|
|
|
В Rust работа с байтами — довольно частая задача, особенно в системном программировании, сетевых протоколах и обработке бинарных данных.
|
|
|
Шестнадцатеричная система счисления (компактна)
|
Один байт состоит из восьми бит. В двоичной системе интервал его значений от
00000000 до 11111111.
В десятичном целочисленном представлении байт охватывает диапазон от 0 до 255.
Двоичное представление слишком громоздкое, а для десятичного очень утомительно выполнять преобразования в битовые комбинации и обратно.
Вместо всего этого битовые комбинации записываются в шестнадцатеричной нотации. В шестнадцатеричной системе счисления используются цифры от 0 до 9 и буквы от А до F.
При записи в шестнадцатеричной форме байт охватывает диапазон от 00 до FF
fn main() {
println!("{:<7} | {:<6} | {}", "Decimal", "Hex", "Binary");
for i in 0..=256 {
println!("{:<7} | {:<6X} | {:08b}", i, i, i);
}
}
|
|
Работа с бинарными протоколами
byteorder — удобное чтение/запись чисел из потоков в big/little endian.bytes — эффективный буфер для сетевого кода.- crate serde + crate bincode — сериализация структур в бинарный формат.
|
|
|
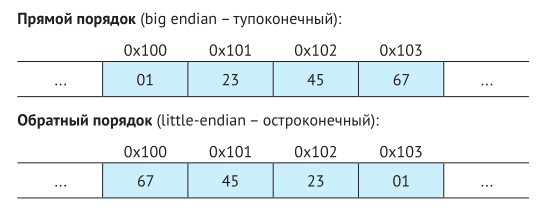
Что такое порядок байт (byte order, endianness)
|
Для программных объектов, занимающих несколько байтов, необходимо установить два правила: каков будет адрес объекта и как должны располагаться байты в памяти.
Практически во всех машинах такие объекты хранятся в виде непрерывных последовательностей байтов, а адресом многобайтного объекта служит наименьший адрес ячейки памяти. Например, предположим, что переменная x типа int имеет адрес 0x100, т.е. выражение взятия адреса &x вернет 0x100. Тогда четыре байта, составляющих значение переменной x, будут храниться в ячейках памяти 0x100, 0x101, 0x102 и 0x103.
Как должны располагаться байты в памяти.
- Первое правило: порядок, когда первым следует наименьший значащий байт, называется обратным, или остроконечным (little endian).
- Второе правило: порядок, когда первым следует наибольший значащий байт, называется прямым, или тупоконечным (big endian).
Порядок байтов фиксируется с выбором конкретной операционной системы.
Переменная x типа int с адресом 0x100, хранящей шестнадцатеричное значение 0x01234567. Порядок расположения байтов в ячейках с адресами от 0x100 до 0x103 зависит от типа машины:
Компьютер хранит числа в памяти в виде байтов. Если число больше одного байта (например, u32 = 4 байта), возникает вопрос: в каком порядке эти байты кладутся в память?
Есть два основных варианта:
-
Little-endian (LE)
- Наименее значимый байт идёт первым (по меньшему адресу).
- Пример:
0x12345678 хранится как 78 56 34 12.
- Доминирование архитектуры x86 — Intel выбрала LE, и теперь это стандарт де-факто для десктопа.
- Так делают почти все современные процессоры (Intel x86, AMD64, ARM в режиме по умолчанию). Это логично для схем и кода, удобнее считать и обрабатывать данные.
- Простота приведения типов —
int16_t x = 0x1234; → int8_t y = (int8_t)x; даст 0x34 без сдвига адреса.
- Эффективность арифметики — сложение/вычитание начинается с младших байтов, можно не знать длину числа.
-
Big-endian (BE)
- Наиболее значимый байт идёт первым (по меньшему адресу).
- Пример:
0x12345678 хранится как 12 34 56 78.
- Человеку этот способ привычнее, потому что мы пишем числа "от старшего к младшему".
- Простота отладки — дамп памяти читается как шестнадцатеричное число.
- В сетевых протоколах (TCP/IP) стандарт принят именно BE (его ещё называют network byte order).
Почему это важно
-
Если два компьютера обмениваются числами напрямую в байтах, они должны договориться о порядке байт.
-
Если вы записываете числа в бинарный файл, порядок байт должен быть фиксирован и понятен для всех, кто будет его читать.
-
Ошибка с порядком байт может "перевернуть" значения:
0x12345678 (305419896) на LE выглядит как 78 56 34 12 (2018915346 на BE, если интерпретировать не тем способом).
Rust и порядок байт
В Rust у числовых типов есть методы для работы с порядком байт:
fn main(){
let x: u32 = 0x12345678;
assert_eq!(x.to_le_bytes(), [0x78, 0x56, 0x34, 0x12]); // little-endian
assert_eq!(x.to_be_bytes(), [0x12, 0x34, 0x56, 0x78]); // big-endian
assert_eq!(x.to_ne_bytes(), [0x78, 0x56, 0x34, 0x12]); // native (на вашей машине)
}
fn main(){
let bytes = [0x78, 0x56, 0x34, 0x12];
let n_le = u32::from_le_bytes(bytes); // 0x12345678
let n_be = u32::from_be_bytes(bytes); // 0x78563412
let n_ne = u32::from_ne_bytes(bytes); // зависит от архитектуры
}
Где встречается
- Сетевое программирование: всегда используем
to_be_bytes() / from_be_bytes().
- Файловые форматы (например, BMP little-endian, PNG big-endian).
- Системное программирование: при взаимодействии с памятью, регистрами, драйверами.
- Отладка — дамп памяти читается "задом наперёд" в LE.
- Битовые поля в структурах — порядок бит тоже зависит от endianness.
Как Rust помогает избежать ошибок
- В отличие от C, где можно «случайно» трактовать память не в том порядке, в Rust преобразования явные:
ты сам вызываешь
.to_le_bytes() или .from_be_bytes().
- Есть трейт
byteorder (из экосистемы), который делает удобное чтение/запись чисел из потоков в любом порядке.
То есть:
- Порядок байт — это вопрос представления чисел в памяти.
- Rust решает его через явные методы на типах, чтобы не было «магии» и неявных ошибок.
Текстовые данные менее зависимы от платформы, нежели двоичные.
Текстовые данные (например, JSON, XML, CSV, plain text):
- Платформенно-независимы — используют только ASCII/Unicode символы
- Портативны — одинаково читаются на x86, ARM, big-endian, little-endian
- Отлаживаемы — можно открыть в любом текстовом редакторе
Двоичные данные (бинарные файлы):
Зависят от:
- Endianness (порядок байтов)
- Размер типов (
int = 4 или 8 байт?)
- Выравнивание структур (padding)
- Представление чисел с плавающей точкой
|
|
Моделируем «общение» двух компьютеров
с учетом порядка байт
|
- Для бинарных протоколов всегда используем
to_be_bytes() / from_be_bytes().
- Для файловых форматов используем тот порядок, который указан в спецификации (например, BMP → LE).
- Rust заставляет это делать явно, чтобы не было скрытых ошибок.
Моделируем «общение» двух компьютеров:
- Один — little-endian (например, PC с x86).
- Другой — big-endian (например, сетевой протокол или гипотетическая архитектура).
- Передавать будем 32-битное число
0x12345678.
❌ Неправильный способ (ошибка)
Если просто отправлять байты «как есть» (to_ne_bytes()), получим несовместимость:
fn main() {
let x: u32 = 0x12345678;
// little-endian машина
let le_bytes = x.to_ne_bytes(); // на x86: [78, 56, 34, 12]
println!("LE отправил: {:x?}", le_bytes);
// big-endian машина читает "как есть"
let y = u32::from_ne_bytes(le_bytes); // интерпретация по BE
println!("BE прочитал: 0x{:08x}", y);
}
Вывод на little-endian CPU будет примерно такой:
LE отправил: [78, 56, 34, 12]
BE прочитал: 0x78563412
❌ Видно, что число искажено.
✅ Правильный способ (через network byte order = big-endian)
Чтобы оба компьютера понимали данные одинаково, обычно договариваются о сетевом порядке (big-endian):
fn main() {
let x: u32 = 0x12345678;
// little-endian машина сериализует в big-endian (сетевой порядок)
let packet = x.to_be_bytes(); // [12, 34, 56, 78]
println!("Отправлено по сети: {:x?}", packet);
// big-endian машина получает и интерпретирует
let y = u32::from_be_bytes(packet);
println!("BE прочитал: 0x{:08x}", y);
// даже на little-endian CPU Rust правильно соберёт
let z = u32::from_be_bytes(packet);
println!("LE прочитал: 0x{:08x}", z);
}
Вывод:
Отправлено по сети: [12, 34, 56, 78]
BE прочитал: 0x12345678
LE прочитал: 0x12345678
✅ Теперь оба компьютера видят одинаковое значение.
|
|
Читаем и пишем числа в поток, используя явное указание порядка байтов. Для удобства возьмём Cursor<Vec<u8>> вместо реального TcpStream — это удобно для демонстрации, а синтаксис идентичен.
|
use byteorder::{BigEndian, LittleEndian, ReadBytesExt, WriteBytesExt};
use std::io::Cursor;
fn main() -> std::io::Result<()> {
// 1. Создаём поток-буфер
let mut buffer = Cursor::new(Vec::new());
// 2. Записываем числа с разной эндийностью
let num1: u32 = 0x12345678;
let num2: u16 = 0xABCD;
// Записываем num1 в big-endian (сетевой порядок)
buffer.write_u32::(num1)?;
// Записываем num2 в little-endian
buffer.write_u16::(num2)?;
println!("Буфер после записи: {:x?}", buffer.get_ref());
// 3. Перематываем курсор для чтения
buffer.set_position(0);
// 4. Читаем числа обратно, явно указывая эндийность
let read_num1 = buffer.read_u32::()?;
let read_num2 = buffer.read_u16::()?;
println!("Прочитано num1: 0x{:08X}", read_num1);
println!("Прочитано num2: 0x{:04X}", read_num2);
Ok(())
}
Объяснение
Cursor<Vec<u8>> — имитация потока данных в памяти.- WriteBytesExt — позволяет писать числа в поток в нужной эндийности:
<BigEndian> или <LittleEndian>.
- ReadBytesExt — позволяет читать числа из потока с явной эндийностью.
- Важно: эндийность должна совпадать при записи и чтении, иначе числа будут "перевернутыми".
Вывод программы
Буфер после записи: [12, 34, 56, 78, cd, ab]
Прочитано num1: 0x12345678
Прочитано num2: 0xABCD
num1 записан как big-endian → 0x12 34 56 78.num2 записан как little-endian → 0xCD AB.- Чтение обратно с правильной эндийностью даёт точные значения.
|
|
|
|
|
Представление байтов
u8 — базовый тип для одного байта.[u8] — срез байтов.Vec<u8> — динамический буфер байтов.&[u8] часто используется для передачи данных в API (например, чтение файлов, сокеты).
|
Конвертация строк ↔ байты
fn main(){
let s = String::from("hello");
let bytes = s.into_bytes(); // Vec
}
fn main(){
let s = "hello";
let bytes = s.as_bytes();
}
fn main(){
let bytes = vec![104, 101, 108, 108, 111]; // "hello"
let s = String::from_utf8(bytes).unwrap();
}
Чтение и запись байтов
fn main(){
use std::fs;
let data = fs::read("file.bin")?; // Vec
fs::write("file.bin", &data)?;
}
fn main(){
use std::net::TcpStream;
use std::io::{Read, Write};
let mut stream = TcpStream::connect("example.com:80")?;
stream.write_all(b"GET / HTTP/1.0\r\n\r\n")?;
let mut buf = [0u8; 512];
let n = stream.read(&mut buf)?;
println!("Read {} bytes", n);
}
|
|
|
fn main(){
let b: u8 = 0b1010_1100;
let mask = 0b0000_1111;
let lower_nibble = b & mask; // 0b00001100
// ------------------------------------
let a = 80;
let b = 2;
// деление >>
assert_eq!(80/(2*2) , a >> b);//20
// умножение <<
assert_eq!(80*(2*2) , a << b);//320
// сумма |
assert_eq!(80+2 , a | b);
assert_eq!(80+2 , a ^ b);
}
fn main(){
// & (Побитовое И (AND))
println!("0011 И 0101 будет {:04b}", 0b0011u32 & 0b0101);
// | (Побитовое ИЛИ (OR))
println!("0011 ИЛИ 0101 будет {:04b}", 0b0011u32 | 0b0101);
// ^ (Исключающее ИЛИ (XOR))
println!("0011 исключающее ИЛИ 0101 будет {:04b}", 0b0011u32 ^ 0b0101);
// << (Побитовый сдвиг влево)
println!("1 << 5 будет {}", 1u32 << 5);
let x: u8 = 1 << 3; // 0b00001000
// >> (Побитовый сдвиг вправо)
println!("0x80 >> 2 будет 0x{:x}", 0x80u32 >> 2);
}
fn main(){
let mut data = vec![1, 2, 3];
data.extend_from_slice(&[4, 5]);
}
|
|
Подмножества через битовые маски (bit masks)
|
Кодирование подмножества в число, в представлении на двоичном уровне каждый бит соответствует одному подмножеству.
В итоге получаем последовательность бит {010}, {110}, ... как множество и теперь мы можем выполнять над ним различные операции: принадлежность, пересечение, объединение, разность, симметрическая разность.
Если у нас есть множество из n элементов:
S = [a, b, c]
А мы знаем, что количество подмножеств будет 2ⁿ (n = количество элементов) т.е. для множества из n=3 подмножеств 2³=8
Вот все 8 вариантов подмножеств и мы можем каждое подмножество закодировать как число от 0 до 2ⁿ-1 в двоичной форме:
| Маска | Биты | Подмножество |
|---|
| 0 | 000 | {} |
| 1 | 001 | {c} |
| 2 | 010 | {b} |
| 3 | 011 | {b,c} |
| 4 | 100 | {a} |
| 5 | 101 | {a,c} |
| 6 | 110 | {a,b} |
| 7 | 111 | {a,b,c} |
Т.е. каждый бит отвечает за включение элемента в подмножество.
...
001 -> ["A"]
010 -> ["B"]
011 -> ["A", "B"]
100 -> ["C"]
101 -> ["A", "C"]
110 -> ["B", "C"]
111 -> ["A", "B", "C"]
...
Маска сама кодирует, какие элементы выбраны:
mask = 5 = 101 → биты 1 и 3 включены → подмножество [A, C]
mask = 3 = 011 → биты 1 и 2 включены → [A, B]
1. Установка бит
Например текущее состояние системы отображено такой маской 1=001={c}.
Мы хотим изменить состояние и добавить функционал 4=100={a} и 2=010={b} что бы получилось 7=111={a,b,c}.
Для установки (включения) бита в определенной позиции применяется операция OR (|):
1 | 4 | 2 = 7=111={a,b,c}
2. Снятие бит
Если же мы хотим снять бит с позиции т.е. забрать возможность, выключить функционал ... применяем операцию AND (&) с инвертированием (~) вычитаемого.
Заберем 2=010={b} с текущего состояния 7=111={a,b,c}
7 & (~2) = 5=101={a,c}
3. Переключение битов
Переключение битов операцией (^), установит если был снят и снимит если был установлен. Применим к текущему состоянию снова функционал 2=010={b}
5^2=7=111={a,b,c} // т.е. установили b так как он был снят
4. Проверка значения бита
Применям операцию AND (&). Проверим установлены ли все биты в текущем состоянии для функционала 3=011={b,c}
7 & 3 != 0
т.е. для того чтобы выражение (7 & 3) было истинным, необходимо, чтобы все установленные биты второго операнда (3) совпали с установленными битами первого операнда (7).
fn main() {
// 1. Установка битов
let mut state = 1;
println!("state={} биты={:03b}", state, state);// state=1 биты=001
state |=4;
state |=2;
println!("state={} биты={:03b}", state, state);// state=7 биты=111
// 1 | 4 | 2 = 7=111={a,b,c}
// 2. Снятие битов
state &=!2;
println!("state={} биты={:03b}", state, state);// state=5 биты=101
// 7 & (~2) = 5=101={a,c}
// 3. Переключение битов (toggle если был 1 станет 0, иначе если был 0 станет 1)
state ^= 2;
println!("state={} биты={:03b}", state, state);// state=7 биты=111
// 4. Проверка значения бита
if ((state & 3) != 0){
println!("бит установлен"); // бит установлен
}else{
println!("бит снят");
}
}
fn main() {
let elements = ["a", "b", "c"];
let n = elements.len();
for mask in 0..(1 << n) {
let subset: Vec<_> = (0..n)
.filter(|i| (mask & (1 << i)) != 0)
.map(|i| elements[i])
.collect();
println!("mask={} биты={:03b} -> {:?}", mask, mask, subset);
}
println!("\n\n");
let mask_x = 5; // = {a, c} = 101₂
let mask_y = 6; // = {b, c} = 110₂
// Пересечение (intersection)
let mut mask = mask_x & mask_y; // 4 = 100₂ = {c}
println!("mask={} биты={:03b}", mask, mask);
// Объединение (union)
mask = mask_x | mask_y; // 7 = 111₂ = {a, b, c}
println!("mask={} биты={:03b}", mask, mask);
// Разность множеств
mask = mask_x & (!mask_y);// 1 = 001₂ = {a}
println!("mask={} биты={:03b}", mask, mask);
// Симметрическая разность (xor)
mask = mask_x ^ mask_y;// 3 = 011₂ = {a, b}
println!("mask={} биты={:03b}", mask, mask);
// Легко проверять наличие элемента. Проверка принадлежности одного элемента
// Пусть mask = 5 = 101₂ = {a, c}
mask = 5;
// 1. Проверим, входит ли: a (установленный бит на позиции 0 в 001₂):
let mut position = 0;
let is_a = mask & (1 << position) != 0; // true
println!("Для множества mask={} биты={:03b} является ли множество a=001 его подмножеством? Ответ: {}", mask,mask, is_a);
// 2. Проверим, входит ли: b (установленный бит на позиции 1 в 010₂):
position = 1;
let is_a = mask & (1 << position) != 0; // false
println!("Для множества mask={} биты={:03b} является ли множество b=010 его подмножеством? Ответ: {}", mask,mask, is_a);
// 3. Проверим, входит ли: c (установленный бит на позиции 2 в 100₂):
position = 2;
let is_a = mask & (1 << position) != 0; // true
println!("Для множества mask={} биты={:03b} является ли множество с=100 его подмножеством? Ответ: {}", mask,mask, is_a);
// Проверка принадлежности подмножества
let mut subset = 6;// 110 {b, c}
println!("Для множества mask={} биты={:03b} является ли множество subset={} биты={:03b} его подмножеством? Ответ: {}",mask,mask, subset, subset, contains_subset(mask, subset));// flase
}
fn contains_subset(set: u32, subset: u32) -> bool {
(set & subset) == subset
}
|
|
Пример работы с маской
Таблица цветов (3 бита: R, G, B)
| R | G | B | Цвет |
|---|
| 0 | 0 | 0 | Черный |
| 0 | 0 | 1 | Синий |
| 0 | 1 | 0 | Зеленый |
| 0 | 1 | 1 | Голубой |
| 1 | 0 | 0 | Красный |
| 1 | 0 | 1 | Пурпурный |
| 1 | 1 | 0 | Желтый |
| 1 | 1 | 1 | Белый |
|
// Компактная версия с битовыми флагами
use std::fmt;
#[repr(u8)]
#[derive(Clone, Copy)]
enum ColorMask {
Red = 0b100,
Green = 0b010,
Blue = 0b001,
}
#[derive(Clone, Copy)]
struct SimpleColor(u8);
impl SimpleColor {
const NAMES: [&'static str; 8] = [
"Черный", "Синий", "Зеленый", "Голубой",
"Красный", "Пурпурный", "Желтый", "Белый"
];
fn new() -> Self {
SimpleColor(0)
}
// Создание цвета с компонентами (исправленная версия)
fn from_components(red: bool, green: bool, blue: bool) -> Self {
let mut color = SimpleColor::new();
color.set(ColorMask::Red, red);
color.set(ColorMask::Green, green);
color.set(ColorMask::Blue, blue);
color
}
fn set(&mut self, mask: ColorMask, value: bool) {
if value {
self.0 |= mask as u8; // Установить бит
} else {
self.0 &= !(mask as u8); // Сбросить бит
}
}
fn get(&self, mask: ColorMask) -> bool {
(self.0 & mask as u8) != 0
}
fn name(&self) -> &'static str {
SimpleColor::NAMES[self.0 as usize]
}
}
impl fmt::Display for SimpleColor {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "{:03b} ({})", self.0, self.name())
}
}
fn main() {
println!("Минимальный пример:");
// Желтый = Красный + Зеленый
println!("\n=== Создание желтого цвета ===");
// Способ 1: Используя set()
let mut yellow = SimpleColor::new(); // 000
yellow.set(ColorMask::Red, true); // Добавляем красный: 100
yellow.set(ColorMask::Green, true); // Добавляем зеленый: 110
println!("Желтый: {} = {:03b}", yellow.name(), yellow.0); // 110
// Способ 2: Создание сразу с двумя компонентами
let yellow2 = SimpleColor::from_components(true, true, false);
println!("Желтый (через from_components): {}", yellow2);
// Способ 3: Побитовые операции напрямую
let yellow_code = ColorMask::Red as u8 | ColorMask::Green as u8;
let yellow3 = SimpleColor(yellow_code);
println!("Желтый (побитовые операции): {}", yellow3);
// Проверяем наличие компонентов
println!("\n=== Проверка компонентов желтого ===");
println!("Есть красный? {}", yellow.get(ColorMask::Red));
println!("Есть синий? {}", yellow.get(ColorMask::Blue));
println!("Есть зеленый? {}", yellow.get(ColorMask::Green));
// Белый = Красный + Зеленый + Синий
println!("\n=== Создание белого цвета ===");
// Способ 1: Используя set()
let mut white = SimpleColor::new(); // 000
white.set(ColorMask::Red, true); // Добавляем красный: 100
white.set(ColorMask::Green, true); // Добавляем зеленый: 110
white.set(ColorMask::Blue, true); // Добавляем синий: 111
println!("Белый: {} = {:03b}", white.name(), white.0); // 111
// Способ 2: Создание сразу со всеми компонентами
let white2 = SimpleColor::from_components(true, true, true);
println!("Белый (через from_components): {}", white2);
// Способ 3: Побитовые операции напрямую
let white_code = ColorMask::Red as u8 | ColorMask::Green as u8 | ColorMask::Blue as u8;
let white3 = SimpleColor(white_code);
println!("Белый (побитовые операции): {}", white3);
// Все возможные цвета
println!("\n=== Все цвета ===");
for i in 0..8 {
let color = SimpleColor(i);
println!("{}: {}", i, color);
}
// Демонстрация работы с цветом
println!("\n=== Демонстрация изменений ===");
let mut color = SimpleColor::new();
println!("Начальный: {}", color);
color.set(ColorMask::Red, true);
println!("Добавили красный: {}", color);
color.set(ColorMask::Green, true);
println!("Добавили зеленый: {}", color);
color.set(ColorMask::Blue, true);
println!("Добавили синий: {}", color);
color.set(ColorMask::Green, false);
println!("Убрали зеленый: {}", color);
}
|
|
Процесс извлечения группы битов называется маскированием поля (Field Masking)
|
Допустим нам нужны данные которые находятся начиная с позиции 3 и имеют длину 3 бита
Исхожные данные A -> X101XXX
Сдвигаем число A на 3 позиции вправо: A >> 3 -> XXXX101
После сдвига наше поле 101 находится на нужной позиции, но за ним могут следовать другие, более старшие биты из исходного числа
Чтобы изолировать только наше 3-битное поле, мы используем маску точно под наши данные M = 0000111
.....XX101
&
0000111
------------
0000101
fn main() {
// Исходное 8-битное число (u8).
// Двоичное: 01010100 (десятичное 84).
// Поле, которое мы извлекаем (биты 3, 4, 5), это '010'.
let data: u8 = 84;
// --- Параметры Поля ---
const START_POS: u8 = 3; // Начальная позиция поля (индекс 3)
const FIELD_LENGTH: u8 = 3; // Длина поля
// 1. Создание маски: (1 << L) - 1. Для 3 бит это 7 (00000111).
let mask: u8 = (1 << FIELD_LENGTH) - 1;
// 2. Извлечение поля: (data >> START_POS) & MASK
let shifted_data = data >> START_POS;
let extracted_value = shifted_data & mask;
println!("--- Извлечение Поля Битов (Rust) ---");
println!("Исходные данные: {} ({:08b})", data, data);
println!("Позиция начала: {}", START_POS);
println!("Длина поля: {}", FIELD_LENGTH);
println!("Созданная маска: {} ({:08b})", mask, mask);
println!("--------------------------------------");
// Вывод результата: 2 (010).
// (Поле битов 3, 4, 5 числа 84 равно '010').
println!("Извлеченное значение: {} ({:03b})", extracted_value, extracted_value);
}
/*
--- Извлечение Поля Битов (Rust) ---
Исходные данные: 84 (01010100)
Позиция начала: 3
Длина поля: 3
Созданная маска: 7 (00000111)
--------------------------------------
Извлеченное значение: 2 (010)
*/
|
|
|
|
|
& (Побитовое И (AND))
Для проверки
Если оба соответствующих бита операндов равны 1, результирующий двоичный разряд равен 1; если же хотя бы один бит из пары равен 0, результирующий двоичный разряд равен 0.
Логическое И к каждой паре битов, которые стоят на одинаковых позициях в двоичных представлениях операндов
0 0 => 0
1 0 => 0
0 1 => 0
1 1 => 1
|
0011
0101
----
0001
fn main(){
println!("0011 AND 0101 is {:04b}", 0b0011 & 0b0101);// = 0b0001 = 1
println!("{}", 0b0001);
}
|
|
| (Побитовое ИЛИ (OR))
Для наложения масок
Если оба соответствующих бита операндов равны 0, двоичный разряд результата равен 0; если же хотя бы один бит из пары равен 1, двоичный разряд результата равен 1
Логическое ИЛИ к каждой паре битов, которые стоят на одинаковых позициях в двоичных представлениях операндов
0 0 => 0
1 0 => 1
0 1 => 1
1 1 => 1
|
0011
0101
----
0111
fn main(){
println!("0011 OR 0101 is {:04b}", 0b0011 | 0b0101);// = 0b0111 = 7
println!("{}", 0b0111);
}
|
|
^ (Исключающее ИЛИ (XOR))
Для шифрования (симметричное т.е. можно обратно расшифровать тем же)
Исключающее« ИЛИ» (или сложение по модулю 2)
Если оба соответствующих бита операндов равны между собой, двоичный разряд результата равен 0; в противном случае, двоичный разряд результата равен 1.
Результат действия которой равен 1, если число складываемых единичных битов нечётно и равен 0, если чётно.
0 0 => 0
1 0 => 1
0 1 => 1
1 1 => 0
|
0011
0101
----
0110
fn main(){
println!("0011 XOR 0101 is {:04b}", 0b0011 ^ 0b0101); // = 0110 = 6
println!("{}", 0b0110);
// ----------------------------------------------------------
// поменять местами значения переменных без создания временной
let mut x = 9;
let mut y = 5;
let mut temp = x;
x = y;
y = temp;
println!("x={} y={}",x,y);
// или воспользовать побитовой операцией XOR
let mut x = 9;
let mut y = 5;
x = x^y; // первая операция XOR создаст шифр с помощью которого можно расшифровать то или иное значение
y = x^y;
x = x^y;
println!("x={} y={}",x,y);
// Не использовать способ XOR если переменные ссылаются на одну и туже область памяти,иначе затрется значение (актуально для C++)
let mut value:i32 = 9;
let shared:&mut i32 = &mut value;
unsafe {
let x = shared as *mut i32;
let y = shared as *mut i32;
*x = *x^*y;
*y = *x^*y;
*x = *x^*y;
assert_eq!(0,*x);
assert_eq!(0,*y);
}
}
|
|
<< (Побитовый сдвиг влево)
Арифметический сдвиг новые биты нули
|
Интересной особенностью сдвига влево на N позиций является то, что это эквивалентно умножению числа на 2N.
Таким образом, 43<<4 == 43*Math.pow(2,4).
Использование сдвига влево вместо Math.pow обеспечит неплохой прирост производительности.
fn main(){
println!("1 << 1 is {} , {:04b} ", 1 << 1, 1 << 1);// 0010
println!("1 << 2 is {} , {:04b} ", 1 << 2, 1 << 2);// 0100
println!("1 << 3 is {} , {:04b} ", 1 << 3, 1 << 3);// 1000
println!("2 << 1 is {} , {:04b} {:04b} {:04b} ", 2 << 1, 2 << 1,2,1);// 0010 << 0001 = 0100
println!("3 << 1 is {} , {:04b} {:04b} {:04b}", 3 << 1, 3 << 1,3,1);// 0011 << 0001 = 0110
println!("3 << 2 is {} , {:04b} {:04b} {:04b}", 3 << 2, 3 << 2,3,2);// 0011 << 0010 = 1100
println!("3 << 3 is {} , {:04b} {:04b} {:04b}", 3 << 4, 3 << 4,3,4);// 0011 << 4 = 110000
// 3 << 2 эквивалентно 3 * (2*2) т.е. умножение на 2^N
println!("3 << 2 is {:04b} {}, {:04b} ", 3 << 2,3 << 2, 3 * (2*2));// 12
}
Побитовый сдвиг влево на число равное или более числу бит
Запуск в режиме RELEASE:
fn get_k()->i32{10}
fn main() {
let mut a: i8 = 13;
let mut k = get_k();// компилятор не видит константу и не знает что k больше чем число разрядов числа
let result = a << k;
println!("{} {:08b}",result, result); // 52 00110100
assert_eq!(result, 13_i8 << 2);// эквивалентно, сдвиг по модулю 10%8=2
}
еще пример:
#![allow(unused)]
fn main() {
// Для демонстрации добаим allow(arithmetic_overflow) так как компилятор видит константы и сразу понимает что это ошибка
#[allow(arithmetic_overflow)]
/*
Вариант 1 запуск в режиме Debug:
panic: attempt to shift left with overflow
(попытка сдвинуть влево с переполнением)
Вариант 2 запуск в режиме Release:
Программа не упадет. Она сделает сдвиг по модулю:
Число сдвига считается так:
k = 10; то на сколько мы хотели сдвинуть
w - это разряд числа, для u8 это 8, для u16 это 16
k = k % w
*/
let a:u8 = 13; // 0000_1101
let k = 10;
let result = a << k;
println!("{result} binary={:08b}",result); // 52 binary=0011_0100
// эквивалентно
let w = std::mem::size_of_val(&a)*8;
let k = k % w;// 10%8=2
println!("{result}=={} binary={:08b}",a << k, a << k);// 52==52 binary=0011_0100
assert_eq!(13_u8 << 10, 13_u8 << 2);
/*
Безопасные методы сдвига
1.wrapping_shl(10) = 4 Всегда берет остаток (10 % 8 = 2).
1.checked_shl(10)=None Безопасно говорит: «Слишком много».
1.overflowing_shl(10)=(4, true) Возвращает результат и пометку «Да, был перебор».
unwrap_or(0) Если сдвиг слишком большой, мы просто возвращаем ноль.
*/
let k: u32 = 10; // Важно: u32
match a.checked_shl(k) {
Some(res) => println!("checked_shl: {}", res),
None => println!("checked_shl: Ошибка! Сдвиг {} больше или равен разрядности {}", k, w),
}
}
Запуск в режиме DEBUG: (error: this arithmetic operation will overflow)
fn main(){
let a:u8 = 13; // 0000_1101
let k = 10;
let result = a << k;
}
|
|
>> (Побитовый сдвиг вправо)
Rust в режиме Release пропустит сдвиг на число равное или больше чем разрядность самого числа и программа не упадет.
|
Сдвиг числа вправо на N количество позиций также делит это число на 2N. Опять же, это выполняется намного быстрее обычного деления.
fn main(){
println!("0x80 >> 2 is 0x{:x}", 0x80 >> 2);// 0x20
println!("3 >> 1 is {} , {:04b} {:04b} {:04b} ", 3 >> 1, 3 >> 1,1,3);// 0011 >> 0001 = 0001
println!("1 >> 3 is {} , {:04b} {:04b} {:04b} ", 1 >> 3, 1 >> 3,1,3);// 0001 >> 0011 = 0000
// 40 >> 2 эквивалентно 40 / (2*2) т.е. делению на 2^N
println!("40 >> 2 is {:04b} {}, {:04b} ", 40 >> 2,40 >> 2, 40 / (2*2));// 40 >> 2 is 1010 10, 1010
}
В языке C есть проблема для операции >>, в зависимости от компилятора результат будет разный.
При арифметическом сдвиге (чаще всего, слева добавляется старший бит 1) но если логический сдвиг (редко, слева добавляется старший бит 0), что кардинально меняет результат.
В Rust эта проблема решена:
- для i8, i16, i32, i64, i128 — всегда арифметический сдвиг (добавляется слева т.е. в старшую позицию копию старшего бита знака 0 или 1)
- для u8, u16, u32, u64, u128 — всегда логический сдвиг (добавляется слева т.е. старший бит 0 всегда)
У знаковых типов, старший бит в начале отведен для представления знака + или -. При чем для + значение 0, а для - значение 1.
Типы со знаком:
0b00000000 = 0 (для знаковых и беззнаковых одинаково)
0b00000101 = +5 (старший бит 0)
0b10000101 = -123 (старший бит 1)
0b01111111 = +127 (максимальное положительное)
0b10000000 = -128 (минимальное отрицательное)
0b10000000 = 128 (для типа без знака)
fn get_k()->u32{10}
fn main() {
let x: i8 = -8;
let result = x >> 1;
println!("{} >> 1 = {result} binary={:08b}", x, result); // -4 (всегда арифметический сдвиг) 11111100
// В языке C может быть логический сдвиг: 8 >> 1 = 124 (добавляется 0 слева) 01111100
let y: u8 = 0xFF; // 255
let result: u8 = y >> 1;
println!("{} >> 1 = {result} binary={:08b}", y, result); // 127 (всегда логический) 01111111
// Пример переполнения, сдвиг на больше или равное чем число разрядов числа
{
let x: u8 = 5;
let k = get_k();// компилятор не видит константу поэтому пропускает проверку того что слвиг больше чем разряд числа
let result = x << k;
println!("{result} binary={:08b}",result); // 20 binary=00010100
/*
Сдвиг по модулю
k = 10; то на сколько мы хотели сдвинуть
w - это разряд числа, для u8 это 8, для u16 это 16
k = k % w
k = 10 % 8 = 2
*/
assert_eq!(result, 5_u8 << 2); // эквивалентно сдвигу на 2
}
}
|
|
Вычитание, cложение, умножение, деление через битовые операции
|
// a - b = a + (!b + 1)
fn subtract(a: i32, b: i32) -> i32 {
a + !b + 1
}
fn main() {
// Вычитание
println!("5 - 3 = {}", 5 + !3 + 1); // 2
println!("5 - 3 = {}", subtract(5, 3)); // 2
// Сложение
println!("5 + 3 = {}", (5 ^ 3) + ((5 & 3) << 1)); // 8
// Умножение (5 * 3 = 5 + 5 + 5)
println!("5 * 3 = {}", (5 << 1) + (5 << 0)); // 15
// Деление (грубо, только для степеней двойки)
println!("8 / 2 = {}", 8 >> 1); // 4
}
Битовый операции, но над строками
fn main(){
let a = "hello";
let b = "bay";
// В байты
let a_bytes: Vec<u8> = a.bytes().collect();
let b_bytes: Vec<u8> = b.bytes().collect();
// Вычитание: a_bytes XOR b_bytes
let sub_bytes: Vec<u8> = a_bytes.iter()
.zip(b_bytes.iter().cycle())
.map(|(x, y)| x ^ y)
.collect();
// Умножение: a_bytes AND b_bytes
let mul_bytes: Vec<u8> = a_bytes.iter()
.zip(b_bytes.iter().cycle())
.map(|(x, y)| x & y)
.collect();
// Сложение: a_bytes OR b_bytes
let add_bytes: Vec<u8> = a_bytes.iter()
.zip(b_bytes.iter().cycle())
.map(|(x, y)| x | y)
.collect();
// Обратно в строку (если возможно)
let sub = String::from_utf8_lossy(&sub_bytes);
let mul = String::from_utf8_lossy(&mul_bytes);
let add = String::from_utf8_lossy(&add_bytes);
println!("a: {:?}", a_bytes);
println!("b: {:?}", b_bytes);
println!("a - b (XOR): {:?} = '{}'", sub_bytes, sub);
println!("a * b (AND): {:?} = '{}'", mul_bytes, mul);
println!("a + b (OR): {:?} = '{}'", add_bytes, add);
}
|
|
Интерпретация байтов как числа
|
Используются методы из std::convert и byteorder:
fn main(){
let bytes: [u8; 4] = [0x78, 0x56, 0x34, 0x12];
let num = u32::from_le_bytes(bytes); // little-endian -> 0x12345678
}
|
|
|
|
|
|
inplace swap
В отличие от обычной методики перестановки двух значений, здесь нет необходимости в третьей ячейке для временного хранения одного из значений на время перемещения другого.
fn main() {
// В качестве примера применимости свойства `a ^ a = 0` к любому битовому вектору a рассмотрим следующую программу:
// inplace_swap
let mut a = 5;
let mut b = 88;
println!("a={:08b} b={:08b}",a,b);// a=00000101 b=01011000
/*
Шаг 1 смесь (a ⊕ b)
по сути это создание маски из которой можно последовательно доставать либо первую либо вторую составляющую часть
*/
b = a ^ b;
println!("a={:08b} b={:08b}",a,b);// a=00000101 b=01011101
/*
Шаг 2 итоговое значение для a
подстановка из Шага 1:
a = a ^ b = a ^ (a ^ b) =>
далее свойство ассоциативности:
=> (a ^ a) ^ b =>
далее свойство самообратимости: a ^ a = 0:
=> 0 ^ b =>
далее свойство нейтральный элемент: 0 ^ b = b:
=> a = b
*/
a = a ^ b;
println!("a={:08b} b={:08b}",a,b);// a=01011000 b=01011101
/*
Шаг 3 итоговое значение для b
подстановка b из Шага 1 и a из Шага 2:
b = a ^ b = a ^ (a ^ b) =>
коммутативность во второй скобке:
=> b ^ (b ^ a)
ассоциативность:
=> (b ^ b) ^ a
самообратимость (b ^ b = 0):
=> 0 ^ a
нейтральный элемент (0 ^ a = a):
=> a
итог: b получает значение a
*/
b = a ^ b;
println!("a={:08b} b={:08b}",a,b);// a=01011000 b=00000101
println!("a={a} b={b}");// a=88 b=5
// p.s. такой способ не дает выигрыша в производительности; выигрыш имеет место лишь в форме интеллектуального развлечения.
}
|
|
|
|
|
crates bytemuck и zerocopy предоставляют удобные инструменты для работы с низкоуровневыми операциями над данными, где требуется преобразование структур в массивы байт и обратно, минимизируя накладные расходы и избегая копирования данных.
|
crate bytemuck — это crate, который предоставляет безопасные и удобные средства для преобразования между Rust-типами и массивами байт (byte slices). Этот crate ориентирован на производительность и простоту.
use bytemuck::{Pod, Zeroable};
#[repr(C)]
#[derive(Clone, Copy, Pod, Zeroable)]
struct MyStruct {
a: u32,
b: f32,
}
fn main() {
let my_data = MyStruct { a: 42, b: 3.14 };
// Преобразование структуры в байтовый массив
let bytes: &[u8] = bytemuck::cast_slice(&[my_data]);
println!("{:?}", bytes);
// Обратное преобразование
let restored: &[MyStruct] = bytemuck::cast_slice(bytes);
println!("{:?}", restored[0]);
}
crate zerocopy также предназначен для преобразования структур в массивы байт и обратно, но с акцентом на безопасное взаимодействие с буферами без копирования. Его основное отличие — более богатая функциональность и использование черт для безопасного чтения данных из байтового представления.
use zerocopy::{AsBytes, FromBytes, Unaligned};
#[repr(C)]
#[derive(AsBytes, FromBytes, Unaligned)]
struct MyStruct {
a: u32,
b: f32,
}
fn main() {
let my_data = MyStruct { a: 42, b: 3.14 };
// Преобразование структуры в байтовый массив
let bytes = my_data.as_bytes();
println!("{:?}", bytes);
// Обратное преобразование из массива байт
let restored = MyStruct::read_from(bytes).unwrap();
println!("a: {}, b: {}", restored.a, restored.b);
}
|
|
crate intbits
Упрощает работу с битами: вместо сложных битовых операций (&, |, <<, >>) вы получаете читаемые и интуитивные методы.
Полезно при разработке бинарных протоколов, работе с оборудованием, парсинге масок и флагов.
Универсально для любых целочисленных типов (u8, u16, u32, и т. д.), благодаря трейту Bits.
|
Сравним два подхода: ручные маски/сдвиги и использование intbits.
Пример задачи
Допустим, у нас есть u32, и мы хотим:
- Проверить, установлен ли бит на позиции
5.
- Извлечь диапазон битов
[8..12) (4 бита).
- Установить бит на позиции
3 в false.
- Заменить диапазон
[16..20) значением 0b1010.
Ручные маски и сдвиги
fn main() {
let x: u32 = 0b1011_0000_1111_1111;
// 1. Проверить бит 5
let bit5 = (x >> 5) & 1 == 1;
// 2. Извлечь биты 8..12
let range_8_12 = (x >> 8) & 0b1111;
// 3. Установить бит 3 в false
let cleared_bit3 = x & !(1 << 3);
// 4. Заменить диапазон 16..20 на 0b1010
let mask = !(0b1111 << 16);
let replaced = (x & mask) | (0b1010 << 16);
println!("bit5={bit5}, range_8_12={range_8_12:b}, cleared_bit3={cleared_bit3:b}, replaced={replaced:b}");
}
Проблемы:
- Нужно помнить приоритеты операторов
<<, >>, &, |, !.
- Много ручных масок
0b1111 и сдвигов.
- Ошибки с off-by-one очень легко допустить.
С использованием intbits
use intbits::Bits;
fn main() {
let x: u32 = 0b1011_0000_1111_1111;
// 1. Проверить бит 5
let bit5 = x.bit(5);
// 2. Извлечь биты 8..12
let range_8_12 = x.bits(8..12);
// 3. Установить бит 3 в false
let cleared_bit3 = x.with_bit(3, false);
// 4. Заменить диапазон 16..20 на 0b1010
let replaced = x.with_bits(16..20, 0b1010);
println!("bit5={bit5}, range_8_12={range_8_12:b}, cleared_bit3={cleared_bit3:b}, replaced={replaced:b}");
}
Преимущества:
- Нет ручных масок → меньше шансов ошибиться.
- Код читается "по-человечески":
.bit(5), .bits(8..12).
- Никаких возни с
<< и &.
В реальных проектах (сетевые протоколы, бинарные форматы, регистры микроконтроллеров) читаемость и снижение риска ошибок очень важны, поэтому intbits реально экономит нервы.
|
|
crate bitflags
Предоставляет удобный способ работы с набором флагов (битовых значений), используя типо-безопасный интерфейс. Это особенно полезно при работе с API или системами, где состояния, настройки или параметры кодируются в виде битовых масок.
example_generated/Flags
|
use bitflags::bitflags;
// Определяем набор флагов
bitflags! {
struct Permissions: u32 {
const READ = 0b0001; // Бит 0
const WRITE = 0b0010; // Бит 1
const EXECUTE = 0b0100; // Бит 2
const DELETE = 0b1000; // Бит 3
}
}
fn main() {
// Устанавливаем начальные права
let mut user_permissions = Permissions::READ | Permissions::WRITE;
// Проверяем наличие флага
if user_permissions.contains(Permissions::READ) {
println!("User can read.");
}
// Добавляем право на выполнение
user_permissions.insert(Permissions::EXECUTE);
// Убираем право на запись
user_permissions.remove(Permissions::WRITE);
// Переключаем право на удаление
user_permissions.toggle(Permissions::DELETE);
// Печатаем результат
println!("Permissions: {:?}", user_permissions);
// Проверяем комбинацию флагов
if user_permissions.contains(Permissions::READ | Permissions::EXECUTE) {
println!("User has read and execute permissions.");
}
}
|
|
сrate bitmask предоставляет удобный способ создания структур и перечислений для работы с битовыми флагами в Rust. С помощью макроса bitmask! можно автоматически генерировать структуру, которая инкапсулирует битовые флаги, и перечисление, содержащее все возможные флаги.
|
В этом примере создается структура MyMask с типом u8, которая инкапсулирует битовую маску.
Перечисление MyFlags содержит флаги FlagA, FlagB и FlagC.
Методы set и get позволяют устанавливать и проверять значения соответствующих флагов.
use bitmask::bitmask;
bitmask! {
pub mask MyMask: u8 where flags MyFlags {
FlagA = 0b00000001,
FlagB = 0b00000010,
FlagC = 0b00000100,
}
}
fn main() {
let mut mask = MyMask::new();
mask.set(MyFlags::FlagA, true);
mask.set(MyFlags::FlagB, false);
println!("Mask: {:08b}", mask.bits);
println!("FlagA is set: {}", mask.get(MyFlags::FlagA));
println!("FlagB is set: {}", mask.get(MyFlags::FlagB));
}
|
|
crate bytes — это высокоэффективная библиотека для работы с байтовыми буферами в Rust, особенно полезная при разработке сетевых приложений, парсеров и асинхронных систем.
|
use bytes::{BytesMut, BufMut};
fn main() {
let mut buf = BytesMut::with_capacity(1024);
buf.put(&b"hello world"[..]);
buf.put_u16(1234);
let a = buf.split();
assert_eq!(a, b"hello world\x04\xd2"[..]);
buf.put(&b"goodbye world"[..]);
let b = buf.split();
assert_eq!(b, b"goodbye world"[..]);
assert_eq!(buf.capacity(), 998);
}
|
|
|
|
|
|
8 бит начиная с нулевого = 1 десятичной и далее .... вот 1,2,4,8,16,32,64,128,255
0000.0001 это 1 в десятичной
0000.0110 это 6 в десятичной, состоит из 010=2 и 100=4 =>2+4=6
0000.0111 это 7 в десятичной, состоит из 001=1 и 010=2 и 100=4 =>1+2+4=7
0000.1000 это 8
0001.0000 это 16
1000.0000 это 128
1000.0001 это 129
1111.1111 это 255 поместились в 8 бит информации т. е. байт (u8)
100000000 это 256 тут мы не помещаемся в 8 бит поэтому тут 9 бит (ближайший тип данных u16 т.е. 16 битный)
|
|
Шестнадцатеричная система используется для уменьшения занимаемого места в памяти, для информации в один байт т.е. 8 бит значения от 0-255 в десятичной системе, а в шестнадцатеричной два символа, 255 это ff
|
Десятичная 255 в двоичной будет 1111.1111 в шестнадцатеричной FF т.е. двоичный байт состоит из двух пар по 4 бита и кодируется в шестнадцатеричной системе двумя цифрами что можно увидеть открыв бинарный файл в редакторе. Поэтому шестнадцатеричная и двоичная хорошо совместимы F = 1111 битам
|
|
|
Формат вывода двоичного представления:
{:04b} с ведущими нулями, число из 4 цифр{:#b} вывод числа в двоичном представлении
fn main(){
let x = 42; // 42 is '101010' in binary
println!("{:b}", x);// 101010
println!("{:#b}", x);// 0b101010
// добавлением нулей слева для заполнения 8 позиций.
println!("{:08b} {:08b}",1_u8,1_i8);// 00000001 00000001
println!("{:016b} {:016b}",1_u16,1_i16);// 0000000000000001 0000000000000001
}
Перевод числа в двоичное представление
Временная сложность алгоритма - логарифмическая O(log N), каждая итерация сокращает вдвое количество элементов/значение
fn algo_2(mut decimal:u8) -> Option{
if decimal == 0 {return None;}
let mut binary = String::from("");
while decimal > 0 {
binary = format!("{}{}",decimal%2,binary);
decimal = decimal.div_floor(2);
}
Some(binary)
}
fn main(){
println!("{:?}",algo_2(254_u8)); // Some("11111110")
}
|
|
|
Перевод из двоичной в десятичную 8 байтное знаковое число (-128 - 127)
Десятичная система 6n*(10^n-1)
125 = 1*(1*10^2) + 2*(10^1) + 5*(10^0) = 100 + 20 + 5
Двоичная система 1n*(2^n-1)
1111101 = 1*(2^6) + 1*(2^5) + 1*(2^4) + 1*(2^3) + 1*(2^2) + 0*(2^1) + 1*(2^0) = 64+32+16+8+4+0+1 = 125
Разложим 125:
125/2 = 62, остаток 1
62/2 = 31, остаток 0
31/2 = 15, остаток 1
15/2 = 7, остаток 1
7/2 = 3, остаток 1
3/2 = 1, остаток 1
1/2 = 0, остаток 1
Итог собрать с конца: 1111101
И добавить до размера 8 байт: 01111101
Перевод отрицательных чисел
Здесь нужно учесть, что число будет представлено в дополнительном коде.
Для перевода числа в дополнительный код нужно знать конечный размер числа, то есть во что мы хотим его вписать — в байт, в два байта, в четыре.
Старший разряд числа означает знак. Если там 0, то число положительное, если 1, то отрицательное.
Перевод числа со знаком в двоичную систему:
Для перевода отрицательного числа в двоичный используют подход - дополнительный код еще его называют дополнением до двух (Two’s complement). Так как сперва дополнение до 1 при реверсе, а потом еще дополнение до 1 при прибавлении 1
Шаги:
- перевести положительное число в двоичную систему
- потом поменять нули на единицы и единицы на нули
- затем прибавить к результату 1
Для -125
- положительное в двоичной: 01111101
- реверс : 10000010
- прибавить 1 : 10000011
Можно проверить:
- 256 - 125 = 131 в двоичном виде 10000011 что соответствует двоичному представлению для отрицательно числа -125
fn main(){
println!("i8 min={} max={}",i8::min_value(),i8::max_value());
println!("binary -128={:08b}",-128_i8);// -128=10000000
println!("binary -127={:08b}",-127_i8);// -127=10000001
println!("binary -125={:08b}",-125_i8);// -125=10000011
println!("binary -126={:08b}",-126_i8);// -126=10000010
println!("binary -100={:08b}",-100_i8);// -100=10011100
println!("binary -1={:08b}", -1_i8);// -1=11111111
println!("binary 0={:08b}", 0_i8);// 0=00000000
println!("binary 1={:08b}", 1_i8);// 1=00000001
println!("binary 2={:08b}", 2_i8);// 2=00000010
println!("binary 10={:08b}", 10_i8);// 10=00001010
println!("binary 100={:08b}", 100_i8);// 100=01100100
println!("binary 125={:08b}", 125_i8);// 125=01111101
println!("binary 126={:08b}", 126_i8);// 126=01111110
println!("binary 127={:08b}", 127_i8);// 127=01111111
}
|
|
Книга "Rust in action" 5 part, McNamara
42.42
01000010001010011010111000010100
|
«Сдвиг вправо» (п >> м), где n и m - целые числа. Эта операция перемещает биты вправо и заполняет теперь пустые левые биты нулями.
Новое значение теперь можно интерпретировать как целое число. Этот метод используется для разделения знакового бита и мантиссы.
«И маска» (н & м). Эта операция используется как фильтр. Это позволяет вам выборочно выбирать, какие биты следует сохранить, регулируя m в соответствии с требованиями.
"Левый сдвиг" (п << м), обычно равняется 1. Эта операция используется для созданиям значение для последующей маски AND. То есть мы будем динамически создавать фильтры, чтобы изолировать отдельные биты по мере выполнения программы.
use std::mem;
const BIAS: i32 = 127;
const RADIX: f32 = 2.0;
fn main() {
let n: f32 = 42.42;
let (signbit, exponent, fraction) = deconstruct_f32(n);
let (sign, exponent, mantissa) = decode_f32_parts(signbit, exponent, fraction);
let reconstituted_n = f32_from_parts(sign, exponent, mantissa);
// 42.42 -> [sign:0, exponent:32, mantissa:1.325625] -> 42.42
println!("{} -> [sign:{}, exponent:{}, mantissa:{:?}] -> {}",
n,
signbit,
exponent,
mantissa,
reconstituted_n);
}
fn deconstruct_f32(n: f32) -> (u32, u32, u32) {
let n_: u32 = unsafe { std::mem::transmute(n) };
let sign = (n_ >> 31) & 1;
let exponent = (n_ >> 23) & 0xff;
let fraction = 0b00000000_01111111_11111111_11111111 & n_;
(sign, exponent, fraction)
}
fn f32_from_parts(sign: f32, exponent: f32, mantissa: f32) -> f32 {
sign * exponent * mantissa
}
fn decode_f32_parts(sign: u32, exponent: u32, fraction: u32) -> (f32, f32, f32) {
let signed_1 = (-1.0_f32).powf(sign as f32);
let exponent = (exponent as i32) - BIAS;
let exponent = RADIX.powf(exponent as f32);
let mut mantissa: f32 = 1.0;
for i in 0..23_u32 {
let one_at_bit_i = 1 << i;
if (one_at_bit_i & fraction) != 0 {
mantissa += 2_f32.powf((i as f32) - 23.0);
}
}
(signed_1, exponent, mantissa)
}
|
|
|
|
|
|
Полезные инструменты в Rust для упаковки битов/байтов
intbits crate — удобное API для работы с отдельными битами и диапазонами битов (.bit(), .bits(), .with_bit(), .with_bits()).bitvec crate — мощная библиотека для работы с массивами битов, битовыми срезами и итераторами.byteorder crate — полезно, когда нужно упаковывать числа в определённом порядке байт для передачи по сети или записи в файл.
Когда применяется
- Сетевые протоколы (например, TCP/IP, MQTT) — пакуем поля в конкретный размер битов.
- Файловые форматы (BMP, PNG, MP3) — где структура строго задаётся битами и байтами.
- Встраиваемые системы и микроконтроллеры — экономим память и соответствуем аппаратным регистрам.
- Сжатие данных — bit packing используется для уменьшения объёма (например, run-length encoding).
|
|
Упаковка байтов (Byte Packing)
Идея: несколько полей данных помещаются в последовательность байтов без «пустого» пространства между ними.
|
#[repr(C, packed)]
struct Packed {
a: u16, // 2 байта
b: u32, // 4 байта
}
#[repr(C, packed)] убирает выравнивание (padding), которое обычно добавляется компилятором.- Полезно для работы с бинарными протоколами или аппаратурой, где структура должна точно соответствовать формату.
- Минус: доступ к полям может быть медленнее на некоторых архитектурах из-за выравнивания.
|
|
Упаковка битов (Bit Packing)
Идея: данные, которые занимают меньше чем один байт (например, булевы флаги, маленькие числа), упаковываются в один или несколько байтов.
|
Пример (упаковка нескольких флагов в один u8):
- Можно хранить до 8 булевых флагов в одном байте.
- Экономит память при большом количестве небольших значений.
struct Flags {
bits: u8,
}
impl Flags {
fn new() -> Self {
Flags { bits: 0 }
}
fn set(&mut self, pos: u8, value: bool) {
if value {
self.bits |= 1 << pos;
} else {
self.bits &= !(1 << pos);
}
}
fn get(&self, pos: u8) -> bool {
(self.bits >> pos) & 1 == 1
}
}
fn main() {
let mut f = Flags::new();
f.set(0, true);
f.set(3, true);
println!("Bits: {:08b}", f.bits); // 00001001
println!("Bit 3? {}", f.get(3)); // true
}
|
|
|
|
|
crate serde + crate bincode — сериализация структур в бинарный формат
Это удобно для хранения данных или передачи по сети, когда важен компактный размер и скорость.
|
Советы по использованию
- Компактность: Bincode хранит целые числа и строки в минимальном формате.
- Сетевые протоколы: Bincode отлично подходит для обмена данными между Rust-приложениями, если обе стороны используют один и тот же формат.
- Версионирование: для стабильного бинарного формата следует быть осторожным при изменении структур (например, добавлении новых полей).
- Поддержка
no_std: Serde и Bincode можно использовать и в embedded-системах.
use serde::{Serialize, Deserialize};
use bincode;
#[derive(Serialize, Deserialize, Debug, PartialEq)]
struct Person {
name: String,
age: u8,
}
fn main() -> bincode::Result<()> {
let person = Person {
name: "Alice".to_string(),
age: 30,
};
// Сериализация в бинарный формат
let encoded: Vec = bincode::serialize(&person)?;
println!("Бинарные данные: {:?}", encoded);
// Десериализация обратно в структуру
let decoded: Person = bincode::deserialize(&encoded)?;
println!("Десериализованный объект: {:?}", decoded);
assert_eq!(person, decoded);
Ok(())
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|