include "stack.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
// Приватная структура
struct Stack {
int* data;
size_t capacity;
size_t size;
};
// прототип функции которую мы вызовем до ее реализации
static void resize_stack(struct Stack* stack, size_t new_capacity);
Stack* stack_create(void) {
Stack* s = malloc(sizeof(*s));
if (!s) return NULL;
s->capacity = 10;
s->size = 0;
s->data = malloc(s->capacity * sizeof(int));
if (!s->data) { free(s); return NULL; }
return s;
}
// Остальные функции...
void stack_push(Stack* stack, int value){
if (stack->size == stack->capacity) {
resize_stack(stack, stack->capacity * 2);
/* лучше проверять результат расширения на NULL */
}
stack->data[stack->size++] = value;
}
int stack_pop(Stack* stack){
if (stack->size == 0) {
/* поведение по выбору: abort, возвращать ошибку и т.д. */
return 0; /* условный ответ */
}
return stack->data[--stack->size];
}
void stack_destroy(Stack* stack){
if (!stack) return;
free(stack->data);
free(stack);
}
int stack_peek(const Stack* stack) {
if (stack->size == 0) return 0;
return stack->data[stack->size - 1];
}
int stack_is_empty(const Stack* stack) {
return stack->size == 0;
}
/* Приватная (видимая только в этом translation unit) функция */
static void resize_stack(Stack* stack, size_t new_capacity) {
int *new_data = malloc(new_capacity * sizeof(int));
if (!new_data) return; // простая обработка OOM; можно улучшить
if (stack->data) {
memcpy(new_data, stack->data, stack->size * sizeof(int));
free(stack->data);
}
stack->data = new_data;
stack->capacity = new_capacity;
}
Файл main.c:
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include "stack.h"
int main(void) {
Stack *s = stack_create();
if (!s) return 1;
stack_push(s, 42);
stack_push(s, 7);
printf("%d\n", stack_pop(s)); // 7
printf("%d\n", stack_pop(s)); // 42
stack_destroy(s);
// НЕТ доступа к приватным функциям resize_stack() и деталям реализации струтуры stack->data, stack->size и т.д.
return EXIT_SUCCESS;
}
|
|
Инкапсуляция (Классическая схема "Opaque Type + Inline API")
Инлайн-функции в .h получают доступ к полям, но только если определён флаг MODULE_IMPLEMENTATION
Макросы для доступа к приватным полям.
Это работает за счёт хитрого приёма с препроцессором, который переименовывает приватные поля в заголовочном файле, но оставляет их настоящими в .c файле.
Клиентский код видит одни имена полей, а модульная реализация — совсем другие. То есть пользователь физически не сможет обратиться к настоящим приватным полям, потому что в его версии структуры этих полей как будто не существует.
Пользователю не будет видно реальной структуры, т.к.:
- он подключает только module.h, а в нём нет определения полей struct Secure
- inline-функции доступны, но не раскрывают структуру, т.к. в module_inline.inl они компилируются только если: #define MODULE_IMPLEMENTATION
То есть только в реализации модуля.
|
Файл stack.h: - интерфейс
#ifndef MODULE_H
#define MODULE_H
#include <stddef.h>
typedef struct Stack Stack;// opaque type (непрозрачный тип)
Stack* stack_create(void);
void stack_destroy(Stack* stack);
void stack_push(Stack* stack, int value);
int stack_pop(Stack* stack);
int stack_peek(const Stack* stack);
int stack_is_empty(const Stack* stack);
// Публичные inline функции, которые должны иметь доступ к структуре
// но не раскрывать её пользователю
size_t stack_capacity(const Stack* s);
#endif // MODULE_H
Файл stack_internal.h (НЕ экспортируется пользователю):
// Это приватный header, который включают только .c файлы этого модуля.
#ifndef MODULE_INTERNAL_H
#define MODULE_INTERNAL_H
#define MODULE_IMPLEMENTATION // важно перед подключением stack.h
#include "stack.h"
struct Stack {
int* data;
size_t capacity;
size_t size;
};
#endif
Файл stack.c: — реализация
#include "stack_internal.h"
#include <stdlib.h>
#include <string.h>
// прототип функции которую мы вызовем до ее реализации
static void resize_stack(struct Stack* stack, size_t new_capacity);
Stack* stack_create(void) {
Stack* s = malloc(sizeof(*s));
if (!s) return NULL;
s->capacity = 10;
s->size = 0;
s->data = malloc(s->capacity * sizeof(int));
if (!s->data) { free(s); return NULL; }
return s;
}
// Остальные функции...
void stack_push(Stack* stack, int value){
if (stack->size == stack->capacity) {
resize_stack(stack, stack->capacity * 2);
/* лучше проверять результат расширения на NULL */
}
stack->data[stack->size++] = value;
}
int stack_pop(Stack* stack){
if (stack->size == 0) {
/* поведение по выбору: abort, возвращать ошибку и т.д. */
return 0; /* условный ответ */
}
return stack->data[--stack->size];
}
void stack_destroy(Stack* stack){
if (!stack) return;
free(stack->data);
free(stack);
}
int stack_peek(const Stack* stack) {
if (stack->size == 0) return 0;
return stack->data[stack->size - 1];
}
int stack_is_empty(const Stack* stack) {
return stack->size == 0;
}
/* Приватная (видимая только в этом translation unit) функция */
static void resize_stack(Stack* stack, size_t new_capacity) {
int *new_data = malloc(new_capacity * sizeof(int));
if (!new_data) return; // простая обработка OOM; можно улучшить
if (stack->data) {
memcpy(new_data, stack->data, stack->size * sizeof(int));
free(stack->data);
}
stack->data = new_data;
stack->capacity = new_capacity;
}
// Инлайн-функции должны иметь доступ к полям,
// поэтому их реализацию кладём в отдельный .inl файл
#include "stack_inline.inl"
Файл stack_inline.inl — реализация inline-функций:
#ifdef MODULE_IMPLEMENTATION
inline size_t stack_capacity(const Stack* s) {
return s->capacity; //
}
#endif
Файл main.c: - клиент
#include "stack.h"
#include <stdio.h>
int main() {
Stack *s = stack_create();
if (!s) return 1;
stack_push(s, 42);
stack_push(s, 7);
printf("%d\n", stack_pop(s)); // 7
printf("%d\n", stack_pop(s)); // 42
// Доступ только через API:
printf("%ld\n", stack_capacity(s));// 10
stack_destroy(s);
// НЕТ доступа к resize_stack и stack->data, stack->size и т.д.
}
Makefile:
CC = gcc
CFLAGS = -Wall -Wextra -std=c99
TARGET = my_program.out
SOURCES = main.c stack.c
OBJECTS = $(SOURCES:.c=.o)
$(TARGET): $(OBJECTS)
$(CC) $(CFLAGS) -o $(TARGET) $(OBJECTS)
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
clean:
rm -f $(OBJECTS) $(TARGET)
.PHONY: clean
# make # Сборка
# ./my_program.out # Запуск
# make clean # Очистка
|
|
|
|
|
|
|
|
|
union в C — это объединение, специальный тип данных, который позволяет нескольким полям занимать одно и то же место в памяти.
- В каждый момент времени валидным является только то поле, которое было записано последним.
- Все поля начинаются с одного и того же адреса.
- В union нельзя иметь гибкие массивы
- Размер union = размер самого большого поля.
Например:
int i = 4 байта
float f = 4 байта
char[4] = 4 байта
Итого sizeof(union Example) = 4 байта.
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
union Hold{
int digit;
double bigfl;
char letter;
};
union Hold_2{
int digit;
double bigfl;
char letter;
} global_fir;
int main(void){
// присваивание (assignment) глобальной переменной
global_fir.letter = 'Q';
printf("%c\n",global_fir.letter);
// Инициализация
union Hold fit_3 = {.digit=100};
printf("%d",fit_3.digit);
fit_3.bigfl = 0.1;// теперь предыдущее значение fit_3.digit уже недоступно т.е. Undefined Behavior (UB).
printf("bigfl=%f",fit_3.bigfl);
//printf("digit=%d",fit_3.digit);// мусор
// Присваивание
union Hold fit;
fit.letter = 'W';
printf("%c\n",fit.letter);
fit.bigfl=8.0;
printf("%f\n",fit.bigfl);
// массив типов union
union Hold arr[5];
arr[0]=fit;
printf("%c",arr[0].letter);
// указатель на тип union
union Hold *ptr;
ptr=&fit;
printf("%c",ptr->letter);
// Создание union из другого union
union Hold fit_2 = fit;
printf("%c",fit_2.letter);
return EXIT_SUCCESS;
}
|
|
Интерпретация одних и тех же байт как разных типов
Используется в драйверах, сетевых протоколах, бинарных форматах.
|
В стандарте C: если ты записал в одно поле union, а читаешь другое — это Undefined Behavior (UB).
Даже если это физически работает на большинстве компиляторов.
По стандарту это UB, но на практике работает почти везде, потому что:
- float и uint32_t лежат в одной и той же памяти,
- ты просто читаешь те же 4 байта как другой тип.
union FloatCast {
float f;
uint32_t u;
};
union FloatCast x;
x.f = 1.0f;
printf("%08X\n", x.u); // битовое представление float
// Легальным альтернатива
float f = 1.0f;
uint32_t u;
memcpy(&u, &f, sizeof(u));
printf("%08X\n", u);
|
|
Проблема обычного union — компилятор НЕ знает, какой тип сейчас хранится
Компилятор НЕ следит за тем, "что сейчас в union лежит"
Вариантный тип (tagged union) решает эту проблему
Это уже НЕ просто union, это 100% безопаснее обычного union
Это struct, содержащая:
- tag — тип данных
- union — сами данные
Для чего нужен tagged union?
- JSON-парсер в C
- AST-узел в компиляторе
- Реализация std::variant из C++
- События (event system)
Идея tagged union — как в Rust enum
enum Value {
Int(i32),
Float(f32),
Str(String)
}
|
И это и UB, и ошибочно, и вообще непредсказуемо
union U x;
x.f = 1.23f;
printf("%d\n", x.i);
Вариантный тип (tagged union)
Файл safe_value.h
// Пользователь видит только API, не поля.
#ifndef SAFE_VALUE_H
#define SAFE_VALUE_H
#include <stddef.h>
typedef struct Value Value;
typedef enum {
TYPE_INT,
TYPE_FLOAT,
TYPE_STR
} ValueType;
Value value_int(int x);
Value value_float(float x);
Value value_str(const char* s);
int value_as_int(const Value* v);
float value_as_float(const Value* v);
const char* value_as_str(const Value* v);
ValueType value_type(const Value* v);
void value_free(Value* v);
#endif
Файл safe_value.c (реализация — поля скрыты)
#include "safe_value.h"
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
struct Value {
ValueType type;
union {
int i;
float f;
char* s;
} data;
};
#define CHECK_TYPE(v, expected) \
do { \
if ((v)->type != (expected)) { \
fprintf(stderr, "Type error: expected %d, got %d\n", \
(expected), (v)->type); \
abort(); \
} \
} while (0)
Value value_int(int x) {
Value v;
v.type = TYPE_INT;
v.data.i = x;
return v;
}
Value value_float(float x) {
Value v;
v.type = TYPE_FLOAT;
v.data.f = x;
return v;
}
Value value_str(const char* s) {
Value v;
v.type = TYPE_STR;
v.data.s = strdup(s);
return v;
}
int value_as_int(const Value* v) {
CHECK_TYPE(v, TYPE_INT);
return v->data.i;
}
float value_as_float(const Value* v) {
CHECK_TYPE(v, TYPE_FLOAT);
return v->data.f;
}
const char* value_as_str(const Value* v) {
CHECK_TYPE(v, TYPE_STR);
return v->data.s;
}
ValueType value_type(const Value* v) {
return v->type;
}
void value_free(Value* v) {
if (v->type == TYPE_STR) {
free(v->data.s);
}
v->type = TYPE_INT;
v->data.i = 0;
}
Файл main.c — использование (безопасное)
#include "safe_value.h"
#include <stdio.h>
int main() {
Value a = value_int(10);
Value b = value_float(3.14f);
Value c = value_str("hello");
printf("a = %d\n", value_as_int(&a));
printf("b = %f\n", value_as_float(&b));
printf("c = %s\n", value_as_str(&c));
value_free(&c);
return 0;
}
|
|
Создание аналога Result из Rust
|
File result_gen.h
#ifndef RESULT_GEN_H
#define RESULT_GEN_H
#include <stdio.h>
#include <stdlib.h>
/*
OkType — тип значения, когда операция успешна (T в Rust)
ErrType — тип ошибки (E в Rust), может быть struct, enum, строка и т.д.
Name — имя нового типа Result, который мы генерируем
*/
#define DEFINE_RESULT(OkType, ErrType, Name) \
typedef struct { \
int is_ok; /* 1 = Ok, 0 = Err */ \
union { \
OkType ok; /* успешное значение */ \
ErrType err; /* ошибка */ \
} val; \
} Name; \
/* Функции-конструкторы */ \
static inline Name Name##_ok(OkType v) { \
Name r; r.is_ok = 1; r.val.ok = v; return r; \
} \
\
static inline Name Name##_err(ErrType e) { \
Name r; r.is_ok = 0; r.val.err = e; return r; \
} \
/* Функции доступа */ \
/* unwrap() с проверкой, печатает payload */ \
static inline OkType Name##_unwrap(Name r) { \
if (!r.is_ok) { \
fprintf(stderr, "unwrap() called on Err: %s (code %d)\n", \
r.val.err.message, r.val.err.code); \
abort(); \
} \
return r.val.ok; \
} \
\
/* unwrap_err() с проверкой */ \
static inline ErrType Name##_unwrap_err(Name r) { \
if (r.is_ok) { \
fprintf(stderr, "unwrap_err() called on Ok\n"); \
abort(); \
} \
return r.val.err; \
} \
\
/* unwrap_or(default) */ \
static inline OkType Name##_unwrap_or(Name r, OkType def) { \
return r.is_ok ? r.val.ok : def; \
} \
\
/* expect(msg) */ \
static inline OkType Name##_expect(Name r, const char* msg) { \
if (!r.is_ok) { \
fprintf(stderr, "%s: %s (code %d)\n", msg, \
r.val.err.message, r.val.err.code); \
abort(); \
} \
return r.val.ok; \
}
#endif
File fs_error.h
#ifndef FS_ERROR_H
#define FS_ERROR_H
typedef enum {
FS_ERR_NONE,
FS_ERR_NOT_FOUND,
FS_ERR_PERMISSION
} FsErrorKind;
typedef struct {
FsErrorKind kind;
const char* message;
int code;
} FsError;
static inline FsError fs_error(FsErrorKind kind, const char* msg, int code) {
FsError e = { kind, msg, code };
return e;
}
#endif
File fs_result.h
#include "result_gen.h"
#include "fs_error.h"
// Result<char*, FsError> — операция возвращает строку (например, путь)
DEFINE_RESULT(char*, FsError, FsResult)
File math_error.h
#ifndef MATH_ERROR_H
#define MATH_ERROR_H
typedef enum {
MATH_ERR_NONE,
MATH_ERR_DIV_ZERO,
MATH_ERR_OVERFLOW
} MathErrorKind;
typedef struct {
MathErrorKind kind; // тип ошибки
const char* message; // текстовое описание
int code; // числовой код
} MathError;
static inline MathError math_error(MathErrorKind kind, const char* msg, int code) {
MathError e = { kind, msg, code };
return e;
}
#endif
File math_result.h
#ifndef MATH_RESULT_H
#define MATH_RESULT_H
#include "result_gen.h"
#include "math_error.h"
// Result<int, MathError>
DEFINE_RESULT(int, MathError, MathResult)
#endif
File main.c
#include "math_result.h"
#include "fs_result.h"
#include <stdio.h>
MathResult divide(int a, int b) {
if (b == 0) {
return MathResult_err(math_error(MATH_ERR_DIV_ZERO,
"division by zero", 1001));
}
return MathResult_ok(a / b);
}
FsResult read_file(const char* path) {
if (!path) {
return FsResult_err(fs_error(FS_ERR_NOT_FOUND, "Path is NULL", 404));
}
// ...
return FsResult_ok("file contents"); // условно
}
int main() {
MathResult r1 = divide(10, 2);
MathResult r2 = divide(10, 0);
if (r1.is_ok) {
printf("Result: %d\n", MathResult_unwrap(r1));
} else {
MathError e = MathResult_unwrap_err(r1);
printf("Error: %s (code %d)\n", e.message, e.code);
}
if (r2.is_ok) {
printf("Result: %d\n", MathResult_unwrap(r2));
} else {
MathError e = MathResult_unwrap_err(r2);
printf("Error: %s (code %d)\n", e.message, e.code);
}
//-------------------------------------------------------
FsResult r = read_file(NULL);
if (r.is_ok) {
printf("File: %s\n", FsResult_unwrap(r));
} else {
FsError e = FsResult_unwrap_err(r);
printf("Error: %s (code %d)\n", e.message, e.code);
}
return 0;
}
|
|
Создание аналога Option из Rust
В чистом C нет дженериков, поэтому классический подход с DEFINE_OPTION(int, OptionInt) создаёт новый тип для каждого типа данных.
Это действительно неудобно, но в C это нормальная практика.
|
File option_gen.c
// option_gen.h
#ifndef OPTION_H
#define OPTION_H
#include <stdio.h>
#include <stdlib.h>
#define DEFINE_OPTION(Type, Name) \
typedef struct { \
int has_value; \
Type val; \
} Name; \
\
static inline Name Name##_some(Type v) { \
Name o; o.has_value = 1; o.val = v; return o; \
} \
\
static inline Name Name##_none(void) { \
Name o; o.has_value = 0; return o; \
} \
\
static inline Type Name##_unwrap(Name o) { \
if (!o.has_value) { \
fprintf(stderr, "Option::unwrap called on None\n"); \
abort(); \
} \
return o.val; \
} \
\
static inline Type Name##_unwrap_or(Name o, Type def) { \
return o.has_value ? o.val : def; \
} \
\
static inline int Name##_is_some(Name o) { return o.has_value; } \
static inline int Name##_is_none(Name o) { return !o.has_value; }
#endif
File main.c
#include "option_gen.h"
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
DEFINE_OPTION(int, OptionInt)
typedef struct {
int age;
char name[32];
} User;
DEFINE_OPTION(User, OptionUser)
OptionInt find_even(int* arr, int size) {
for (int i = 0; i < size; i++) {
if (arr[i] % 2 == 0) return OptionInt_some(arr[i]);
}
return OptionInt_none();
}
int main(void) {
int a[] = {1,3,5,8,11};
OptionInt r = find_even(a, 5);
if (OptionInt_is_some(r)) {
printf("Found even: %d\n", OptionInt_unwrap(r));
} else {
printf("No even number found\n");
}
// безопасно с дефолтом
int val = OptionInt_unwrap_or(r, -1);
printf("Value or default: %d\n", val);
// -------------------------------------------------
User u1 = {25, "Kolya"};
OptionUser opt = OptionUser_some(u1); // Some
OptionUser empty = OptionUser_none(); // None
if (OptionUser_is_some(opt)) {
User x = OptionUser_unwrap(opt);
printf("User: %s, age: %d\n", x.name, x.age);
}
if (OptionUser_is_none(empty)) {
printf("No user found\n");
}
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
Перечисление enum (enumeration) — это именованный набор целочисленных констант.
Каждой константе автоматически присваивается целое число (по умолчанию начиная с 0)
Тип enum в C по стандарту — int, хотя компилятор может оптимизировать размер.
Обычно enum применяют для tagged union и для кодов ошибок.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
typedef enum {
ERR_NONE = 0,
ERR_DIV_ZERO = 1,
ERR_OVERFLOW = 100
} MathError;
int main(void){
MathError err = ERR_OVERFLOW;
if (err == ERR_OVERFLOW) {
printf("ERR_OVERFLOW!\n");
}
return EXIT_SUCCESS;
}
|
|
Вместо макросов используйте enum
Это избавляет от логических ошибок при подстановках кода макроса в выражения на этапе компиляции
И делает наглядным применение общих данных
|
#define MINROW 1 /* верхний край */
#define MINCOL 1 /* левый край */
// ...
enum {
MINROW=1, /* верхний край */
MINCOL=1, /* левый край */
MAXROW=24, /* нижний край (<=) */
LABELROW=1, /* местоположение меток */
HEIGHT=MAXROW-4, /* высота столбцов гистограммы */
};
|
|
|
|
|
|
Проектная философия С предусматривает использование функций в качестве строительных блоков.
Фактический аргумент — это выражение, указанное в круглых скобках при вызове функции.
Формальный параметр - это переменная, объявленная в заголовке определения функции.
Когда функция вызывается, переменные, объявленные как формальные параметры, создаются и инициализируются значениями, которые получены в результате вычисления фактических аргументов.
|
|
_Noreturn — функция никогда не возвращается, в стандарте C11
Это подсказка компилятору + анализаторам.
|
Применяется к:
- exit()
- abort()
- panic/assert-fail функций
- бесконечным циклам
#include <stdnoreturn.h>
_Noreturn void fatal(const char* msg) {
puts(msg);
exit(1);
}
// не нужно генерировать предупреждение "в функции нет return"
_Noreturn void blink_forever(void) {
while (1) {
toggle_led();
}
}
|
|
|
inline — рекомендация компилятору, а не строгая директива. Компилятор может проигнорировать inline, если функция слишком большая.
Определение встраиваемой функции должно находиться в том же файле, что и ее вызов. Встраиваемая функция является исключением из правила, которое не рекомендует помещать исполняемый код в заголовочный файл. Так как встраиваемая функция имеет внутреннее связывание, ее определение в нескольких файлах не вызывает проблем. Следовательно, если программа состоит из нескольких файлов, встраиваемое определение понадобится поместить в каждый файл, который вызывает функцию. Для достижения такого условия проще всего указать определение встраиваемой функции в заголовочном файле и затем включать этот файл в файлы, где функция применяется.
Проблема обычного вызова функции
При обычном вызове функции происходят накладные расходы:
- Сохранение контекста — регистры, стек, адрес возврата.
- Передача аргументов — через стек или регистры.
- Переход к функции — переход по адресу.
- Возврат из функции — восстановление контекста, возврат значения.
Что делает inline
- Ключевое слово inline подсказывает компилятору, что вместо обычного вызова функции можно вставить тело функции прямо в код места вызова.
- "превращение функции во встраиваемую предполагает, что ее вызов будет настолько быстрым, насколько это возможно. Степень, до которой подобные предположения эффективны , зависит от реализации"
- может быть не видна в отладчике
- нельзя получить ее адрес
- должна быть короткой (для длинной это не поможет сэкономить время)
Ключевое слово inline говорит компилятору:
«Эта функция маленькая и часто вызывается — попробуй встроить её прямо туда, где она вызывается, вместо обычного вызова через стек.»
То есть inline-функция может заменить вызов функции на её тело, что убирает накладные расходы на call/return.
В стандарте говорится, что функция с внутренним связыванием может быть сделана встраиваемой, и данное определение для встраиваемой функции должно находиться в том же файле, где функция применяется. Поэтому простой подход предполагает использование спецификатора функции inline наряду со спецификатором класса хранения static.
// File eatline.h
#ifndef EATLINE_H_
#define EATLINE_H_
inline static void eatline(){
while (getchar() != '\п')
continue;
}
}
#endif
// File main.c
#include "eatline.h"
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <stdio.h>
int main(void) {
eatline();
return EXIT_SUCCESS;
}
|
|
В C99 и выше, чтобы избежать multiple definition при включении .h в несколько файлов, используют static:
|
static → функция видна только в этом translation unit → не конфликтует при линковке.
static size_t stack_capacity(const Stack* s) {
return s->capacity;
}
|
|
Обьявление прототипа
основная задача заключается в том, чтобы обеспечить появление объявления функции до ее фактического применения, можно обьявить и внутри main
|
Прототип функции foo без указания его аргументов позволяет пропустить проверку компилятора и это не дает сообщения ошибки.
$ gcc -std=c99 -O0 test.c -o test.out
Теперь ошибка несовпадения типов параметров будет проигнорирована
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int foo();// не верный прототип
int foo_correct(int a);// верный прототип
// int foo_correct(int);// или так
int foo_correct_two(char, int);// верный прототип, типы и последовательность параметров должны совпадать с реализацией
int main(void) {
printf("%d\n",foo("dddd")); // 1879986180
printf("%d\n",foo_correct("dddd")); // 1879986180
return EXIT_SUCCESS;
}
int foo(int a){
return a;
}
int foo_correct(int a){
return a;
}
int foo_correct_two(char c, int a){
return (int)c+a;
}
Но верно указанные типы аргументов foo_correct помогут компилятору выдать сообщение о ошибке:
gcc -std=c99 -Wall -Wextra -Wformat -Wformat=2 -Wformat-security -O0 test.c -o test.out
for.c: In function ‘main’:
for.c:7:31: warning: passing argument 1 of ‘foo_correct’ makes integer from pointer without a cast [-Wint-conversion]
7 | printf("%d\n",foo_correct("dddd"));
| ^~~~~~
| |
| char *
for.c:3:21: note: expected ‘int’ but argument is of type ‘char *’
3 | int foo_correct(int a);
|
|
|
Файл prog.exe:
#include <stdio.h>
#include <locale.h> // для русского языка
#include <unistd.h> // для sleep
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
const unsigned char NUMBER = 2;// константа
// Обьявлние прототипа ф-ции, компилятор должен знать о ф-ции до ее использования
void show(char *name,int *arr,int size);
int add(int val,int inc);
void test(char *argv[]){
printf("%s\n",argv[0]);// fw
printf("%s\n",*++argv);// w передвинуть указатель в массиве вперед
}
int main(int argc, char *argv[], char *env[]){
// /prog.exe file1 file2 file3
// argc = 4
// argv[0] - это указатель на строку /prog.exe, argv[1] - на строку file1 и т.д
setlocale(LC_ALL, "Rus"); // для русского языка
int arr_init[5] = {0, 1, 2, 3, 4};
char *name = "Gosha";
show(name,arr_init,5);
// указатель на функцию
int (*f_point)();
f_point = add;// имя функции (без скобок и аргументов) это указатель на нее
int result = f_point(2,4);
printf("result:%d\n",result);
// char *argv[] - массив (неопределенного размера) указателей на char
char l = 'f';
char *p=&l;
char l2 = 'w';
char *p2=&l2;
char *arr_p[2]={p,p2};
test(arr_p);
sleep(1); // 1 сек
return EXIT_SUCCESS;
}
void show(char *name,int *arr,int size){
printf("%s\n",name);
for(int i=0;i<size;i++){
printf("%d %d",arr[i],add(i,5));
}
}
int add(int val,int inc){
return val+inc;
}
Запуск:
/prog.exe file1 file2 file3
|
|
Функция возвращает указатель
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int *addArrays(int a[], int b[], int n) {
int *ptr = calloc(n, sizeof(int)); // выделение памяти динамически
for (int i = 0; i < n; i++)
ptr[i] = a[i] + b[i];
return ptr;
}
int main(void){
int a[] = {3,4,5,6,7};
int b[] = {1,1,1,1,1};
int n = sizeof(a)/sizeof(a[0]);
int *ptr = addArrays(a, b, n);
for(int i=0;i<n;i++)
printf("%d \t", *ptr++);
free(ptr);
return EXIT_SUCCESS;
}
|
|
Функции malloc() и free() используются для динамического распределения свободной памяти.
Функция malloc() выделяет память, функция free() освобождает ее.
void *malloc(size_t size);
void *free(void *p);
|
Память
Стек ------------------------------------------- верхние адреса
Сободная память
Глобальные переменные и константы
Код программы ----------------------------------- нижние адреса
Стек для локальные переменных.
Для глобальных переменных отводится фиксированное место в памяти.
Функция malloc() выделяет динамически память, функция free() освобождает ее.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void){
int *p, i;
p = (int *) malloc(100 * sizeof(int)); // Выделение памяти для 100 целых чисел
if (!p) {
printf("Недостаточно памяти\n");
exit(1);
}
for (i = 0; i < 100; ++i) *(p+i) = i; // Использование памяти
for (i = 0; i < 100; ++i) printf("%d", *(p++) );
free(p); // Освобождение памяти
return EXIT_SUCCESS;
}
|
|
Управление динамической памятью
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void createPointer(){
int *p = NULL;
int n = 1;
if(p==NULL)
{
p = malloc(n * sizeof(int));
*p = 1;
}
printf("%d \t", (*p));
(*p)++;
free(p);
}
int main(void){
createPointer();
createPointer();
createPointer();
return EXIT_SUCCESS;
}
|
|
Рекурсия
Из-за того, что каждый рекурсивный вызов создает собственный набор переменных, вариант с рекурсией использует больше памяти; каждый рекурсивный вызов помещает в стек новый набор переменных.
При этом ограниченный объем стека может устанавливать предел количества рекурсивных вызовов.
Рекурсия выполняется медленнее, т.к. каждый вызов функции занимает определенное время.
|
Пример хвостовой рекурсии (вызов функции на повтор происходит в конце)
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void up_and_down(int);// прототип
int main(void) {
up_and_down(1);
return EXIT_SUCCESS;
}
void up_and_down(int n){ // на каждом новом фрейме рекурсии переменная n будет уникальной
printf("Уровень %d: ячейка n %p\n", n, &n) ; // 1
if (n < 4)
up_and_down(n+1);
printf ("УРОВЕНЬ %d: ячейка n %p\n", n, &n) ; // 2 Эта часть будет выполнятся в обратном порядке вызова так как происходит раскрутка вызовов от конца к началу
}
/*
Уровень 1: ячейка n 0x7ffdc208936c
Уровень 2: ячейка n 0x7ffdc208934c
Уровень 3: ячейка n 0x7ffdc208932c
Уровень 4: ячейка n 0x7ffdc208930c
УРОВЕНЬ 4: ячейка n 0x7ffdc208930c <----- после окончания условия продолжения рекурсии,
УРОВЕНЬ 3: ячейка n 0x7ffdc208932c <----- сразу же происход размотка стека вызовов обратно в том же порядке
УРОВЕНЬ 2: ячейка n 0x7ffdc208934c
УРОВЕНЬ 1: ячейка n 0x7ffdc208936c
*/
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int factorial(int);
int main(void) {
printf("%d",factorial(10));
return EXIT_SUCCESS;
}
int factorial(int number){
// если произведена попытка вычислить факториал нуля
if (number < 1) return 0;
// если вычисляется факториал единицы
// именно здесь произведется выход из рекурсии
else if (number == 1) return 1;
// любое другое число вызывает функцию заново с формулой N-1
else return number * factorial(number-1);//Если факториал 5-ти => 5*4*3*2*1//Для проверки установить тут точку останова
}
|
|
С помощью рекурсии проверяют валидность Binary Search Tree
|
Проверка корректности BST (все узлы левого поддерева меньше родителя и его правого поддерева)
Реализация:
* вариант через проверку inorder
* вариант через проверку диапазона (Min/Max bounds)
**Min/Max bounds**
7
/ \
5 9
Каждый узел должен быть в правильном диапазоне.
Родитель должен быть больше левого дочернего элемента, и меньше чем правый.
1. Проверка корня
root = 7
check: (-∞ ; +∞)
7 > -∞ OK
7 < +∞ OK
2. Проверка левого поддерева (Левый ребёнок всегда должен быть меньше корня.)
left = 5
check: (-∞ ; 7)
5 > -∞ OK
5 < 7 OK
3. Проверяем правое поддерево (Правый ребёнок должен быть больше корня)
right = 9
check: (7 ; +∞)
9 > 7 OK
9 < +∞ OK
static bool _bst_is_valid(const Node* node, int min, int max) {
if (!node) return true;
if (node->data <= min || node->data >= max)
return false;
return _bst_is_valid(node->left, min, node->data) &&
_bst_is_valid(node->right, node->data, max);
}
bool bst_is_valid(const Tree* t) {
return _bst_is_valid(t->head, INT_MIN, INT_MAX);
}
|
|
Двойная рекурсия - это когда функция вызывает себя дважды
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Классическая двойная рекурсия (очень медленная!)
int fibonacci(int n) {
if (n <= 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2); // ← двойной вызов
}
// Версия с печатью вызовов для демонстрации
int fibonacci_debug(int n, int depth) {
for (int i = 0; i < depth; i++) printf(" ");
printf("fib(%d)\n", n);
if (n <= 1) {
for (int i = 0; i < depth; i++) printf(" ");
printf("return %d\n", n);
return n;
}
int left = fibonacci_debug(n - 1, depth + 1);
int right = fibonacci_debug(n - 2, depth + 1);
for (int i = 0; i < depth; i++) printf(" ");
printf("return %d + %d = %d\n", left, right, left + right);
return left + right;
}
int main(void) {
printf("=== Fibonacci с двойной рекурсией ===\n");
// Простая версия
for (int i = 0; i < 10; i++) {
printf("fib(%d) = %d\n", i, fibonacci(i));
}
printf("\n=== Дерево вызовов для fib(4) ===\n");
fibonacci_debug(4, 0);
return EXIT_SUCCESS;
}
=== Fibonacci с двойной рекурсией ===
fib(0) = 0
fib(1) = 1
fib(2) = 1
fib(3) = 2
fib(4) = 3
fib(5) = 5
fib(6) = 8
fib(7) = 13
fib(8) = 21
fib(9) = 34
=== Дерево вызовов для fib(4) ===
fib(4)
fib(3)
fib(2)
fib(1)
return 1
fib(0)
return 0
return 1 + 0 = 1
fib(1)
return 1
return 1 + 1 = 2
fib(2)
fib(1)
return 1
fib(0)
return 0
return 1 + 0 = 1
return 2 + 1 = 3
|
|
Функции из библиотеки math.h медленные для embedded
Поэтому в embedded почти всегда используют быструю фиксированную арифметику или LUT
|
В микроконтроллерах функции из math.h (например sin(), cos(), sqrt(), pow()) работают очень медленно, потому что:
Нет FPU (Floating Point Unit)
На большинстве MCU (AVR, STM8, PIC, маленькие ARM Cortex-M0/M0+) нет аппаратного блока для операций float/double.
Значит — все операции выполняются программно, огромным количеством инструкций.
sin(x) может занимать сотни–тысячи тактов (1000–3000+ тактов).
Что лучше делать в embedded
LUT — таблицы значений (Look-Up Table). Скорость: O(1), одна операция чтения.
Например, если нужен sin() для 0…360°, делают:
static const int16_t sin_table_q15[360] = {
0, 572, 1144, 1716, 2287, 2858, 3429, 3999,
4569, 5138, 5707, 6275, 6842, 7408, 7974, 8538,
9102, 9664, 10225, 10785, 11343, 11899, 12454, 13007,
// ...
32767, // max
// ... дальше убывает обратно до 0
};
// Быстрая функция синуса (Разница с math.h в 300–1000 раз быстрее.)
// angle: 0..359
int16_t fast_sin_q15(uint16_t angle) {
return sin_table_q15[angle % 360];
}
Использование:
uint16_t a = 45; // 45°
int16_t s = fast_sin_q15(a); // → 23170 ~ 0.7071 в Q15
// если нужен float:
float sf = s / 32768.0f; // → 0.707
Fixed-point arithmetic (фиксированная точка)
Вместо float использовать числа типа:
- Q15 (1.15)
- Q31 (1.31)
- кастомные форматы
// Q15 fixed point: 1.0 == 32768
int16_t mul_q15(int16_t a, int16_t b) {
return (int32_t)a * (int32_t)b >> 15;
}
- Все операции — целочисленные, а значит быстрые и дешёвые.
- Часто точности достаточно для embedded (PWM, фильтры, сенсоры).
Вот реально быстрый sqrt() для fixed-point, который используют в embedded, DSP и микроконтроллерах без FPU.
Два варианта:
- целочисленный fast inverse sqrt + умножение (ещё быстрее)
- Q16.16 (очень популярный формат)
Пример Fixed-point arithmetic таблица + интерполяция
#include <stdint.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
uint32_t invsqrt_q16(uint32_t x) {
float xf = x / 65536.0f;
float half = 0.5f * xf;
int32_t i = *(int32_t *)&xf;
i = 0x5f3759df - (i >> 1); // магия Quake
float y = *(float *)&i;
// одна итерация Ньютона
y = y * (1.5f - half * y * y);
return (uint32_t)(y * 65536.0f);
}
uint32_t sqrt_fast_q16(uint32_t x) {
uint32_t inv = invsqrt_q16(x); // 1/√x в Q16.16
uint64_t t = (uint64_t)x * inv; // x * 1/√x = √x
return (uint32_t)(t >> 16); // обратно в Q16.16
}
int main(void){
uint32_t x = 9 << 16; // 9.0
uint32_t r = sqrt_fast_q16(x);
printf("sqrt ≈ %f\n", r / 65536.0); // ≈ 3.0
return EXIT_SUCCESS;
}
Быстрый sqrt для Q16.16 через целочисленный бинарный поиск
Q16.16: число — это 32 бита
старшие 16 = целая часть
младшие 16 = дробная
Например:
Реализация sqrt (Q16.16 → Q16.16)
#include <stdint.h>
uint32_t sqrt_q16(uint32_t x) {
uint32_t r = 0;
uint32_t bit = 1u << 30; // стартуем с 2^30
// подгоняем bit
while (bit > x)
bit >>= 2;
while (bit != 0) {
if (x >= r + bit) {
x -= r + bit;
r = (r >> 1) + bit;
} else {
r >>= 1;
}
bit >>= 2;
}
return r; // результат в Q16.16
}
int main(){
uint32_t a = 4 << 16; // 4.0 в Q16.16
uint32_t r = sqrt_q16(a);
printf("sqrt = %f\n", r / 65536.0); // → 2.0
return 0;
}
|
|
Функция с переменным количеством параметров
Вы должны выполнить следующие действия.
- Подготовить прототип функции, в котором применяется троеточие.
- Создать в определении функции переменную типа va_list.
- Использовать макрос va_start для инициализации этой переменной списком аргументов.
- Применить макрос va_arg для доступа к списку аргументов.
- Использовать макрос va_end для очистки.
|
Функция должна иметь хотя бы один именованный параметр, который обычно указывает количество передаваемых аргументов или их тип.
Нет проверки типов - компилятор не может проверить соответствие типов передаваемых аргументов.
#include <stdarg.h> // va_list, va_start, va_end, va_arg
#include <stdio.h>
#include <limits.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Макрос скрывает терминатор (флаг конца аргументов) от пользователя
#define SUM(...) sum_with_sentinel(__VA_ARGS__, INT_MIN)
int sum_with_sentinel(int first, ...) {
int result = first;
va_list args;
va_start(args, first);
int value;
while (1) {
value = va_arg(args, int);
if (value == INT_MIN) break;
result += value;
}
va_end(args);
return result;
}
int main(void){
// Теперь можно вызывать без явного терминатора
printf("%d\n", SUM(10, 20, 30)); // 60
printf("%d\n", SUM(1, 2, 3, 4, 5)); // 15
printf("%d\n", SUM(0)); // 0
// Любое количество аргументов
printf("%d\n", SUM(1, 2)); // 3
printf("%d\n", SUM(1)); // 1 (только первый аргумент)
return EXIT_SUCCESS;
}
|
|
|
|
|
Применение: Таблицы функций / диспетчеризация
|
Как виртуальная таблица в Rust/C++:
typedef struct {
int (*open)(const char*);
int (*close)(int);
int (*read)(int, void*, size_t);
} FileDriver;
Можно подставлять разные драйверы: FAT32, EXT4, виртуальные файлы…
|
|
|
Это позволяют хранить, передавать и вызывать функции как данные — почти как функции высшего порядка в Rust или callbacks в C++.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
int add(int a, int b) {
return a + b;
}
int main(void){
int (*func_ptr)(int, int) = add;
int result = func_ptr(2, 3); // или = (*func_ptr)(2, 3);
printf("%d",result);
return EXIT_SUCCESS;
}
|
|
Указатель на функцию как параметр
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
void process(int (*handler)(int), int x) {
printf("%d\n", handler(x));
}
// Через typedef проще синтаксис
typedef int (*Handler)(int);
void process2(Handler handler, int x) {
printf("%d\n", handler(x));
}
int main(void){
int square(int x) { return x*x; }
process(square, 5); // 25
process2(square, 5); // 25
return EXIT_SUCCESS;
}
|
|
Применение: Колбэки (callback)
|
Применение: Колбэки (callback)
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
// Callback — функция сравнения двух чисел
int cmp_int(const void* a, const void* b) {
int x = *(const int*)a;
int y = *(const int*)b;
return x - y; // если > 0, переставить
}
int main(void){
int arr[] = { 5, 2, 9, 1, 3 };
size_t n = sizeof(arr) / sizeof(arr[0]);
// Передаём указатель на функцию cmp_int
qsort(arr, n, sizeof(int), cmp_int);
// определение qsort ожидает указатель на функцию
// typedef int (*__compar_fn_t) (const void *, const void *);
for (size_t i = 0; i < n; ++i) {
printf("%d ", arr[i]);
}
printf("\n");
return EXIT_SUCCESS;
}
|
|
Применение: Реализация полиморфизма (как в ООП)
В C нет классов, но можно сделать виртуальные методы как в C++
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
typedef struct {
void (*speak)(void);
} Animal;
void dog_speak() { printf("Woof!\n"); }
void cat_speak() { printf("Meow!\n"); }
int main(void){
Animal dog = { dog_speak };
Animal cat = { cat_speak };
dog.speak(); // Woof!
cat.speak(); // Meow!
// Выбор поведения во время выполнения
cat.speak = dog_speak;
cat.speak();
return EXIT_SUCCESS;
}
|
|
Полноценный ООП полиморфизм
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE, exit
// Универсальная VTable для Animal ----------
typedef struct AnimalVTable {
void (*speak)(void* self);
void (*destroy)(void* self);
} AnimalVTable;
// Базовый "класс" Animal -------------------
typedef struct Animal {
const AnimalVTable* vtable;
} Animal;
// Универсальный API: работает с Animal*, но вызывает методы конкретного типа
void Animal_speak(Animal* a) {
a->vtable->speak(a);
}
void Animal_destroy(Animal* a) {
a->vtable->destroy(a);
free(a);
}
//Подкласс Dog ------------------------------
typedef struct {
Animal base;
const char* name;
} Dog;
void Dog_speak(void* self) {
Dog* d = (Dog*)self;
printf("%s says: Woof!\n", d->name);
}
void Dog_destroy(void* self) {
// для примера — тут могли бы быть ресурсы
Dog* d = (Dog*)self;
printf("Dog_destroy %s\n", d->name);
}
AnimalVTable Dog_vtable = {
.speak = Dog_speak,
.destroy = Dog_destroy
};
Dog* Dog_new(const char* name) {
Dog* d = malloc(sizeof(Dog));
d->base.vtable = &Dog_vtable;
d->name = name;
return d;
}
// Подкласс Cat ----------------------------
typedef struct {
Animal base;
int age;
} Cat;
void Cat_speak(void* self) {
Cat* c = (Cat*)self;
printf("Cat age %d says: Meow!\n", c->age);
}
void Cat_destroy(void* self) {
// для примера — тут могли бы быть ресурсы
Cat* c = (Cat*)self;
printf("Dog_destroy %d\n", c->age);
}
AnimalVTable Cat_vtable = {
.speak = Cat_speak,
.destroy = Cat_destroy
};
Cat* Cat_new(int age) {
Cat* c = malloc(sizeof(Cat));
c->base.vtable = &Cat_vtable;
c->age = age;
return c;
}
int main(void){
Animal* a1 = (Animal*)Dog_new("Rex");
Animal* a2 = (Animal*)Cat_new(3);
Animal_speak(a1); // Rex says: Woof!
Animal_speak(a2); // Cat age 3 says: Meow!
Animal_destroy(a1);
Animal_destroy(a2);
return EXIT_SUCCESS;
}
|
|
Полноценный ООП полиморфизм
Никакой динамической аллокации → детерминированность и предсказуемость
|
// embedded_polymorphism.c
// Никакой динамической аллокации → детерминированность и предсказуемость.
#include <stdio.h>
#include <string.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
/* ====== VTable (интерфейс) ====== */
typedef struct AnimalVTable {
void (*speak)(void* self);
void (*tick)(void* self); // демонстрация нескольких методов
} AnimalVTable;
/* ====== Базовый "класс" ====== */
typedef struct {
const AnimalVTable* vtable;
} Animal;
/* Утилиты для вызова методов полиморфно */
static inline void Animal_speak(Animal* a) {
a->vtable->speak(a);
}
static inline void Animal_tick(Animal* a) {
a->vtable->tick(a);
}
/* ====== Класс Dog (без malloc) ====== */
typedef struct {
Animal base; // обязательно в начале
const char* name;
} Dog;
static void Dog_speak(void* self) {
Dog* d = (Dog*)self;
printf("%s: Woof!\n", d->name);
}
static void Dog_tick(void* self) {
(void)self;
/* пример: ничего не делаем, но реализация есть */
}
/* единственный vtable для Dog */
static const AnimalVTable Dog_vtable = {
.speak = Dog_speak,
.tick = Dog_tick
};
/* init — не аллоцирует, а инициализирует память, выделенную вызывающим */
static inline void Dog_init(Dog* d, const char* name) {
d->base.vtable = &Dog_vtable;
d->name = name;
}
/* ====== Класс Cat (без malloc) ====== */
typedef struct {
Animal base;
int age;
} Cat;
static void Cat_speak(void* self) {
Cat* c = (Cat*)self;
printf("Cat(age=%d): Meow!\n", c->age);
}
static void Cat_tick(void* self) {
Cat* c = (Cat*)self;
/* демонстрация — увеличиваем возраст на "тик" */
c->age += 1;
}
/* vtable для Cat */
static const AnimalVTable Cat_vtable = {
.speak = Cat_speak,
.tick = Cat_tick
};
static inline void Cat_init(Cat* c, int age) {
c->base.vtable = &Cat_vtable;
c->age = age;
}
/* ====== Пример: статический пул (фабрика без malloc) ====== */
#define POOL_DOGS 2
#define POOL_CATS 2
static Dog dogs_pool[POOL_DOGS];
static int dogs_used[POOL_DOGS];
static Dog* dog_pool_alloc(const char* name) {
for (int i = 0; i < POOL_DOGS; ++i) {
if (!dogs_used[i]) {
dogs_used[i] = 1;
Dog_init(&dogs_pool[i], name);
return &dogs_pool[i];
}
}
return NULL; // нет свободных
}
static void dog_pool_free(Dog* d) {
int idx = (int)(d - dogs_pool);
if (0 <= idx && idx < POOL_DOGS) dogs_used[idx] = 0;
}
/* ====== main — демонстрация использования ====== */
int main(void) {
/* 1) Локальные объекты (на стеке) */
Dog stack_dog;
Dog_init(&stack_dog, "Rex");
Cat stack_cat;
Cat_init(&stack_cat, 3);
Animal* zoo1[] = {
(Animal*)&stack_dog,
(Animal*)&stack_cat
};
printf("=== Stack objects ===\n");
for (size_t i = 0; i < sizeof(zoo1)/sizeof(zoo1[0]); ++i) {
Animal_speak(zoo1[i]);
Animal_tick(zoo1[i]);
}
/* tick увеличил возраст кота */
Animal_speak(zoo1[1]); // покажет возраст 4
/* 2) Статический пул (без malloc) */
printf("\n=== Pool objects ===\n");
Dog* pd1 = dog_pool_alloc("Fido");
Dog* pd2 = dog_pool_alloc("Buddy");
Dog* pd3 = dog_pool_alloc("Overflow"); // NULL, пул небольшой
Animal* zoo2[3];
zoo2[0] = (Animal*)pd1;
zoo2[1] = (Animal*)pd2;
zoo2[2] = (Animal*)pd3; // может быть NULL
for (int i = 0; i < 3; ++i) {
if (zoo2[i]) {
Animal_speak(zoo2[i]);
} else {
printf("zoo2[%d] = NULL (no object)\n", i);
}
}
/* освобождение в пуле */
if (pd1) dog_pool_free(pd1);
if (pd2) dog_pool_free(pd2);
/* 3) Полиморфизм в массиве разных типов */
printf("\n=== Mixed zoo (stack + pool) ===\n");
Animal* mixed[4];
mixed[0] = (Animal*)&stack_dog;
mixed[1] = (Animal*)&stack_cat;
mixed[2] = (Animal*)dog_pool_alloc("Spike");
mixed[3] = (Animal*)&stack_cat; // reuse
for (int i = 0; i < 4; ++i) {
if (mixed[i]) Animal_speak(mixed[i]);
}
/* если в пуле были объекты — явно "освобождаем" */
if (mixed[2]) dog_pool_free((Dog*)mixed[2]);
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
Компиляторы С позволяют функции main() либо main(void) не принимать аргументов либо иметь два аргумента.
|
|
передача данных в программу
int main(int argc, char *argv[]){...
или
int main(int argc, char **argv){...
- argc - это количество переданных аргументов
- argv - значения аргументов
некоторые OS элементу argv[0] присваивается имя самой программы
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(int argc, char *argv[]){ // или int main(int argc, char **argv){
printf("Количество аргументов, указанных в командной строке: %d\n", argc - 1);
for (int i = 1; i < argc; i++){
printf("%d: %s\n", i, argv[i]);
}
printf (" \n" );
return EXIT_SUCCESS;
}
./my_program.out -r Ginger
Количество аргументов, указанных в командной строке: 2
1: -r
2: Ginger
|
|
Макросы для работы со списком аргументов:
va_start(), va_arg(), va_copy(), va_end()
Библиотека: stdarg.h
Важные ограничения переменных аргументов
- невозможно узнать количество аргументов без протокола
- нет типов — нужно знать заранее
- не работать с нестандартными типами (struct) без ABI-хаков
- часто запрещено в embedded
|
va_start(ap, last_named_arg) - Инициализирует список.
va_arg(ap, type) - Извлекает следующий аргумент указанного типа.
va_copy(dest, src) - Создаёт копию списка аргументов — редко нужно.
va_end(ap) - Закрывает список (обязателен!)
Собственная мини-printf
#include <stdarg.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void print_values(const char* fmt, ...) {
va_list args;
va_start(args, fmt);
while (*fmt) {
if (*fmt == 'd') {
int v = va_arg(args, int);
printf("%d ", v);
} else if (*fmt == 'f') {
double v = va_arg(args, double);
printf("%f ", v);
}
fmt++;
}
va_end(args);
}
int main(void){
print_values("dfd", 10, 2.5, 42);
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
Определение endianness (порядка байтов в памяти) в runtime:
|
int is_little_endian() {
int x = 1;
return *(char*)&x; // Вернёт 1 на LE, 0 на BE
}
|
|
|
Никогда не выполняйте сдвиг вправо над значением со знаком.
Существуют два средства, помогающие манипулировать битами.
Первое — это набор из шести побитовых операций, которые воздействуют на биты (4 логические операции и 2 операции сдвига)
Второе средство — это форма полей данных, которая предоставляет доступ к битам внутри значения int.
Особенности языка C
Арифметический или логический сдвиг. Сдвиг чисел со знаком вправо с помощью операции >> может быть арифметическим (копия знакового бита размножается в процессе сдвига) или логическим (освобождаемые при сдвиге биты замещаются нулями).
Порядок байтов. Порядок следования байтов в типах short, int и long не определен; байт с самым низким адресом может оказаться как младшим, так и старшим значащим байтом. Это зависит от аппаратуры компьютера.
Выравнивание членов структур и классов. Выравнивание составных элементов внутри структур, Классов и объединений не определено полностью; единственное, что сказано по этому поводу, — элементы должны следовать в порядке их объявления. Никогда не следует предполагать, что элементы структуры занимают непрерывную область памяти. Наличие таких "дыр" подразумевает, что структура в целом может занимать больше места, чем сумма длин ее элементов, причем ее длина может варьироваться от одной системы к другой. При динамическом распределении памяти для такой структуры следует запрашивать sizeof(struct X) байт, а не sizeof(char) + sizeof(int).
В ней элемент i может иметь смещение 2, 4 или 8 байт от начала структуры.
Некоторые системы позволяют размещать переменные типа int по нечетным адресам, но большинство требует, чтобы элемент типа, состоящего из n байт, помещался по адресу, кратному n.
struct X {
char с;
int i;
};
|
|
Представление целых чисел со знаком (дополнение до двух)
|
Представление целых чисел со знаком определяется оборудованием, а не языком С.
Беззнаковые числа выглядят одинаково.
Процессор аппаратно реализует арифметические операции, и язык C просто использует эти возможности.
x86/x64 (большинство компьютеров):
// Используют дополнение до двух
int8_t num = -5; // В памяти: 11111011
Устаревшие системы (некоторые мейнфреймы):
// Могли использовать прямой код или обратный код
int8_t num = -5; // Возможно: 10000101 (прямой код)
Алгоритм получения отрицательного числа:
- перевести положительное число в двоичную систему
- потом поменять нули на единицы и единицы на нули
- затем прибавить к результату 1
Например для -125
- положительное 125 в двоичной системе: 01111101
- реверс : 10000010
- прибавить 1 : 10000011
Можно проверить:
- 256 - 125 = 131 в двоичном виде 10000011 что соответствует двоичному представлению для отрицательно числа -125
+5: 00000101
Инвертируем: 11111010 (обратный код)
Добавляем 1: 11111011 ← это -5 в дополнении до двух
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
int8_t positive = 5;
int8_t negative = -5;
printf("+5 в двоичном: ");
for (int i = 7; i >= 0; i--) {
printf("%d", (positive >> i) & 1);
}
printf("\n");
printf("-5 в двоичном: ");
for (int i = 7; i >= 0; i--) {
printf("%d", (negative >> i) & 1);
}
printf("\n");
// Проверка сложения
printf("5 + (-5) = %d\n", positive + negative);
return EXIT_SUCCESS;
}
/*
+5 в двоичном: 0000 0101
-5 в двоичном: 1111 1011
5 + (-5) = 0
*/
Получение отрицательного числа:
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void) {
printf("\n");
printf("5 в двоичном виде:");
signed char positive = 5;
for (int i = 7; i >= 0; i--) {
printf("%d", (positive >> i) & 1);
}
printf("\n");
printf("Инфертированная 5:");
int invert = ~positive;
for (int i = 7; i >= 0; i--) {
printf("%d", (invert >> i) & 1);
}
printf("\n");
printf("Прибавляем 1 :");
invert = invert + 1;
for (int i = 7; i >= 0; i--) {
printf("%d", (invert >> i) & 1);
}
printf("\n");
printf("Результат :%d\n",invert);
return EXIT_SUCCESS;
}
5 в двоичном виде: 00000101
Инвертированная 5: 11111010
Прибавляем 1 : 11111011
Результат : -5
|
|
4 логические побитовых операции
|
Они называются побитовыми потому, что выполняются над каждым битом независимо от бита, находящегося слева или справа.
1. Дополнение до единицы или побитовое отрицание: ~
Унарная операция - преобразует к а ж д у ю единицу в ноль, а каждый ноль в единицу:
5 в двоичном виде:00000101
Инвертированная 5: ~(00000101) = 01100101
int invert = ~5;
2. Побитовая операция AND: &
Побитово сравнивает два бита между собой, результат новое значение 1 если оба бита установлены в 1, иначе результат 0
int and = 1001 & 0001 = 0001
Доступна операция `&=`
and &= 0001; // аналогично and = and & 0001;
3. Побитовая операция OR: |
Побитово сравнивает два бита между собой, результат новое значение 1 если одно из значений 1, иначе результат 0
int or = 1001 & 0001 = 1001
Доступна операция `|=`
or |= 0001; // аналогично or = or | 0001;
4. Побитовое исключающее OR т.е. XOR: ^
Для каждой позиции результирующий бит будет равен 1, если один или другой (но не оба) из соответствующих битов в операндах равен 1.
int xor = 1001 & 0001 = 1000
Доступна операция `^=`
xor ^= 0001;
|
|
2 операции сдвига влево << и вправо >>
(процесс извлечения группы битов называется маскированием поля (Field Masking))
|
Целочисленные Операнды: Операции сдвига применяются только к целочисленным операндам.
Если сдвиг отрицательный или больше чем ширина типа, то это приводит к неопределенное поведение (UB).
- на одном компьютере программа может выдать 0.
- на другом — оставить число прежним.
- на третьем — вообще сломаться.
1. Сдвиг влево (<<)
- Сдвигает все биты первого операнда влево на количество позиций, указанное вторым операндом.
- Новые битовые позиции, освободившиеся справа, всегда заполняются нулями (логический сдвиг).
- Сдвиг влево на
N позиций эквивалентен умножению числа на 2^N (пока не произойдет переполнение).
a=5 // 00000101
b=a << 2 = 5 * 2^2 = 20 // 00010100
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void){
uint8_t a = 13; // 0000 1101
int k = 10;
// 1. ОПАСНЫЙ ВАРИАНТ (Undefined Behavior)
// В C сдвиг на число >= разрядности типа — это неопределенное поведение.
// Может быть сдвиг по модулю:
// Число сдвига считается так:
// k = 10; то на сколько мы хотели сдвинуть
// w - это разряд числа, для uint8_t это 8, для uint16_t это 16, для int это 32
// k = k % w
// На x86 это скорее всего даст 13 << (10 % 8) = 52, но верить этому нельзя.
uint8_t risky = a << k;
printf("Risky shift: %u\n", risky);
// 2. БЕЗОПАСНЫЙ ВАРИАНТ 1: Эмуляция "Wrapping" (как в Rust)
// Мы сами явно берем остаток от деления.
uint8_t w = sizeof(a) * 8; // получаем 8
uint8_t wrap = a << (k % w);
printf("Safe wrapping: %u (binary: 00110100)\n", wrap);
// 3. БЕЗОПАСНЫЙ ВАРИАНТ 2: Эмуляция "Saturating" (уход в 0)
// Если сдвиг слишком большой — возвращаем 0.
uint8_t sat = (k >= w) ? 0 : (a << k);
printf("Safe saturating: %u\n", sat);
return EXIT_SUCCESS;
}
2. Сдвиг вправо (>>)
- Сдвигает все биты первого операнда вправо на количество позиций, указанное вторым операндом.
- Для беззнаковых типов (unsigned int, unsigned char и т.д.): Новые битовые позиции, освободившиеся слева, всегда заполняются нулями (логический сдвиг).
- Для знаковых типов (int, char и т.д.): Поведение зависит от реализации.
- Арифметический сдвиг: Битовые позиции заполняются знаковым битом (0 для положительных, 1 для отрицательных). Это сохраняет знак числа и эквивалентно делению на
2^N
- Логический сдвиг: Битовые позиции заполняются нулями.
- Сдвиг вправо на
N позиций эквивалентен делению числа на 2^N (с отбрасыванием дробной части).
b=20 // 00010100
a=b >> 2 = 20/2^2 = 5 // 00000101
Два возможных варианта для знаковых типов signed !!!:
- 1. Арифметический сдвиг (чаще всего, добавляется слева т.е. в старшую позицию копию старшего бита знака 0 или 1):
-8 >> 1 = -4
Что происходит бинарно (8-битный пример):
-8: 11111000 (дополнение до двух)
>>1: 11111100 = -4 (копируется старший бит)
- 2. Логический сдвиг (редко, слева добавляется старший бит 0 всегда):
-8 >> 1 = 124 (для 8-бит) или большие числа для 32-бит
Что происходит бинарно (8-битный пример):
-8: 11111000
>>1: 01111100 = 124 (добавляется 0 слева)
Операции сдвига часто используются для:
- Быстрого Умножения/Деления: Заменяют медленные операции умножения/деления на степени двойки.
- Установки/Сброса/Проверки Бита: Используются в комбинации с другими побитовыми операциями (
&, |, ^, ~) для манипуляции отдельными битами.
Например, (1 << n) создает число, где установлен только n-й бит
1 << 2 = 4 00000100
1 << 3 = 8 00001000
1 << 4 = 16 00010000
1 << 5 = 32 00100000
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
void binary_show(int digit){
for (int i = 7; i >= 0; i--) {
printf("%d", (digit >> i) & 1);
}
}
int main(void) {
int digit = 2;
printf("1 << %d = %d ",digit,1 << digit);
binary_show(1 << digit);
digit = 3;
printf("\n");
printf("1 << %d = %d ",digit,(1 << digit));
binary_show(1 << digit);
digit = 4;
printf("\n");
printf("1 << %d = %d ",digit,1 << digit);
binary_show(1 << digit);
digit = 5;
printf("\n");
printf("1 << %d = %d ",digit,1 << digit);
binary_show(1 << digit);
return EXIT_SUCCESS;
}
|
|
Операторы <<= и >>= — это сдвиг с присваиванием
|
<<= — левый сдвиг с присваиванием
- Сдвигает все биты x влево на n позиций.
- Новые правые биты заполняются нулями.
Используется для:
- Умножения на степени двойки (
x << 3 = x * 8)
- Формирования битовых масок
- Работа с регистрами в embedded
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main() {
unsigned int x = 3; // 00000011
x <<= 2; // сдвигаем на 2 бита влево. Эквивалентно x = x << 2;
printf("%u\n", x); // 12 (00001100)
return EXIT_SUCCESS;
}
>>= — правый сдвиг с присваиванием
- Сдвигает все биты x вправо на n позиций.
- Для беззнаковых типов новые левые биты заполняются нулями.
- Для знаковых типов может выполняться арифметический сдвиг (зависит от компилятора) — старший бит (знак) сохраняется.
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main() {
unsigned int x = 12; // 00001100
x >>= 2; // сдвигаем на 2 бита вправо
printf("%u\n", x); // 3 (00000011)
return EXIT_SUCCESS;
}
Используется для:
- Деления на степени двойки (
x >> 3 = x / 8)
- Извлечения отдельных битов
- Работа с регистрами и флагами
|
|
Битовые поля — это способ упаковать множество булевых флагов в минимальное место
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Битовые поля — это способ упаковать множество булевых флагов в минимальное место.
// Каждое поле = 1 бит, а не 4 байта (int).
// Недостатки:
// * не переносима между разными компиляторами. Компилятор может: упаковывать слева направо или справа налево, менять порядок в зависимости от архитектуры, вставлять паддинг
// * Не работает с memcpy(...) между системами. Из-за различий в порядке бит.
// * Медленнее чем ручные маски
// * Нельзя брать адрес битового поля
struct {
unsigned int autfd: 1;// 1 бит
unsigned int bldfc: 1;// 1 бит
unsigned int undln: 1;// 1 бит
unsigned int itals: 1;// 1 бит
// + еще биты выравнивания до unsigned int т.е. 4 байта. Если число полей будет больше чем 32, например 33 то размер станет 8 байт
} prnt;
int main(void) {
printf("sizeof=%ld byte\n", sizeof(prnt));// 4 байта
prnt.undln = 0; // или 1
printf("undln=%d\n", prnt.undln);// 0
return EXIT_SUCCESS;
}
/*
Как правильно делать "битовые флаги" в embedded
uint32_t flags = 0;
#define FLAG_BOLD (1u << 0)
#define FLAG_ITALIC (1u << 1)
#define FLAG_UNDERLINE (1u << 2)
flags |= FLAG_BOLD;
flags &= ~FLAG_ITALIC;
if (flags & FLAG_BOLD) { ... }
Преимущества:
* полностью переносимо
* очень быстро
* легко контролировать биты
* легко передавать по сети/в файлы
*/
|
|
Работа с флагами и настройками
|
// Флаги устройств (каждый бит = отдельная настройка)
#define FLAG_A (1 << 0) // 0b00000001
#define FLAG_B (1 << 1) // 0b00000010
#define FLAG_C (1 << 2) // 0b00000100
unsigned int settings = FLAG_A | FLAG_C; // 0b00000101
// Проверка флага
if (settings & FLAG_A) {
// Флаг A установлен
}
// Извлечение группы флагов
unsigned int extracted = getbits(settings, 2, 2); // Флаги B и C
|
|
Порядок следования байтов (endianness)
В различных системах объекты длиннее одного байта уже могут представляться по-разному, поэтому полагаться на их специфические свойства нельзя. Например, в коротком целом числе (short int, обычно 16 бит или 2 байта) младший байт может помещаться по меньшему адресу, чем старший (так называемый "остроконечный" принцип, "little-endian"), или по большему адресу ("тупоконечный" принцип, "big-endian"). Этот выбор довольно произволен, а некоторые системы даже поддерживают обе модели. Если необходимо послать целое число по параллельному соединению шириной в один байт, например по сетевому кабелю, мы должны выбрать, какой байт посылать первым. Тут-то и возникает главный вопрос— выбор между "тупоконечниками" и "остроконечниками".
Этот подход используется в сетевых протоколах (например, TCP/IP использует big-endian) и форматах файлов для обеспечения переносимости.
Язык Java поддерживает более высокий уровень абстрагирования, чем С или C++, так что в нем вопросы порядка байтов вообще скрыты от программиста. В библиотеках имеется интерфейс Serializable, который задает правила для пакетирования элементов данных с целью обмена или пересылки.
|
Используйте фиксированный порядок байтов для обмена данными. И все таки решение существует. Запишите байты в каноническом порядке, используя переносимый код:
// Запись (сериализация) Всегда записывает байты в порядке: старший → младший
unsigned short x;
putchar(x >> 8); /* запись старшего байта */
putchar(x & OxFF); /* запись младшего байта */
// Чтение (десериализация) Всегда читает байты в том же порядке: старший → младший
// Затем считайте их обратно по одному и снова соберите в единое целое:
unsigned short x;
х = getchar() << 8; /* чтение старшего байта */
х |= getchar() & OxFF; /* чтение младшего байта */
Этот подход обобщается и на структуры, если записывать их элементы в определенном порядке, по одному байту и без добавления заполнителей. Неважно, какой именно порядок байтов выбран; важно лишь единообразие. Единственное требование заключается в том, чтобы отправитель и получатель согласовали между собой порядок байтов при передаче и количество байтов в каждом объекте.
|
|
Кодирование (упаковка) данных в ограниченное пространство
|
// Упаковка RGB цвета в 16 бит (5-6-5)
unsigned short pack_rgb565(int r, int g, int b) {
return ((r & 0x1F) << 11) | ((g & 0x3F) << 5) | (b & 0x1F);
}
// Извлечение компонентов
int get_red(unsigned short color) {
return getbits(color, 15, 5); // Биты 15-11
}
|
|
|
// Декомпрессия с переменной длиной кодов
unsigned int read_variable_code(unsigned int bitstream, int *position, int length) {
int code = getbits(bitstream, *position, length);
*position += length;
return code;
}
|
|
Еще где применяют битовые операции
|
Аппаратное программирование
// Чтение регистров устройств
unsigned int status_register = read_hardware_register();
// Проверка битов состояния
if (getbits(status_register, 7, 1)) { // Бит готовности
// Устройство готово
}
// Извлечение кода ошибки
int error_code = getbits(status_register, 3, 4); // Биты 3-0
Сетевые протоколы
// Разбор IP-пакета
unsigned int ip_header = receive_packet();
// Извлечение версии IP (первые 4 бита)
int ip_version = getbits(ip_header, 31, 4);
// Длина заголовка (биты 4-7)
int header_length = getbits(ip_header, 27, 4) * 4;
Криптография
// Извлечение частей ключа
unsigned int cryptographic_key = 0xABCD1234;
unsigned int key_part1 = getbits(cryptographic_key, 31, 16);
unsigned int key_part2 = getbits(cryptographic_key, 15, 16);
|
|
Не следует пользоваться битовыми полями
|
Не следует пользоваться битовыми полями С и C++; они очень плохо переносимы и приводят к генерированию слишком громоздкого кода. Вместо этого следует инкапсулировать требуемые операции в функциях, которые бы устанавливали или запрашивали отдельные биты машинного слова или массива слов с помощью операций поразрядного маскирования и сдвига.
Проблемы битовых полей:
- Порядок битов зависит от компилятора/архитектуры
- Размер поля может отличаться
- Выравнивание добавляет лишние биты
- Код получается медленнее (компилятор генерирует сложные инструкции)
Плохо: битовые поля (bit fields)
// НЕПЕРЕНОСИМО!
struct Flags {
unsigned int flag1 : 1; // 1 бит
unsigned int flag2 : 3; // 3 бита
unsigned int flag3 : 2; // 2 бита
};
struct Flags f;
f.flag1 = 1; // ❌ Расположение битов зависит от компилятора!
✅ Хорошо: битовые операции
// ПЕРЕНОСИМО!
#define FLAG1_MASK (1 << 0) // 0b00000001
#define FLAG2_MASK (0x7 << 1) // 0b00001110
#define FLAG3_MASK (0x3 << 4) // 0b00110000
unsigned int flags = 0;
// Установка флагов
flags |= FLAG1_MASK; // Установить flag1
flags = (flags & ~FLAG2_MASK) | (2 << 1); // Установить flag2 = 2
// Проверка флагов
if (flags & FLAG1_MASK) { /* ... */ }
// Извлечение значения
int flag2_value = (flags & FLAG2_MASK) >> 1;
Пример из реальной жизни:
// Вместо:
struct Packet {
unsigned int version : 4;
unsigned int header_len : 4;
unsigned int service_type : 8;
};
// Лучше:
unsigned int packet_header;
#define VERSION(header) (((header) >> 28) & 0xF)
#define HEADER_LEN(header) (((header) >> 24) & 0xF)
#define SET_VERSION(header, ver) ((header) = ((header) & 0x0FFFFFFF) | ((ver) << 28))
|
|
Не следует пользоваться битовыми полями
|
Выборка части битовой последовательности
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
/*
x = 0b11010110 (214)
p = 5, n = 3
Биты : 1 1 0 1 0 1 1 0
Позиция: 7 6 5 4 3 2 1 0
↑ ↑ ↑
p=5, берем 3 бита: позиции 5,4,3
Значения битов:
позиция 5: 0
позиция 4: 1
позиция 3: 0
Результат: 0b010 = 2
*/
// Функция getbits извлекает n битов из числа x, начиная с позиции p
// биты нумеруются с 0, начиная с младших
unsigned int getbits(unsigned int x, int p, int n){
return (x >> (p + 1 - n)) & ~(~0U << n);
}
// или так
unsigned int getbits_alt(unsigned int x, int p, int n) {
unsigned int mask = (1U << n) - 1; // Создаем маску n единиц
return (x >> (p - n + 1)) & mask; // Сдвигаем и применяем маску
}
void print_binary(unsigned int num) {
for (int i = 31; i >= 0; i--) {
printf("%d", (num >> i) & 1);
if (i % 4 == 0) printf(" "); // Разделитель каждые 4 бита
}
printf("\n");
}
int main(void){
// для 214
print_binary(214);// 0000 0000 0000 0000 0000 0000 1101 0110
// ↑↑ ↑
// 54 3
unsigned int result = getbits(214, 5, 3);
printf("result=%u\n", result); // = 2 (что соответствует 0b010)
result = getbits_alt(214, 5, 3);
printf("%u\n", result); // = 2 (что соответствует 0b010)
result = 2;
print_binary(result);// 0000 0000 0000 0000 0000 0000 0000 0010
// для 216
print_binary(216);// 0000 0000 0000 0000 0000 0000 1101 1000
result = getbits_alt(216, 5, 3);
printf("%u\n", result);// = 3 (что соответствует 0b011)
print_binary(3);// 0000 0000 0000 0000 0000 0000 0000 0011
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
МАКРОСЫ — это правило текстовой подстановки (препроцессор)
Макросы не выполняются, они разворачиваются на этапе препроцессинга (до компиляции) → компилятор видит уже подставленный код.
И это им позволяют изменять код, как будто это шаблоны.
Почему макросы опасны?
- Нет проверки типов
- Многократное вычисление аргумента
- Debug сложнее, отладчик не видит макросы.
- Ошибки трудно понимать. Они происходят после подстановки.
Макросы нужны только когда:
- шаблонный код (генерация
Result<T,E>)
- условная компиляция
- код для железа (регистр → один оператор)
- оптимизация (HEADER-ONLY API)
Специальные макросы C99
__FILE__ — имя файла
__LINE__ — номер строки
#line — директива позволяет переустанавливать нумерацию строки имя файла, выводимые с помощью макросов __LINE__ и __FILE__
__func__ — имя функции
__DATE__ — дата компиляции
__TIME__ — Время трансляции в форме "чч:мм:сс"
__STDC__ — Установлен в 1 для указания, что реализация соответствует стандарту С
__STDC_HOSTED_ — Установлен в 1 для размещаемой среды; в противном случае — 0
__STDC_VERSION__ — Для С99 установлен в 1999011; для С11 установлен в 201112L
printf("%ld\n",__STDC_VERSION__);// 199901
printf("Error at %s:%d\n", __FILE__, __LINE__);
|
|
Макросы для логирования, ошибок и ассершнов
|
#define LOG(msg) \
printf("[%s:%d] %s\n", __FILE__, __LINE__, msg)
#define ASSERT(x) \
if (!(x)) { printf("ASSERT FAIL: %s:%d\n", __FILE__, __LINE__); while(1); }
|
|
Важные операторы макросов
Оператор # и ##
Оператор ## склеивает только идентификаторы и их части.
То есть:
- ✔
func_ ## name → OK
- ✔
x ## 1 → OK
- ✔
my_ ## type → OK
Но:
❌ void ## name → НЕЛЬЗЯ, потому что void — это ключевое слово, не часть идентификатора.
|
1. Оператор строкизация # — превращает аргумент в строку
#define STR(x) #x
STR(123) → "123"
2. Оператор ## — конкатенация токенов объединяет две лексемы в одну.
#include <stdlib.h> // EXIT_SUCCESS
#define XNAME(n) x ## n
#define PRINT_XN(n) printf ("х" #n " = %d\n", x ## n);// кирилическая 'х' и латинска 'x' это разные символы :)
#define MAKE_FUNC(name) \
void func_##name(int n) { \
printf("%d\n", n); \
} \
void name(int n) { \
printf("%d\n", n); \
}
// определение функции
MAKE_FUNC(test);
int main(void) {
int XNAME(1) = 14; // превращается в int x1 = 14;
int XNAME(2) = 20; // превращается в int x2 = 20;
printf("%d %d",x1,x2);
PRINT_XN(1); // превращается в printf("x1 = %d\n", x1);
PRINT_XN(2); // превращается в printf("x2 = %d\n", x2);
func_test(5);
test(5);
return EXIT_SUCCESS;
}
|
|
#define — макросы
#undef — удалить макрос
Скобки в макросах — обязательно
Многострочные макросы (\)
|
Макрос-константа
#define PI 3.14159
#define BUFFER_SIZE 128
Макрос-функция
#define SQUARE(x) ((x) * (x))
#undef SQUARE
|
|
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define PI 3.14159
int main(void){
x = PI * r * r;
// Компилятор фактически увидит:
x = 3.14159 * r * r;
return EXIT_SUCCESS;
}
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define LENGTH_NAME 40
#define MY_TEXT "Женя" // компилятор сам добавит \0
//#define PI_F 3.1415926535897932384626433832795028841971f // float хранит 6–9 знаков после запятой
//#define PI_D 3.1415926535897932384626433832795028841971 // double хранит 15–17 знаков после запятой
//#define PI_LD 3.1415926535897932384626433832795028841971L // long double хранит 18–19 знаков после запятой
const float PI_F = 3.141593f;
const double PI_D = 3.141592653589793;
const long double PI_LD = 3.141592653589793239L;
int main(void) {
// по умолчанию printf/scanf выводит только 6 знаков после запятой
printf("%.6f\n",PI_F); // 3.141593
printf("%.15f\n", PI_D);// 3.141592653589793
printf("%.18Lf\n",PI_LD); // 3.141592653589793239
return EXIT_SUCCESS;
}
|
|
Макрос-функция
В отличие от inline-функций, макросы не проверяют типы, и дублируют аргументы, что приводит к ошибкам дваойной вызов getchar() например
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define SQR(x) ((x) * (x))
int main(void){
int r = SQR(5); // → ((5)*(5))
SQR(1 + 2) // → ((1 + 2)*(1 + 2)) = 9 // ок
SQR(a++) // опасно: многократное вычисление!
return EXIT_SUCCESS;
}
|
|
Макросы-многострочные
Макросы с вариативными аргументами (fmt, ...)
|
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// Чтобы избежать проблем при использовании макроса в сложных выражениях
// Конструкция do { ... } while(0) считается best practice для многострочных макросов в C, чтобы макрос подставлялся как одна инструкция.
// не указываем вконце - ; что бы при развертывании в многострочных конструкциях не ломался синтаксис
#define DEBUG_LOG(fmt, ...) do { \
printf("[%s:%d] ", __FILE__, __LINE__); \
printf(fmt, ##__VA_ARGS__); \
printf("\n"); \
} while(0)
int main(void) {
char *x = "message";
int digit = 9;
if (1){
// Использование
DEBUG_LOG("Variable x = %s", x);
DEBUG_LOG("Variable dig = %d", digit);
DEBUG_LOG("Function started");
}
else{
printf("something");
}
return EXIT_SUCCESS;
}
|
|
Макросы для условной компиляции
директивы препроцессора для условной компиляции
|
Файл config.h
#ifndef CONFIG_H
#define CONFIG_H
// Разные настройки для разных билдов
#ifdef DEBUG
#define LOG_LEVEL 3
#define ASSERT_ENABLED 1
#define BUFFER_SIZE 1024
#else
#define LOG_LEVEL 0
#define ASSERT_ENABLED 0
#define BUFFER_SIZE 4096
#endif
// Feature flags
#ifdef FEATURE_NETWORK
#define NETWORK_ENABLED 1
#else
#define NETWORK_ENABLED 0
#endif
#endif
Файл main.c
#include "config.h"
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
int main(void){
printf("%d", LOG_LEVEL);
printf("%d", ASSERT_ENABLED);
printf("%d", BUFFER_SIZE);
return EXIT_SUCCESS;
}
Передаем указание через флаги компилятора какие константы активировать
# Debug версия
gcc -DDEBUG -DFEATURE_NETWORK program.c -o program_debug
# Release версия
gcc -O2 -DNDEBUG program.c -o program_release
# Минимальная версия
gcc -DNDEBUG program.c -o program_minimal
|
|
X-macro
Что это даёт?
- enum и строки всегда синхронизированы
- исключает дублирование
- изменения происходят в одном месте
- идеально для embedded state-machine, протоколов, команд, ошибок
|
Это приём, когда данные хранятся в списке макросов, а код, который зависит от этих данных, генерируется автоматически.
Файл x-macro.h
// Создаём X-macro список — единственное место данных
#define COLOR_LIST \
X(RED) \
X(GREEN) \
X(BLUE)
// Генерируем enum
typedef enum {
#define X(name) name,
COLOR_LIST
#undef X
COLOR_COUNT
} Color;
//-----------------------
// X-macro список:
#define ERROR_LIST \
X(ERR_OK, 0, "No error") \
X(ERR_TIMEOUT, 1, "Timeout") \
X(ERR_OVERFLOW, 2, "Overflow") \
X(ERR_BAD_STATE, 3, "Bad state")
// Генерируем enum
typedef enum {
#define X(name, code, msg) name = code,
ERROR_LIST
#undef X
} ErrorCode;
Файл main.c
#include "x-macro.h"
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#include <stdio.h>
// Генерируем массив строк
static const char* Color_names[] = {
#define X(name) #name,
COLOR_LIST
#undef X
};
// Генерация массива сообщений:
static const char* Error_messages[] = {
#define X(name, code, msg) [code] = msg,
ERROR_LIST
#undef X
};
int main(void) {
Color c = GREEN;
printf("Color = %s\n", Color_names[c]); // "GREEN"
ErrorCode e = ERR_OVERFLOW;
printf("Error %d: %s\n", e, Error_messages[e]);// Error 2: Overflow
return EXIT_SUCCESS;
}
|
|
_Generic — выбирает реализацию по типу выражения (type switching)
Полиморфизм, на этапе компиляции.
Настоящая типовая диспетчеризация на этапе компиляции.
Обычный макрос так не может
|
Это аналог compile-time switch по типам.
Используется в C для реализации type-safe макросов, т.к. перегрузки (как в C++) нет.
Пример: перегрузка функций
#include <stdio.h>
#include <stdlib.h> /// EXIT_SUCCESS
// функция max подставляется в код по типу аргумента
#define max(a, b) \
_Generic((a), \
int: max_int, \
double: max_double, \
float: max_float \
)(a, b)
/* --- Реальные функции для каждого типа --- */
int max_int(int a, int b) {
return (a > b) ? a : b;
}
float max_float(float a, float b) {
return (a > b) ? a : b;
}
double max_double(double a, double b) {
return (a > b) ? a : b;
}
//--------------------------------------
// функция print подставляется в код по типу аргумента
#define print(x) _Generic((x), \
int: print_int, \
char*: print_str \
)(x)
/* --- Реальные функции для каждого типа --- */
void print_int(int x){
printf("%d\n",x);
}
void print_str(char* x){
printf("%s\n",x);
}
int main(void) {
int x = max(2, 3); // выбирает max_int
float y = max(2.1f, 3.5f); // выбирает max_float
double z = max(2.1, 3.5); // max_double
printf("%d %f %f\n",x,y,z);
print(1);
print("Hello");
return EXIT_SUCCESS;
}
|
|
|
|
|
|
|
|
|
Препроцессор — это этап перед компиляцией, который выполняет текстовые преобразования:
- включает файлы (#include)
- определяет макросы (#define)
- выбирает части кода (#if, #ifdef)
- защищает заголовки от повторного включения
- заменяет константы
- создаёт inline-функции через макросы
- позволяет писать переносимый код под разные платформы
|
|
#include — включение файлов
|
В 99% случаев правильный порядок подключения заголовков в C выглядит так:
-
Собственный заголовок модуля #include "my_header.h"
-
Публичные заголовки проекта #include "public_header.h"
-
Системные / стандартные заголовки #include <stdio.h>
-
Приватные заголовки модуля #include "private_header.h"
Порядок включения библиотек
Для системных заголовков. Компилятор будет искать файл в системных каталогах
#include <stdio.h>
Для своих файлов. Компилятор будет искать файл сперва локально, потом в системных каталогах
#include "my_header.h"
#include "foo/my_file.h"
#include "/usr/foo/file.h"
|
|
#ifdef / #ifndef — Условная компиляция
#if, #elif, #else, #endif
Их можно использовать для сообщения компилятору о том, принимать либо игнорировать блоки информации или кода согласно условиям на этапе компиляции.
|
Если есть определение DEBUG
#ifdef DEBUG
#include "test.h"
#define STABLES 5
#else
#include "test_2.h"
#define STABLES 6
#endif
//---------------------------------------------------------------------
Если еще нет такой константы то определить ее
#ifndef CONFIG_LOADED
#define CONFIG_LOADED // макрос-флаг просто существует
#endif
// #ifndef используется для предотвращения многократного включения файла, если этот код будет включен в другом месте еще раз то флаг THINGS_H уже будет существовать и внутрь компилятор не зайдет
// things.h
#ifndef THINGS_H
#define THINGS_H
// содержимое файла
#endif
//---------------------------------------------------------------------
Если иначе
#if VERSION == 2
...
#elif VERSION == 3
...
#else
...
#endif
#if defined (IBMPC)
#include "ibmpc.h"
#elif defined (VAX)
#include "vax.h"
#elif defined (МАС)
#include "mac.h"
#else
#include "general.h"
#endif
|
|
Include guards — обязательная практика
|
Предотвращает множественное включение.
В каждом своем файле .h:
#ifndef MY_HEADER_H
#define MY_HEADER_H
// Your declarations here
#endif
|
|
_Pragma - даёт компилятору специальные инструкции, не определённые стандартом C.
_Pragma - можно использовать в макросах
#pragma - нельзя использовать в макросах
|
Используется для управления поведением компилятора, например:
- подавление предупреждений
- выравнивание структур
- оптимизации
- предупреждения или сообщения во время компиляции
Пример подавление предупреждений через макрос
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
#define DISABLE_WARNING _Pragma("GCC diagnostic ignored \"-Wunused-variable\"")
int main(void) {
DISABLE_WARNING
int x; // предупреждение НЕ появится
return EXIT_SUCCESS;
}
Пример выравнивание (упаковка) структуры через макрос
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS, EXIT_FAILURE
// pack — это инструкция компилятору о том, как выравнивать поля структуры в памяти (pack — только для бинарных протоколов)
// pack(N) говорит компилятору: выравнивание всех полей ограничено N байтами.
// «packed struct» уплотнение - снимаем автоматическое выравнивание полей
// * Когда структура должна точно соответствовать конкретному формату данных (например, сетевой пакет)
// * Embedded / microcontrollers памяти мало → экономим байты
// * Совместимость с чужими структурами, C/C++ структуры на диске или в сети должны «идентично» лежать байт в байт
// Ограничение
// * pack(push,1) может снижать производительность на CPU, потому что выравнивание нарушено
// * Компилятор может игнорировать pack
// * На некоторых архитектурах принудительное pack может быть запрещено для корректности.
#include <stdio.h>
#define PACKED _Pragma("pack(push,1)")
#define PACKED_END _Pragma("pack(pop)")
PACKED
struct X {
char a;
int b;
} x;
PACKED_END
struct Y {
char a;
int b;
} y;
int main(void) {
DISABLE_WARNING
printf("x=%lu byte\n",sizeof x); // 5 byte
printf("y=%lu byte\n",sizeof y); // 8 byte
return EXIT_SUCCESS;
}
Пример вывести сообщение компилятору во время сборки
#ifdef DEBUG
#pragma message "DEBUG mode enabled"
#endif
//-------------------------------------------------------------------------------------
#define MSG(x) _Pragma(#x)
MSG(message "Сборка модуля X...")
MSG(message "TODO: доделать проверку ошибок")
/*
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 define.c -o my_program.out
define.c:4:16: note: ‘#pragma message: Сборка модуля X...’
4 | #define MSG(x) _Pragma(#x)
| ^~~~~~~
define.c:6:1: note: in expansion of macro ‘MSG’
6 | MSG(message "Сборка модуля X...")
| ^~~
define.c:4:16: note: ‘#pragma message: TODO: доделать проверку ошибок’
4 | #define MSG(x) _Pragma(#x)
| ^~~~~~~
define.c:7:1: note: in expansion of macro ‘MSG’
7 | MSG(message "TODO: доделать проверку ошибок")
| ^~~
*/
#pragma message "Сборка модуля X..."
#pragma message "TODO: доделать проверку ошибок"
/*
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 define.c -o my_program.out
define.c:9:9: note: ‘#pragma message: Сборка модуля X...’
9 | #pragma message "Сборка модуля X..."
| ^~~~~~~
define.c:10:9: note: ‘#pragma message: TODO: доделать проверку ошибок’
10 | #pragma message "TODO: доделать проверку ошибок"
| ^~~~~~~
*/
|
|
|
|
|
|
|
|
|
Лёгкий, часто используется в embedded.
Unity
Шпаргалка по утверждениям Unity
Скачать Unity
# 1. Clone Unity
git clone https://github.com/ThrowTheSwitch/Unity.git
# 2. Copy file unity.c and unity.h to folder tests
Пример структуры проекта:
project/
├─ src/
│ ├─ add.c
│ └─ add.h
└─ tests/
├─ test_add.c
└─ unity/
├─ unity.h
└─ unity.c
Компиляция:
gcc -std=c99 -O0 add.c tests/test_add.c tests/unity/unity.c -o test_project.out
./test_project.out
TEST_FAIL()TEST_IGNORE()
TEST_ASSERT(condition)TEST_ASSERT_TRUE(condition)TEST_ASSERT_UNLESS(condition)TEST_ASSERT_FALSE(condition)TEST_ASSERT_NULL(pointer)TEST_ASSERT_NOT_NULL(pointer)
TEST_ASSERT_EQUAL_INT(exp, act)TEST_ASSERT_EQUAL_INT8(exp, act) - проверяет равенство двух значений типа int8_tTEST_ASSERT_EQUAL_INT16(exp, act)TEST_ASSERT_EQUAL_INT32(exp, act)TEST_ASSERT_EQUAL_INT64(exp, act)TEST_ASSERT_EQUAL(exp, act)TEST_ASSERT_NOT_EQUAL(exp, act)TEST_ASSERT_EQUAL_UINT(exp, act)TEST_ASSERT_EQUAL_UINT8(exp, act)TEST_ASSERT_EQUAL_UINT16(exp, act)TEST_ASSERT_EQUAL_UINT32(exp, act)TEST_ASSERT_EQUAL_UINT64(exp, act)
TEST_ASSERT_EQUAL_HEX(exp, act) - удобнее при работе с регистрамиTEST_ASSERT_EQUAL_HEX8(exp, act)TEST_ASSERT_EQUAL_HEX16(exp, act)TEST_ASSERT_EQUAL_HEX32(exp, act)TEST_ASSERT_EQUAL_HEX64(exp, act)
TEST_ASSERT_BITS(mask, exp, act) - проверяет, что актуальное значение содержит тот же набор битов под маской, что и expTEST_ASSERT_BITS_HIGH(mask, act) - проверяет, что все биты, указанные в маске как 1, в ac должны быть - HIGHTEST_ASSERT_BITS_LOW(mask, act) - проверяет, что все биты, указанные в маске как 1, в ac должны быть - LOWTEST_ASSERT_BIT_HIGH(bit, act) - проверяет, что конкретный бит в числе = HIGHTEST_ASSERT_BIT_LOW(bit, act) - проверяет, что конкретный бит в числе = LOW
TEST_ASSERT_INT_WITHIN(delta, exp, act) - проверяют попадание значения в диапазонTEST_ASSERT_INT8_WITHIN(delta, exp, act)TEST_ASSERT_INT16_WITHIN(delta, exp, act)TEST_ASSERT_INT32_WITHIN(delta, exp, act)TEST_ASSERT_INT64_WITHIN(delta, exp, act)TEST_ASSERT_UINT_WITHIN(delta, exp, act)TEST_ASSERT_UINT8_WITHIN(delta, exp, act)TEST_ASSERT_UINT16_WITHIN(delta, exp, act)TEST_ASSERT_UINT32_WITHIN(delta, exp, act)TEST_ASSERT_UINT64_WITHIN(delta, exp, act)TEST_ASSERT_HEX_WITHIN(delta, exp, act)TEST_ASSERT_HEX8_WITHIN(delta, exp, act)TEST_ASSERT_HEX16_WITHIN(delta, exp, act)TEST_ASSERT_HEX32_WITHIN(delta, exp, act)TEST_ASSERT_HEX64_WITHIN(delta, exp, act)
TEST_ASSERT_EQUAL_PTR(exp, act) - проверяет что два указателя равны, т.е. указывают на один и тот же адресTEST_ASSERT_EQUAL_STRING(exp, act) - сравнивает строки по содержимомуTEST_ASSERT_EQUAL_MEMORY(exp, act, len) - побайтово сравнивает память (memcmp). Если в структуре есть padding — сравнение может упасть
TEST_ASSERT_EQUAL_INT_ARRAY(exp, act, elem) - сравнивает elem первых элементов двух массивов intTEST_ASSERT_EQUAL_INT8_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_INT16_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_INT32_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_INT64_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_UINT_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_UINT8_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_UINT16_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_UINT32_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_UINT64_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_HEX_ARRAY(exp, act, elem) - сравнивает elem первых элементов двух массивов HEXTEST_ASSERT_EQUAL_HEX8_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_HEX16_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_HEX32_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_HEX64_ARRAY(exp, act, elem)TEST_ASSERT_EQUAL_PTR_ARRAY(exp, act, elem) - сравнивает массивы указателей. Сравнивает сами адреса, а не содержимое по нимTEST_ASSERT_EQUAL_STRING_ARRAY(exp, act, elem) - сравнивает массив строк (char* или char[…][…]). strcmp для каждого элементаTEST_ASSERT_EQUAL_MEMORY_ARRAY(exp, act, len, elem) - сравнивает массив произвольных блоков данных. Сравнивает каждый элемент как сырые байты. Если в структуре есть padding — сравнение может упасть
TEST_ASSERT_EACH_EQUAL_INT8(exp, act, elem) - массовая проверка, которая проверяет, что каждый элемент массива равен одному и тому же значению exp
TEST_ASSERT_FLOAT_WITHIN(delta, exp, act) - проверяет, что act находится в диапазоне exp ± deltaTEST_ASSERT_EQUAL_FLOAT(exp, act) - проверяет точное равенство floatTEST_ASSERT_EQUAL_FLOAT_ARRAY(exp, act, elem)TEST_ASSERT_FLOAT_IS_INF(act)TEST_ASSERT_FLOAT_IS_NEG_INF(act)TEST_ASSERT_FLOAT_IS_NAN(act) - проверяет, что float = NaN (Not a Number)TEST_ASSERT_FLOAT_IS_DETERMINATE(act) - проверяет, что float не NaN и не InfTEST_ASSERT_FLOAT_IS_NOT_INF(act) - проверяет, что значение не равно +∞ (положительная бесконечность)TEST_ASSERT_FLOAT_IS_NOT_NEG_INF(act) - проверяет, что значение не равно -∞ (отрицательная бесконечность)TEST_ASSERT_FLOAT_IS_NOT_NAN(act)TEST_ASSERT_FLOAT_IS_NOT_DETERMINATE(act)
TEST_ASSERT_DOUBLE_WITHIN(delta, exp, act)TEST_ASSERT_EQUAL_DOUBLE(exp, act)TEST_ASSERT_EQUAL_DOUBLE_ARRAY(exp, act, elem)TEST_ASSERT_DOUBLE_IS_INF(act)TEST_ASSERT_DOUBLE_IS_NEG_INF(act)TEST_ASSERT_DOUBLE_IS_NAN(act)TEST_ASSERT_DOUBLE_IS_DETERMINATE(act)TEST_ASSERT_DOUBLE_IS_NOT_INF(act)TEST_ASSERT_DOUBLE_IS_NOT_NEG_INF(act)TEST_ASSERT_DOUBLE_IS_NOT_NAN(act)TEST_ASSERT_DOUBLE_IS_NOT_DETERMINATE(act)
Проект Unity — ThrowTheSwitch.org
Авторы: Mike Karlesky, Mark VanderVoord
|
|
|
// test_utils.c
#include "unity/unity.h"
#include "../utils.h"
#include <stdint.h>
#include <string.h>
#include <math.h>
void setUp(void) {
// Вызывается перед каждым тестом
}
void tearDown(void) {
// Вызывается после каждого теста
}
void test_add_positive(void) {
TEST_ASSERT_EQUAL(8, add(5, 3));
}
void test_add_failed(void) {
TEST_ASSERT_NOT_EQUAL(9, add(5, 3));
}
void test_multiply_positive(void) {
TEST_ASSERT_EQUAL(4, multiply(2,2));
}
void test_multiply_failed(void) {
TEST_ASSERT_NOT_EQUAL(5, multiply(2,2));
}
// -----------------------------------------------
/*
**Boolean**
- `TEST_ASSERT(condition)`
- `TEST_ASSERT_TRUE(condition)`
- `TEST_ASSERT_UNLESS(condition)`
- `TEST_ASSERT_FALSE(condition)`
- `TEST_ASSERT_NULL(pointer)`
- `TEST_ASSERT_NOT_NULL(pointer)`
*/
void test_unity_boolean(void) {
TEST_ASSERT(1 == 1);
TEST_ASSERT_TRUE(1 > 0);
TEST_ASSERT_UNLESS(1 == 0);
TEST_ASSERT_FALSE(0);
int *ptr = NULL;
TEST_ASSERT_NULL(ptr);
int x = 1;
ptr = &x;
TEST_ASSERT_NOT_NULL(ptr);
}
/*
**Signed and Unsigned Integers (of all sizes)**
- `TEST_ASSERT_EQUAL_INT(exp, act)`
- `TEST_ASSERT_EQUAL_INT8(exp, act)`
- `TEST_ASSERT_EQUAL_INT16(exp, act)`
- `TEST_ASSERT_EQUAL_INT32(exp, act)`
- `TEST_ASSERT_EQUAL_INT64(exp, act)`
- `TEST_ASSERT_EQUAL(exp, act)`
- `TEST_ASSERT_NOT_EQUAL(exp, act)`
- `TEST_ASSERT_EQUAL_UINT(exp, act)`
- `TEST_ASSERT_EQUAL_UINT8(exp, act)`
- `TEST_ASSERT_EQUAL_UINT16(exp, act)`
- `TEST_ASSERT_EQUAL_UINT32(exp, act)`
- `TEST_ASSERT_EQUAL_UINT64(exp, act)`
*/
void test_unity_signed_unsigned_integers_sizes(void) {
{
int x = 1;
int y = 1;
TEST_ASSERT_EQUAL_INT(x, y);
TEST_ASSERT_EQUAL(x, y);
TEST_ASSERT_NOT_EQUAL(x, 0);
}
{
int8_t x = 0;
int8_t y = 0;
TEST_ASSERT_EQUAL_INT(x, y);
}
{
int16_t x = 0;
int16_t y = 0;
TEST_ASSERT_EQUAL_INT16(x, y);
}
{
uint8_t x = 1;
uint8_t y = 1;
TEST_ASSERT_EQUAL_UINT(x, y);
}
}
/*
**Unsigned Integers (of all sizes) in Hexadecimal**
- `TEST_ASSERT_EQUAL_HEX(exp, act)`
- `TEST_ASSERT_EQUAL_HEX8(exp, act)`
- `TEST_ASSERT_EQUAL_HEX16(exp, act)`
- `TEST_ASSERT_EQUAL_HEX32(exp, act)`
- `TEST_ASSERT_EQUAL_HEX64(exp, act)`
*/
void test_unity_hexadecimal(void) {
uint16_t reg = 0xA55A;
TEST_ASSERT_EQUAL_HEX16(0xA55A, reg);
}
/*
**Masked and Bit-level Comparisons**
- `TEST_ASSERT_BITS(mask, exp, act)`
- `TEST_ASSERT_BITS_HIGH(mask, act)`
- `TEST_ASSERT_BITS_LOW(mask, act)`
- `TEST_ASSERT_BIT_HIGH(bit, act)`
- `TEST_ASSERT_BIT_LOW(bit, act)`
*/
void test_unity_bit_level(void) {
/*{
// Проверяет, что актуальное значение содержит тот же набор битов под маской, что и exp
// (exp & mask) == (act & mask)
#define ENABLE 0x01
#define ERROR 0x04
uint8_t mask = ENABLE | ERROR;
uint8_t exp = ENABLE; // ENABLE=1, ERROR=0
uint8_t act = 0b00000101; // ENABLE=1, ERROR=1 (!) error bit mismatch
TEST_ASSERT_BITS(mask, exp, act);// FAIL: Expected XXXXXXXXXXXXXXXXXXXXXXXXXXXXX0X1 Was XXXXXXXXXXXXXXXXXXXXXXXXXXXXX1X1
}*/
//---------------------------------------------------------
// проверяет, что все биты, указанные в маске как 1, в ac должны быть - HIGH
// Биты 2 и 3 — должны быть HIGH → тест пройдет
TEST_ASSERT_BITS_HIGH(0b00001100, 0b11111100);
//---------------------------------------------------------
// проверяет, что все биты, указанные в маске как 1, в ac должны быть - LOW
// Биты 2 и 3 — оба LOW → тест пройдет
TEST_ASSERT_BITS_LOW(0b00001100, 0b10110011);
//---------------------------------------------------------
// проверяет, что конкретный бит в числе = HIGH
// bit — это номер бита, а не маска.
int act = 0b00000100;
// Бит №2 → 1 → тест проходит.
TEST_ASSERT_BIT_HIGH(2, act);
//---------------------------------------------------------
// проверяет, что конкретный бит в числе = LOW
// Бит №5 → 0 → тест проходит.
TEST_ASSERT_BIT_LOW(5, 0b00000000);
}
/*
**Integer Ranges (of all sizes)**
- `TEST_ASSERT_INT_WITHIN(delta, exp, act)`
- `TEST_ASSERT_INT8_WITHIN(delta, exp, act)`
- `TEST_ASSERT_INT16_WITHIN(delta, exp, act)`
- `TEST_ASSERT_INT32_WITHIN(delta, exp, act)`
- `TEST_ASSERT_INT64_WITHIN(delta, exp, act)`
- `TEST_ASSERT_UINT_WITHIN(delta, exp, act)`
- `TEST_ASSERT_UINT8_WITHIN(delta, exp, act)`
- `TEST_ASSERT_UINT16_WITHIN(delta, exp, act)`
- `TEST_ASSERT_UINT32_WITHIN(delta, exp, act)`
- `TEST_ASSERT_UINT64_WITHIN(delta, exp, act)`
- `TEST_ASSERT_HEX_WITHIN(delta, exp, act)`
- `TEST_ASSERT_HEX8_WITHIN(delta, exp, act)`
- `TEST_ASSERT_HEX16_WITHIN(delta, exp, act)`
- `TEST_ASSERT_HEX32_WITHIN(delta, exp, act)`
- `TEST_ASSERT_HEX64_WITHIN(delta, exp, act)`
*/
void test_unity_ranges(void) {
// проверяют попадание значения в диапазон
// (exp - delta) <= act <= (exp + delta)
// То есть actual должен быть в пределах exp ± delta
int expected = 100;
int actual = 103;
TEST_ASSERT_INT_WITHIN(5, expected, actual);
TEST_ASSERT_HEX_WITHIN(0x10, 0x100, 0x0F5);
// Тест пройдёт, потому что:
// 100 - 5 = 95
// 100 + 5 = 105
// 103 — внутри диапазона
}
/*
**Structs and Strings**
- `TEST_ASSERT_EQUAL_PTR(exp, act)`
- `TEST_ASSERT_EQUAL_STRING(exp, act)`
- `TEST_ASSERT_EQUAL_MEMORY(exp, act, len)`
*/
void test_unity_structs_and_strings(void) {
{
// проверяет что два указателя равны, т.е. указывают на один и тот же адрес
int a = 5;
int *p1 = &a;
int *p2 = &a;
TEST_ASSERT_EQUAL_PTR(p1, p2); // OK — указывают на один адре
}
{
// Сравнивает строки по содержимому, а не по адресам
// Останавливается на первом '\0' (как strcmp(exp, act) == 0)
const char *s = "Hello";
TEST_ASSERT_EQUAL_STRING("Hello", s);
}
{
// Побайтово сравнивает память (memcmp)
// В отличие от TEST_ASSERT_EQUAL_STRING, этот макрос не смотрит на '\0', а сравнивает ровно len байт
typedef struct {
uint8_t a;
uint16_t b;
char name[4];
} Data;
Data exp = {0};
exp.a = 1;
exp.b = 200;
memcpy(exp.name, "Bob", 4);
Data act = {0};
act.a = 1;
act.b = 200;
memcpy(act.name, "Bob", 4);
TEST_ASSERT_EQUAL_MEMORY(&exp, &act, sizeof(Data));
}
{
typedef struct {
uint8_t a;
uint16_t b;
char name[4];
} Data;
Data exp = {1, 200, "Bob"};
Data act = {1, 200, "Bob"};
// Так не проходит тест из-за мусорного padding, который остаётся неинициализированным
// TEST_ASSERT_EQUAL_MEMORY(&exp, &act, sizeof(Data));// FAIL: Memory Mismatch. Byte 1 Expected Was
// можно сранить по полям
TEST_ASSERT_EQUAL_UINT8(exp.a, act.a);
TEST_ASSERT_EQUAL_UINT16(exp.b, act.b);
TEST_ASSERT_EQUAL_STRING(exp.name, act.name);
// или учесть только реальные поля
TEST_ASSERT_EQUAL_MEMORY(&exp, &act, sizeof(uint8_t) + sizeof(uint16_t) + (sizeof(char) * 4));
//---------------------------------------------------------
// Можно убрать padding и сранить
#define PACKED _Pragma("pack(push,1)")
#define PACKED_END _Pragma("pack(pop)")
PACKED
typedef struct {
uint8_t a;
uint16_t b;
char name[4];
} Data_NoPadding;
PACKED_END
TEST_ASSERT_EQUAL(8, sizeof(Data));
TEST_ASSERT_EQUAL(7, sizeof(Data_NoPadding));
Data_NoPadding exp_np = {1, 200, "Bob"};
Data_NoPadding act_np = {1, 200, "Bob"};
TEST_ASSERT_EQUAL_MEMORY(&exp_np, &act_np, sizeof(Data));
}
{
uint8_t exp[3] = {1, 2, 3};
uint8_t act[3] = {1, 2, 3};
TEST_ASSERT_EQUAL_MEMORY(exp, act, 3);
}
}
/*
**Arrays**
- `TEST_ASSERT_EQUAL_INT_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_INT8_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_INT16_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_INT32_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_INT64_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_UINT_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_UINT8_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_UINT16_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_UINT32_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_UINT64_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_HEX_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_HEX8_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_HEX16_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_HEX32_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_HEX64_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_PTR_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_STRING_ARRAY(exp, act, elem)`
- `TEST_ASSERT_EQUAL_MEMORY_ARRAY(exp, act, len, elem)`
*/
void test_unity_arrays(void) {
{
// Сравнивает elem первых элементов двух массивов int
int exp[] = {1, 2, 3};
int act[] = {1, 2, 3};
TEST_ASSERT_EQUAL_INT_ARRAY(exp, act, 3);
}
{
// Сравнивает elem первых элементов двух массивов HEX
uint16_t exp[] = {0x10, 0x20};
uint16_t act[] = {0x10, 0x20};
TEST_ASSERT_EQUAL_HEX_ARRAY(exp, act, 2);
}
{
// Сравнивает массивы указателей. Сравнивает сами адреса, не содержимое по ним.
int a = 5, b = 7;
int *exp[] = { &a, &b };
int *act[] = { &a, &b };
TEST_ASSERT_EQUAL_PTR_ARRAY(exp, act, 2);
}
{
// Сравнивает массив строк (char* или char[…][…]). strcmp для каждого элемента
const char *exp[] = {"Bob", "Alice"};
const char *act[] = {"Bob", "Alice"};
TEST_ASSERT_EQUAL_STRING_ARRAY(exp, act, 2);
}
{
// сравнивает массив произвольных блоков данных
// Сравнивает каждый элемент как сырые байты
// Если в структуре есть padding — сравнение может упасть
typedef struct {
uint8_t a;
uint8_t b;
} Item;
Item exp[] = {{1,2}, {3,4}};
Item act[] = {{1,2}, {3,4}};
TEST_ASSERT_EQUAL_MEMORY_ARRAY(exp, act, sizeof(Item), 2);
}
{
// массовая проверка, которая проверяет, что каждый элемент массива равен одному и тому же значению exp
uint8_t act[] = {5, 5, 5, 5};
TEST_ASSERT_EACH_EQUAL_INT8(5, act, sizeof(act));// весь массив заполнен значением 5
}
}
/*
**Floating Point (If Enabled)**
- `TEST_ASSERT_FLOAT_WITHIN(delta, exp, act)`
- `TEST_ASSERT_EQUAL_FLOAT(exp, act)`
- `TEST_ASSERT_EQUAL_FLOAT_ARRAY(exp, act, elem)`
- `TEST_ASSERT_FLOAT_IS_INF(act)`
- `TEST_ASSERT_FLOAT_IS_NEG_INF(act)`
- `TEST_ASSERT_FLOAT_IS_NAN(act)`
- `TEST_ASSERT_FLOAT_IS_DETERMINATE(act)`
- `TEST_ASSERT_FLOAT_IS_NOT_INF(act)`
- `TEST_ASSERT_FLOAT_IS_NOT_NEG_INF(act)`
- `TEST_ASSERT_FLOAT_IS_NOT_NAN(act)`
- `TEST_ASSERT_FLOAT_IS_NOT_DETERMINATE(act)`
*/
void test_unity_floating_point(void) {
{
// Проверяет, что act находится в диапазоне exp ± delta
// В float почти никогда не стоит проверять точное равенство, поэтому это самый важный макрос.
float result = 3.1415f;
TEST_ASSERT_FLOAT_WITHIN(0.01f, 3.14f, result);
// Проверяет точное равенство float
// Используется редко, только если значения точно совпадают (например, константы)
TEST_ASSERT_EQUAL_FLOAT(3.1415f, result);
}
{
// Проверяет, что float = NaN (Not a Number)
float z = 0.0f / 0.0f; // NaN
TEST_ASSERT_FLOAT_IS_NAN(z); // OK
float w = 0.0f / 0.0f; // NaN
TEST_ASSERT_FLOAT_IS_NAN(w); // OK
}
{
// Проверяет, что float не NaN и не Inf
float a = 3.14f;
TEST_ASSERT_FLOAT_IS_DETERMINATE(a); // OK
//float b = 1.0f / 0.0f;
// TEST_ASSERT_FLOAT_IS_DETERMINATE(b); // FAIL, т.к. +Inf
}
{
// Проверяет, что значение не равно +∞ (положительная бесконечность)
float x = 123.4f;
TEST_ASSERT_FLOAT_IS_NOT_INF(x); // OK
//float y = 1.0f / 0.0f; // +Inf
// TEST_ASSERT_FLOAT_IS_NOT_INF(y); // FAIL
}
{
// Проверяет, что значение не равно -∞ (отрицательная бесконечность)
float x = -50.0f;
TEST_ASSERT_FLOAT_IS_NOT_NEG_INF(x); // OK
//float y = -1.0f / 0.0f; // -Inf
// TEST_ASSERT_FLOAT_IS_NOT_NEG_INF(y); // FAIL
}
{
// Проверяет, что значение не является NaN
float a = 3.14f;
TEST_ASSERT_FLOAT_IS_NOT_NAN(a); // OK
//float b = 0.0f / 0.0f; // NaN
// TEST_ASSERT_FLOAT_IS_NOT_NAN(b); // FAIL
}
}
//------------------------------------------------
/*
make test
gcc -std=c99 -Wall -Wextra -Wformat -Werror -Wconversion -Wformat=2 -Wformat-security -fdiagnostics-color=always -fmessage-length=0 -Wformat-diag -O0 utils.c tests/test_utils.c tests/unity/unity.c -o test_my_program.out
./test_my_program.out
tests/test_utils.c:430:test_add_positive:PASS
tests/test_utils.c:431:test_add_failed:PASS
tests/test_utils.c:432:test_multiply_positive:PASS
tests/test_utils.c:433:test_multiply_failed:PASS
tests/test_utils.c:435:test_unity_boolean:PASS
tests/test_utils.c:436:test_unity_signed_unsigned_integers_sizes:PASS
tests/test_utils.c:437:test_unity_hexadecimal:PASS
tests/test_utils.c:438:test_unity_bit_level:PASS
tests/test_utils.c:439:test_unity_ranges:PASS
tests/test_utils.c:440:test_unity_structs_and_strings:PASS
tests/test_utils.c:441:test_unity_arrays:PASS
tests/test_utils.c:442:test_unity_floating_point:PASS
-----------------------
12 Tests 0 Failures 0 Ignored
OK
*/
int main(void) {
UNITY_BEGIN();
RUN_TEST(test_add_positive);
RUN_TEST(test_add_failed);
RUN_TEST(test_multiply_positive);
RUN_TEST(test_multiply_failed);
RUN_TEST(test_unity_boolean);
RUN_TEST(test_unity_signed_unsigned_integers_sizes);
RUN_TEST(test_unity_hexadecimal);
RUN_TEST(test_unity_bit_level);
RUN_TEST(test_unity_ranges);
RUN_TEST(test_unity_structs_and_strings);
RUN_TEST(test_unity_arrays);
RUN_TEST(test_unity_floating_point);
return UNITY_END();
}
|
|
|
|
|
В системах Unix имеется программа-профилировщик GPROF
|
Она генерирует два вида информации.
- Во-первых, определяет количество процессорного времени, потраченного на выполнение каждой функции.
- Во-вторых, вычисляет количество вызовов каждой функции, группируя их по точкам, откуда были сделаны вызовы.
И те, и другие сведения могут быть весьма полезными. Замеры времени помогают определить относительный вклад различных функций в общее время выполнения. Информация о количестве вызовов позволяет понять динамику поведения программы.
Вызовы библиотечных функций обычно не отображаются в отчетах GPROF. Их время чаще включается во время вызывающих их функций.
|
|
|
Замеры времени не отличаются высокой точностью. Конечно, может случиться так, что функция только начала выполняться и очень скоро будет завершена, однако на ее счет будет записано время, прошедшее с момента последнего прерывания. Какая-то другая функция может успеть выполниться между двумя прерываниями, но профилировщик не заметит этого.
Для программ, выполняющихся меньше одной секунды, эти оценки следует рассматривать как весьма приблизительные
|
|
|
File testprof.c:
// testprof.c
#include <stdio.h>
#include <stdlib.h> // EXIT_SUCCESS
#include <stdint.h> // int8_t, int32_t ...
size_t length(uint8_t *arr){
return 10;
}
int main() {
uint8_t arr[10] = { [0 ... 9] = 1 };
for (int i = 0; i < length(arr); i++) {
printf("%d ", arr[i]);
}
return EXIT_SUCCESS;
}
// Просто компиляция:
// gcc testprof.c -o testprof
// ./testprof
// Компиляция для профилирования:
// gcc -Og -pg testprof.c -o testprof
// ./testprof file.txt # создаст бинарный файл gmon.out
// gprof testprof # анализ файла gmon.out
Результат: функция length вызывалась 11 раз, время выполнения 0:
- В первом столбце дается доля всего времени в процентах, затраченного на выполнение
функции.
- Во втором – накопленное время, затраченное всеми функциями, до включе-
ния этой функции в отчет в эту строку.
- В третьем столбце – общее время выполнения
этой функции
- В четвертом – количество вызовов функции (не считая рекурсивных
вызовов).
Flat profile:
Each sample counts as 0.01 seconds.
no time accumulated
% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
0.00 0.00 0.00 11 0.00 0.00 length
Во второй части отчета профилировщика показана история вызовов функций:
index % time self children called name
0.00 0.00 11/11 main [7]
[1] 0.0 0.00 0.00 11 length [1]
Полный вывод:
Flat profile:
Each sample counts as 0.01 seconds.
no time accumulated
% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
0.00 0.00 0.00 11 0.00 0.00 length
% the percentage of the total running time of the
time program used by this function.
cumulative a running sum of the number of seconds accounted
seconds for by this function and those listed above it.
self the number of seconds accounted for by this
seconds function alone. This is the major sort for this
listing.
calls the number of times this function was invoked, if
this function is profiled, else blank.
self the average number of milliseconds spent in this
ms/call function per call, if this function is profiled,
else blank.
total the average number of milliseconds spent in this
ms/call function and its descendents per call, if this
function is profiled, else blank.
name the name of the function. This is the minor sort
for this listing. The index shows the location of
the function in the gprof listing. If the index is
in parenthesis it shows where it would appear in
the gprof listing if it were to be printed.
Copyright (C) 2012-2024 Free Software Foundation, Inc.
Copying and distribution of this file, with or without modification,
are permitted in any medium without royalty provided the copyright
notice and this notice are preserved.
Call graph (explanation follows)
granularity: each sample hit covers 4 byte(s) no time propagated
index % time self children called name
0.00 0.00 11/11 main [7]
[1] 0.0 0.00 0.00 11 length [1]
-----------------------------------------------
This table describes the call tree of the program, and was sorted by
the total amount of time spent in each function and its children.
Each entry in this table consists of several lines. The line with the
index number at the left hand margin lists the current function.
The lines above it list the functions that called this function,
and the lines below it list the functions this one called.
This line lists:
index A unique number given to each element of the table.
Index numbers are sorted numerically.
The index number is printed next to every function name so
it is easier to look up where the function is in the table.
% time This is the percentage of the `total' time that was spent
in this function and its children. Note that due to
different viewpoints, functions excluded by options, etc,
these numbers will NOT add up to 100%.
self This is the total amount of time spent in this function.
children This is the total amount of time propagated into this
function by its children.
called This is the number of times the function was called.
If the function called itself recursively, the number
only includes non-recursive calls, and is followed by
a `+' and the number of recursive calls.
name The name of the current function. The index number is
printed after it. If the function is a member of a
cycle, the cycle number is printed between the
function's name and the index number.
For the function's parents, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the function into this parent.
children This is the amount of time that was propagated from
the function's children into this parent.
called This is the number of times this parent called the
function `/' the total number of times the function
was called. Recursive calls to the function are not
included in the number after the `/'.
name This is the name of the parent. The parent's index
number is printed after it. If the parent is a
member of a cycle, the cycle number is printed between
the name and the index number.
If the parents of the function cannot be determined, the word
`<spontaneous>' is printed in the `name' field, and all the other
fields are blank.
For the function's children, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the child into the function.
children This is the amount of time that was propagated from the
child's children to the function.
called This is the number of times the function called
this child `/' the total number of times the child
was called. Recursive calls by the child are not
listed in the number after the `/'.
name This is the name of the child. The child's index
number is printed after it. If the child is a
member of a cycle, the cycle number is printed
between the name and the index number.
If there are any cycles (circles) in the call graph, there is an
entry for the cycle-as-a-whole. This entry shows who called the
cycle (as parents) and the members of the cycle (as children.)
The `+' recursive calls entry shows the number of function calls that
were internal to the cycle, and the calls entry for each member shows,
for that member, how many times it was called from other members of
the cycle.
Copyright (C) 2012-2024 Free Software Foundation, Inc.
Copying and distribution of this file, with or without modification,
are permitted in any medium without royalty provided the copyright
notice and this notice are preserved.
Index by function name
[1] length
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|